TAG
Tools tagged "text"
40 tools
General-purpose text utilities: formatting, find-and-replace, counting characters / words / lines, diff, sorting.
All NoSend Tools that carry the "text" tag. Everything runs inside the browser — your inputs never leave your device.
Tags:
Sort:
Per page:
All tools
40 / 40
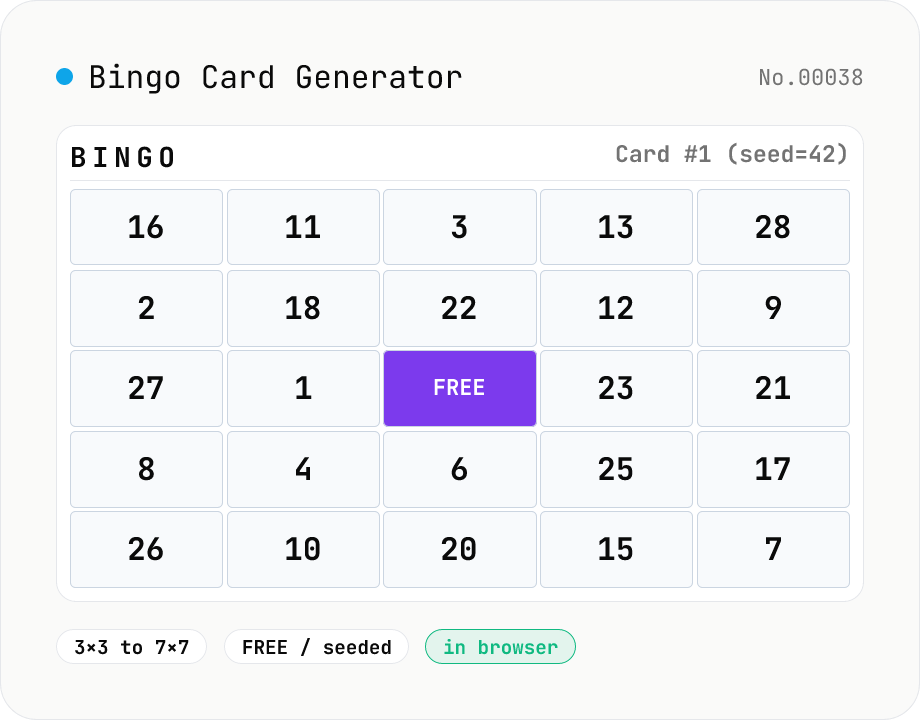
Bingo Card Generator (3×3 to 7×7 + FREE)
Turn a one-item-per-line list (numbers, words, haiku, office jargon, etc.) into N×N (3–7) bingo cards — generate up to 100 cards at once with a single seed for reproducibility. Supports a centre FREE cell (odd sizes only) and TSV export. Perfect for company events, classrooms, conferences, book clubs, and icebreakers.
developertext

Character counter — chars / bytes / lines / words
Count characters, words, lines, paragraphs, and UTF-8 byte size in real time. Toggle whether whitespace and newlines are included. Progress bars show your text against common limits (tweets, 400-character genkō, etc.) — everything stays in your browser.
developertextcount

CSV / text encoding converter — Shift_JIS ↔ UTF-8 / BOM / newlines
Re-encode CSV and text files between Shift_JIS (CP932), UTF-8, UTF-16LE and EUC-JP — fix Excel's mojibake on UTF-8, hand UTF-8 text to legacy systems that need Shift_JIS, or add BOM so Excel reads UTF-8 correctly. Add / remove BOM, swap newlines (CRLF / LF / CR), and auto-detect the input encoding. Batch convert and grab the result as a ZIP. Files never leave your device — everything runs in the browser.
developertextconversion
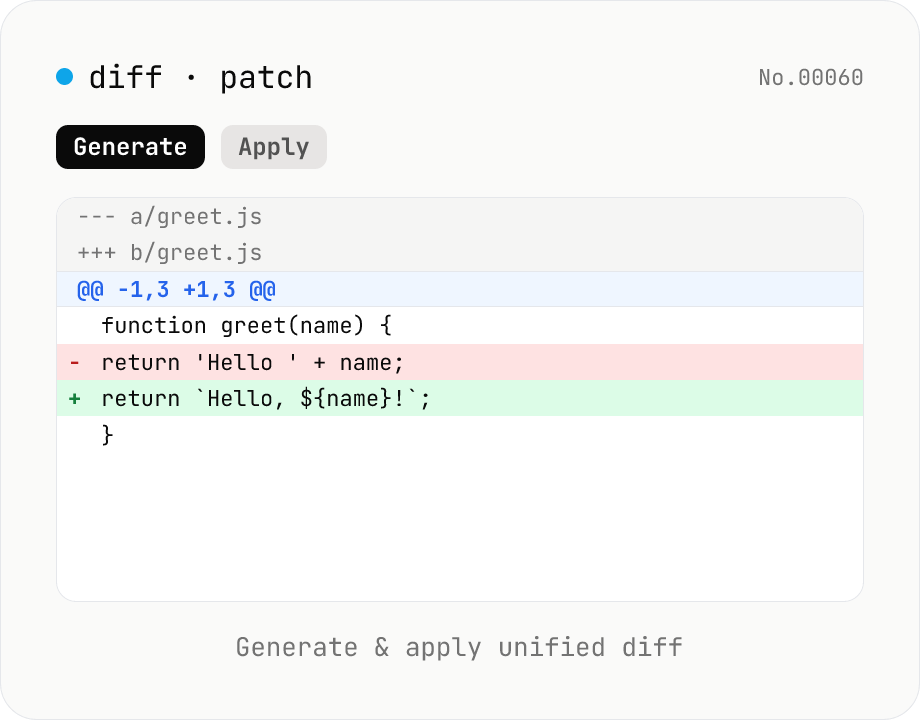
diff / patch — generate and apply unified diff
Produce a unified diff (.patch / .diff) from two texts and apply a unified diff back to the original text. Same format as Git and GNU patch (--- / +++ / @@ hunks), with adjustable context lines and file name. All processing runs in your browser.
developertextdiff
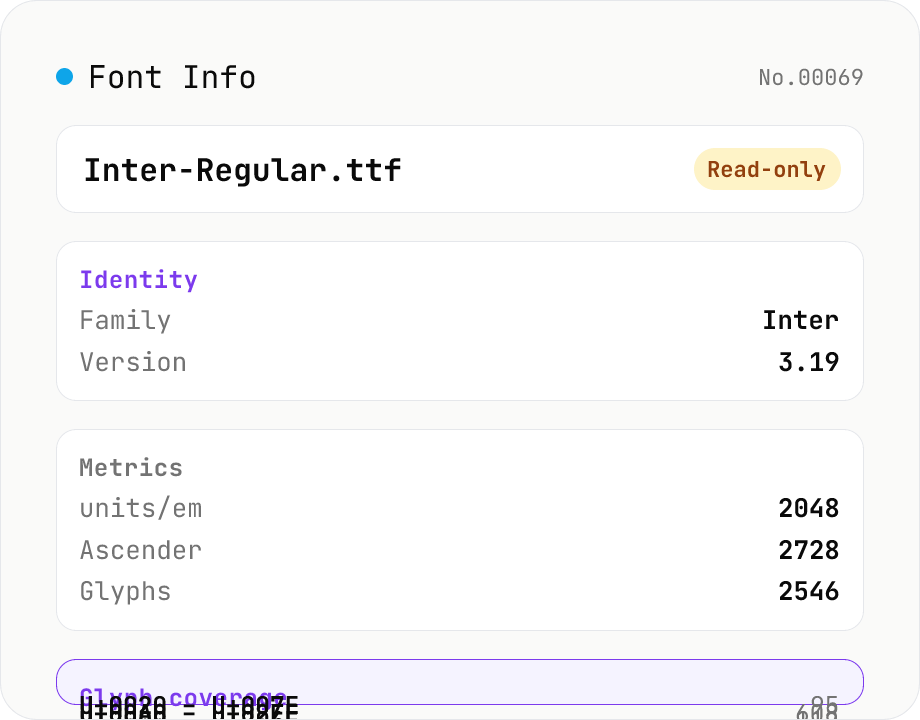
Font Info Viewer
Drop TTF / OTF / WOFF / WOFF2 font files to inspect name, family, version, copyright, license, designer, glyph count, and the Unicode ranges they cover. Read-only, runs entirely in your browser via opentype.js (MIT).
developerextracttext
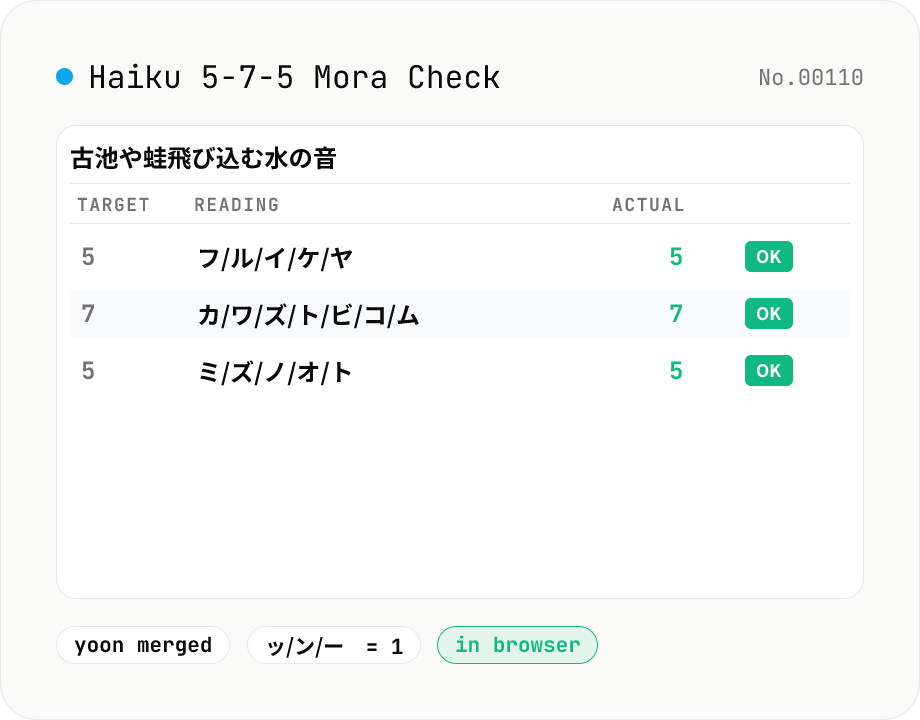
Haiku / Tanka Syllable (mora) Counter
Verify the 5-7-5 (haiku) or 5-7-5-7-7 (tanka) mora pattern with kuromoji morphological analysis. Mixed kanji-kana input is parsed into katakana reading, broken into mora, and each line is checked against the target count — over and under shown line by line. Follows traditional rules: yōon (キョ, シャ etc.) absorbs into the previous mora; sokuon (ッ), hatsuon (ン), and chōonpu (ー) each count as 1.
japanesetext
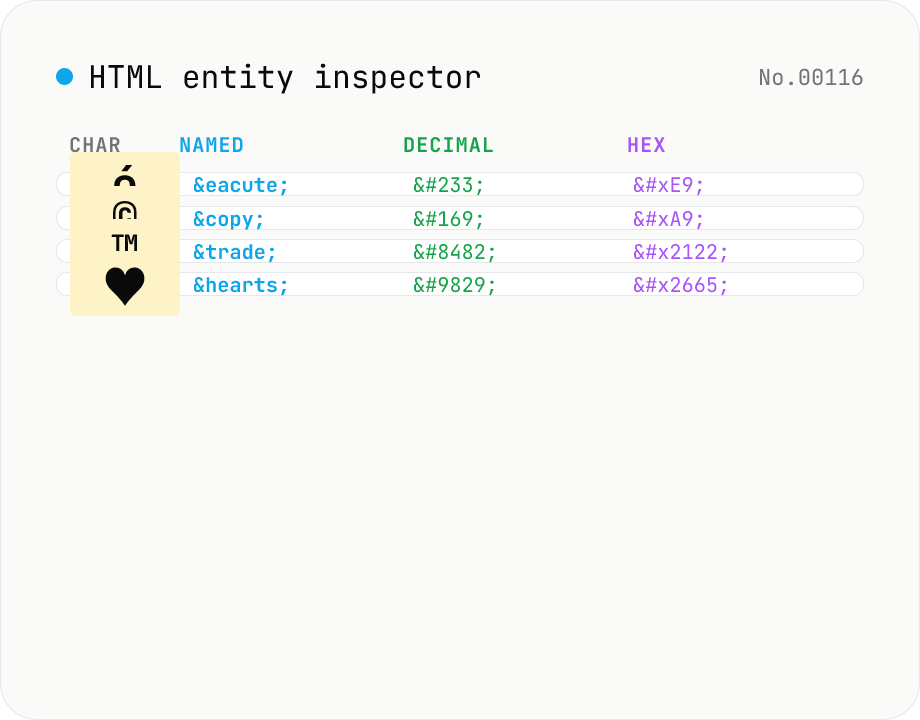
HTML entity inspector — named / decimal / hex / Unicode name side by side
Paste a string containing HTML entities (`&`, `é`, `é`, `é`, ` `, `©`, etc.) and get a table of every entity it contains, listing the **decoded character / named entity / decimal numeric / hex numeric / Unicode code point**. Reverse lookup also works: type `é` and the tool shows `é`, `é` and `é` at once. All 2125 named entities defined in the HTML5 spec are bundled (from `&` through `∳`). Fills the gap between `html-encode` (bulk encode / decode) and `unicode-inspect` (per-codepoint detail) — perfect for "what's the name for this character?" and "what's the numeric form of `™`?". Everything runs in your browser; nothing is uploaded.
developertext
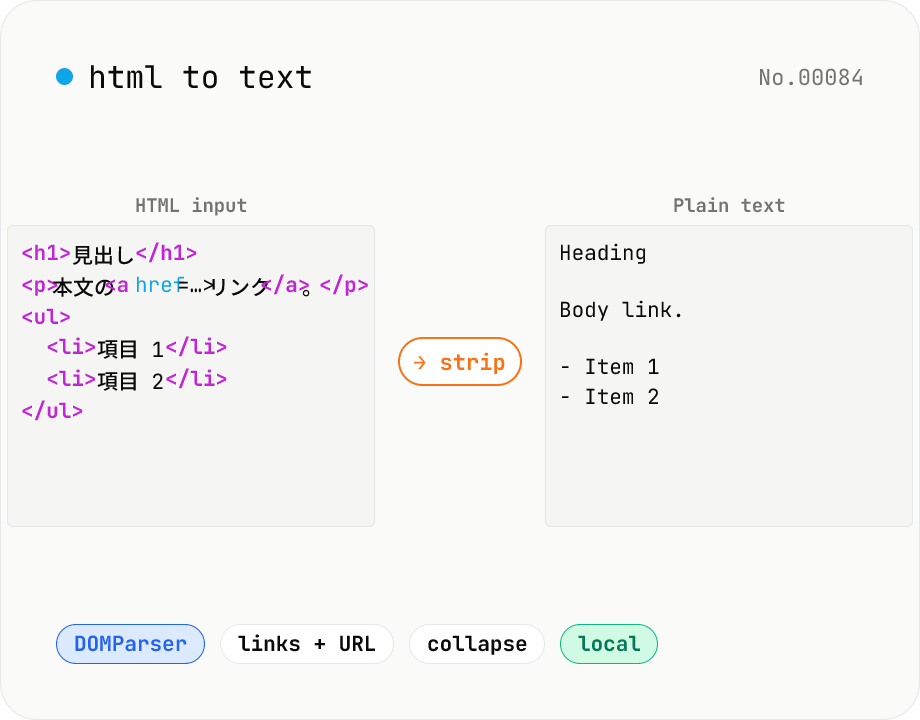
HTML to text — strip tags and keep only the visible text
Strip a chunk of HTML to its plain visible text. Removes script / style / noscript / comments; converts <p>, <h*>, <li>, <br>, etc. to line breaks; optionally pairs link text with its href. Toggles for collapsing whitespace, decoding HTML entities, and keeping list markers. Useful for cleaning scraped pages, NLP preprocessing, plain-text emails, or pasting articles into note apps. Everything runs in your browser.
developerextracttextMarkdown

Meme Caption Generator (Impact-style)
Drop your image and add classic Impact-style top and bottom captions in white with a black outline — the legendary internet meme look. Adjust font size, fill colour, outline colour and outline width, force uppercase, and let long captions wrap automatically (per-word for English, per-character for Japanese). Export as PNG, JPEG or WebP. Pure Canvas implementation with a font fallback chain (Impact → Anton → Oswald → Arial Black). Your image stays in your browser — never uploaded.
textgenerate

Image to ASCII art — render photos as text characters
Convert JPEG / PNG / WebP images into ASCII art entirely in the browser. Map each pixel's luminance to a character ramp, tweak the output width, choose a charset (detailed / standard / simple / blocks), or invert the mapping — all with a live preview. Copy the result or download it as a .txt file. Your image never leaves the browser.
imageconversiontext
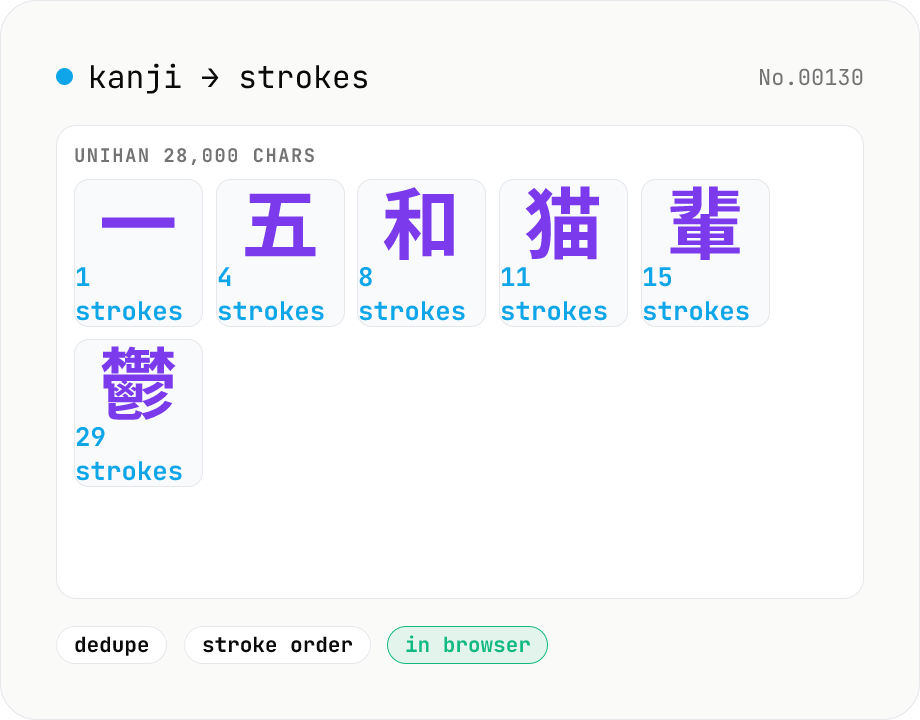
Kanji stroke count — bulk lookup / 28,000 characters
Extract every CJK ideograph from your input and look up its stroke count in a table. Backed by 28,000+ characters from Unicode 17's Unihan kTotalStrokes — covers all jōyō kanji, JIS X 0208 levels 1 & 2, and most of CJK Extension A and Compatibility. Optional dedupe and stroke-order sort, with running total. Useful for studying, name-stroke analysis, or just checking your kid's homework. Runs entirely in your browser.
japanesetextcount
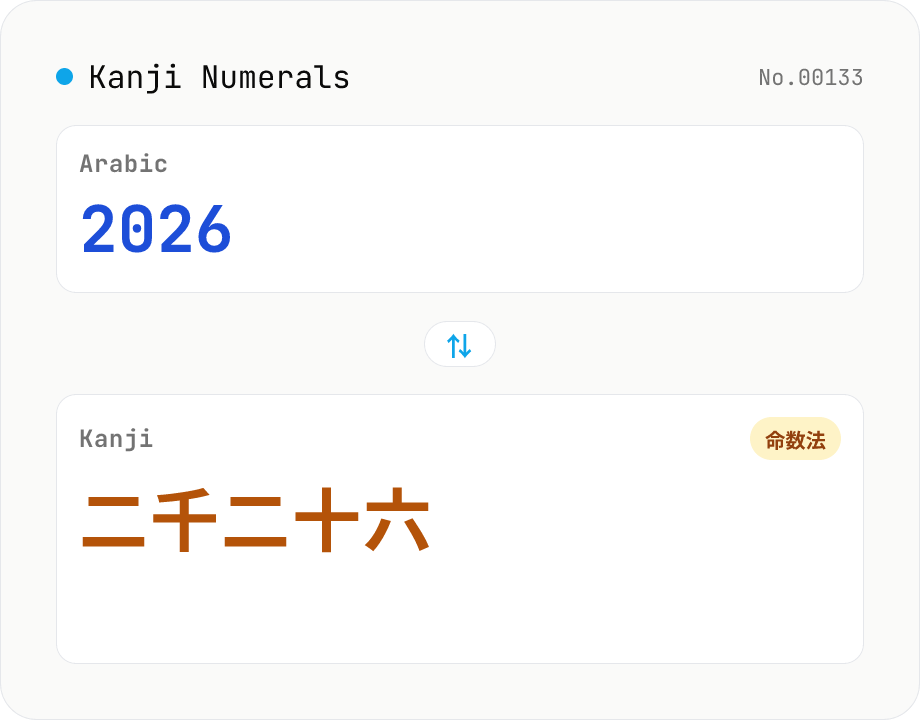
Kanji Numeral Converter
Convert between kanji numerals and Arabic digits. Supports place-value form (千二百三十四), daiji (壱弐参拾 — the tamper-resistant form used on contracts and promissory notes), and positional form (二〇二六). Handles up to 垓 (10^20), recognizes daiji, full-width digits, and thousands commas. Runs entirely in your browser — no uploads.
japaneseconversiontext
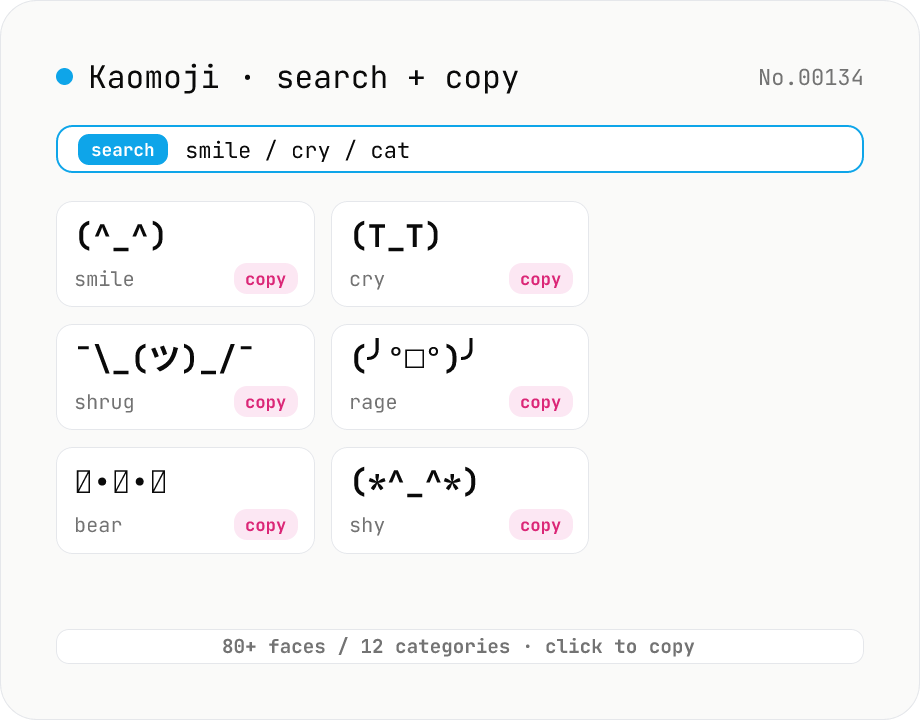
Kaomoji finder — copy (^_^) ¯\_(ツ)_/¯ and 80+ classic faces
Search 80+ classic kaomoji (text emoticons) across 12 categories — happy, sad, angry, surprise, love, confused, shrug, table flip, animal, music, and more — by face, tag, or category, then copy with one click. Unlike emoji, kaomoji render identically on Slack, Discord, LINE, GitHub, and email regardless of fonts or platforms, so you can express emotion without worrying about Unicode compatibility. All data ships with the tool; no network, no upload — everything happens in your browser.
japanesetext
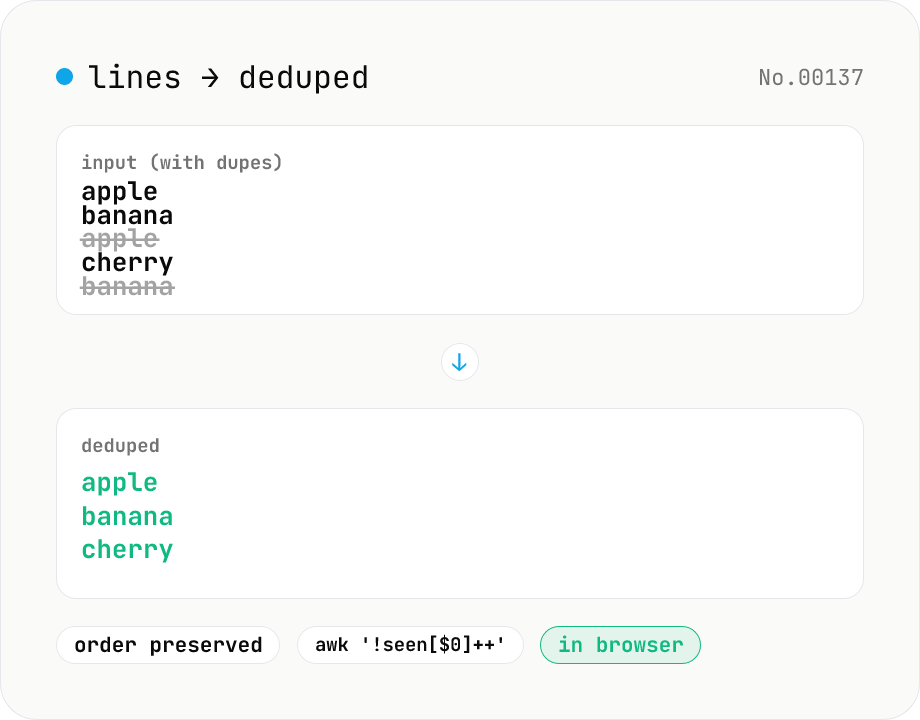
Line dedupe — keep unique or extract duplicates
Split the input by newline and remove duplicate lines, keeping only the first occurrence of each line in original order. Catches non-adjacent duplicates as well (equivalent to `awk '!seen[$0]++'`). Runs entirely in your browser.
developertext
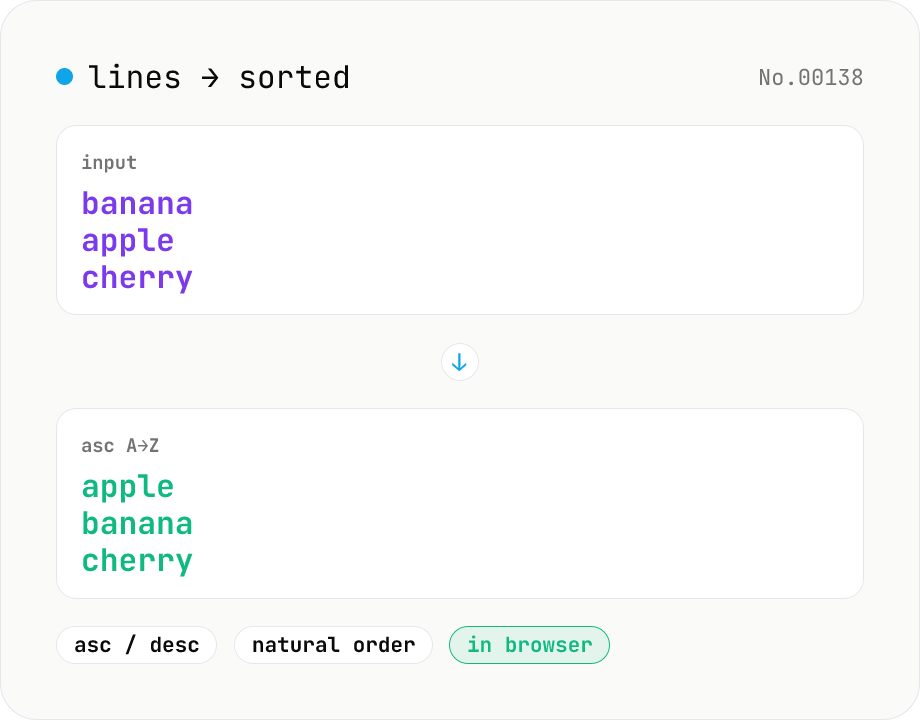
Line sort — asc / desc / numeric / locale
Split the input by newline and sort the lines either ascending (A→Z) or descending (Z→A) using locale-aware Unicode comparison. Numeric runs (file1, file2, file10) sort naturally. Empty lines and the trailing newline are preserved. Works with mixed Japanese/ASCII text. Runs entirely in your browser.
developertext

Lorem Ipsum generator — paragraphs of dummy text
Generate placeholder text for mockups, wireframes, and tests entirely inside your browser. Supports English Lorem ipsum and a Japanese variant. Pick the number of paragraphs and sentences per paragraph, then copy or download in one click — no API calls.
developertextgenerate
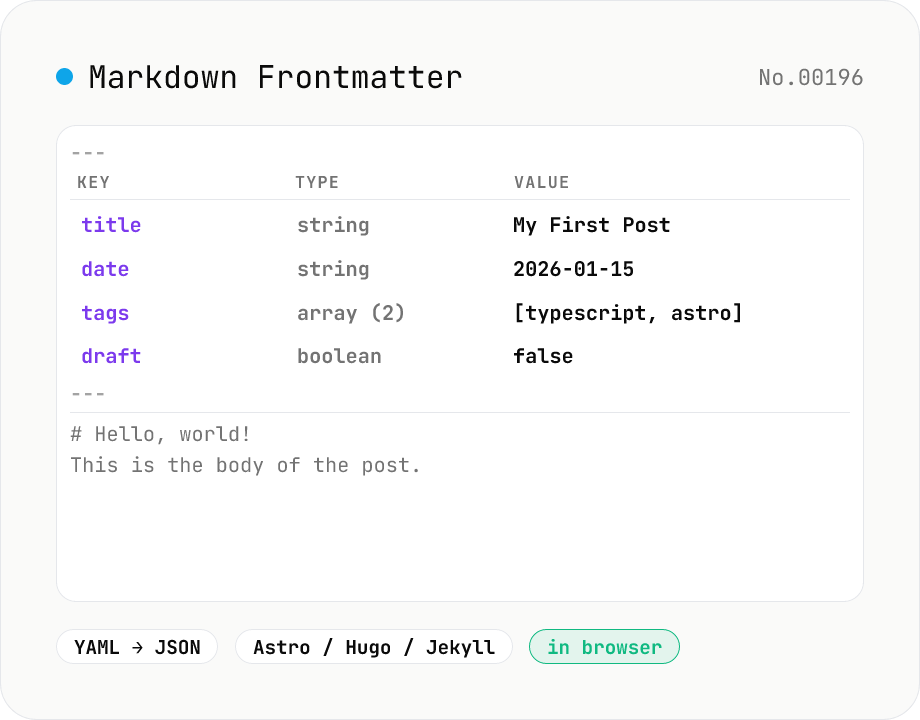
Markdown Frontmatter Parse / Compose
Parse the YAML frontmatter (--- ... ---) that sits atop Astro / Hugo / Jekyll / Next.js MDX files into a key-value table and JSON, or go the other way: type a YAML block plus a body and the tool stitches them into a Markdown file with frontmatter. Mode toggle covers both directions — built for blog and static-site editing.
developertext
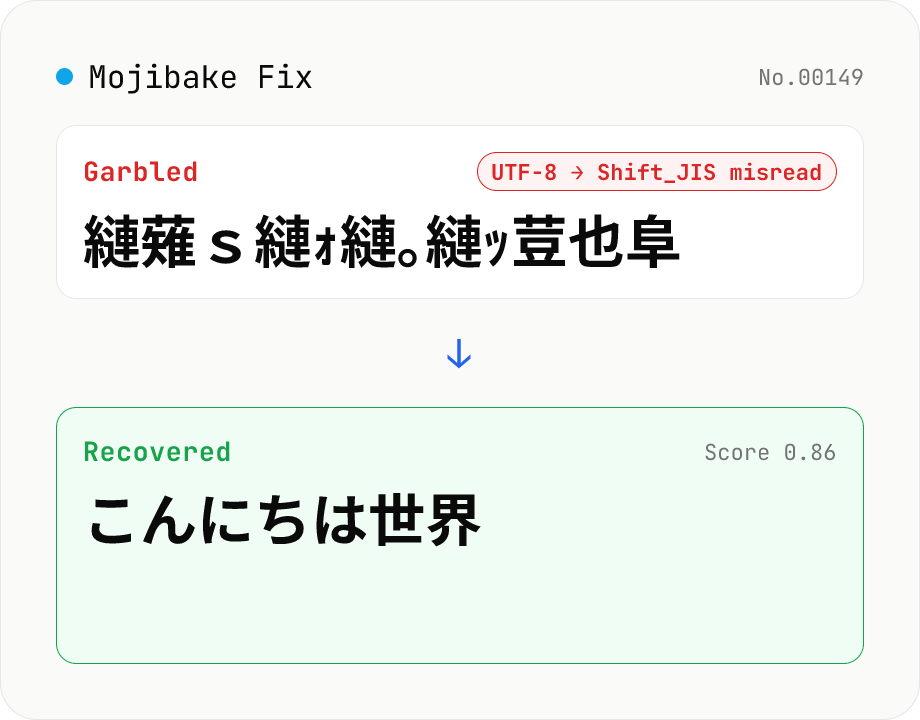
Mojibake Fix
Paste garbled Japanese text and recover the original. Tries every (source → misread) encoding pair (Shift_JIS / EUC-JP / UTF-8 / Latin-1), ranks candidates by Japanese-likeness score. Runs entirely in your browser.
japanesetextconversion
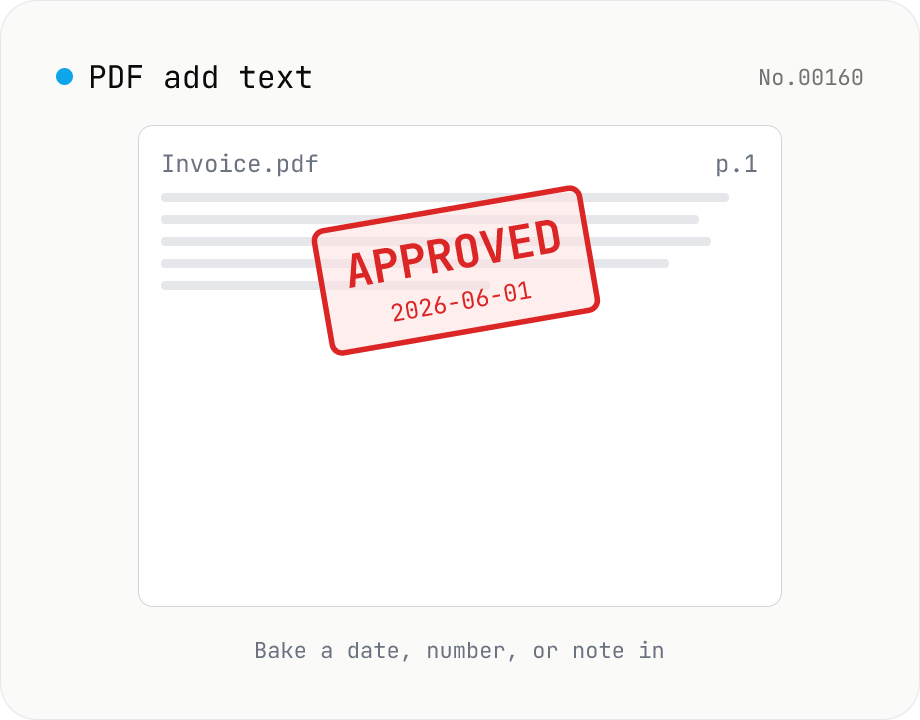
PDF add text — bake dates, notes, or labels into a page
Drop a text annotation onto a chosen page of a PDF — perfect for date stamps, file numbers, contractor names, or any quick label that just needs to look right. Position via 9-grid + margin, set font size / color / rotation / opacity, and pick which pages. Uses pdf-lib's built-in Helvetica (Regular / Bold / Oblique), so the text is ASCII / Latin only. For Japanese, build a stamp PNG with stamp-jp and place it with pdf-add-image. Multiple PDFs can be batched and downloaded as a ZIP. Files never leave your browser.
pdftext

PDF text extract — export pages to .txt
Extract plain text from PDF files entirely in the browser via pdfjs-dist getTextContent. Each PDF becomes its own .txt file; batch downloads ship as a ZIP. Page-break markers are optional.
pdfextracttext