TAG
「テキスト」タグのツール
40 個のツール
テキスト全般を扱うツール。整形 / 検索置換 / 文字数カウント / Diff / ソート など。
「テキスト」タグが付いている NoSend Tools のツール一覧。すべてブラウザ内で完結し、入力データはサーバーへ送信されません。
タグ:
並び順:
1 ページあたり:
ツール一覧
40 / 40 件

ビンゴカード生成 (3×3 〜 7×7 + FREE)
1 行 1 項目のリスト (数字 / 単語 / 俳句 / 社内ジャーゴン他) から N×N (3〜7) のビンゴカードを N 枚一括生成。FREE セル (中央、奇数サイズのみ)、シード指定で同じ結果を再現可能、TSV エクスポート。社内イベント・学校・カンファレンス・読書会 / 飲み会のアイスブレイクに。
開発テキスト

文字数カウント — 文字 / バイト / 行 / 単語
テキストの文字数・単語数・行数・段落数・UTF-8 バイト数をリアルタイムで集計。空白・改行を含めるか除くかを切り替え可能で、Twitter・原稿用紙 (400 字)・LINE などの文字数上限の進捗バーも同時表示。すべてブラウザ内で動くので、原稿や下書きを安全にカウントできます。
開発テキストカウント

CSV / テキスト文字コード変換 — Shift_JIS ⇄ UTF-8 / BOM / 改行
Shift_JIS (CP932) と UTF-8、UTF-16LE、EUC-JP の間で CSV / テキストファイルを変換します。Excel が出す Shift_JIS の文字化け、UTF-8 のテキストを古いシステムに渡せない問題、Excel が BOM 無し UTF-8 を文字化けさせる問題などに対応。BOM 付与/除去、改行コード (CRLF / LF / CR) の差し替え、入力エンコーディング自動判定をサポート。複数ファイルを一括変換して ZIP で受け取れます。アップロードしたファイルは外部に送信されず、すべての処理はブラウザ内で完結します。
開発テキスト変換
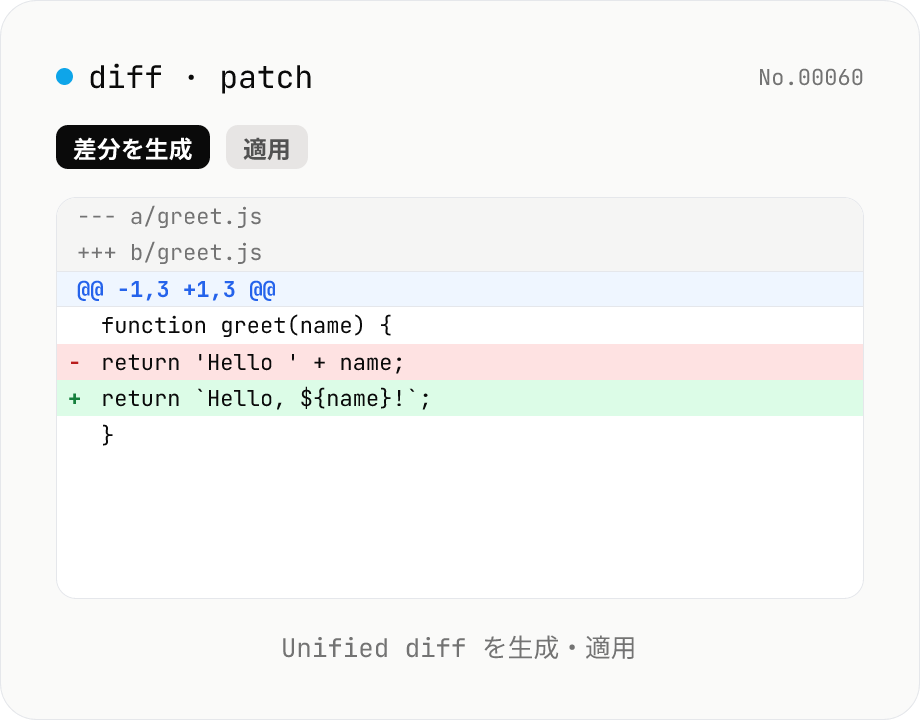
diff / patch — Unified diff の生成・適用
2 つのテキストから Unified diff (.patch / .diff) を生成し、Unified diff を元テキストに適用 (apply) できる。Git や GNU patch と同形式 (--- / +++ / @@ ハンク)、コンテキスト行数とファイル名を指定可。すべてブラウザ内で処理。
開発テキストDiff
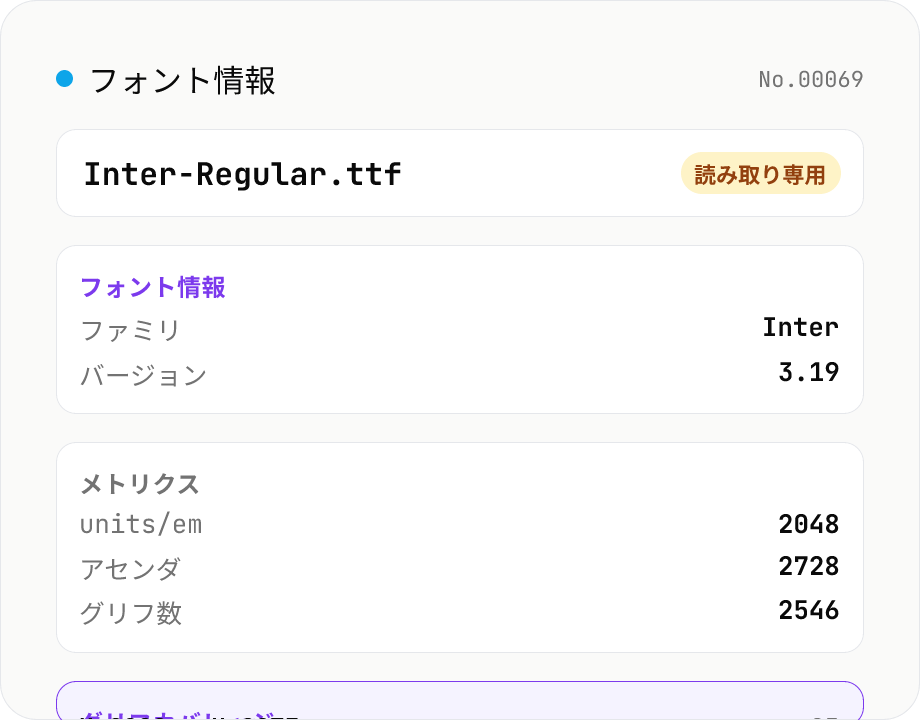
フォント情報ビューア
TTF / OTF / WOFF / WOFF2 フォントファイルをドロップして、フォント名・ファミリ・バージョン・著作権・ライセンス・デザイナー・グリフ数・サポートされている Unicode 範囲を一覧表示します。書き換えなしの読み取り専用、opentype.js (MIT) でブラウザ内のみ実行。
開発抽出テキスト
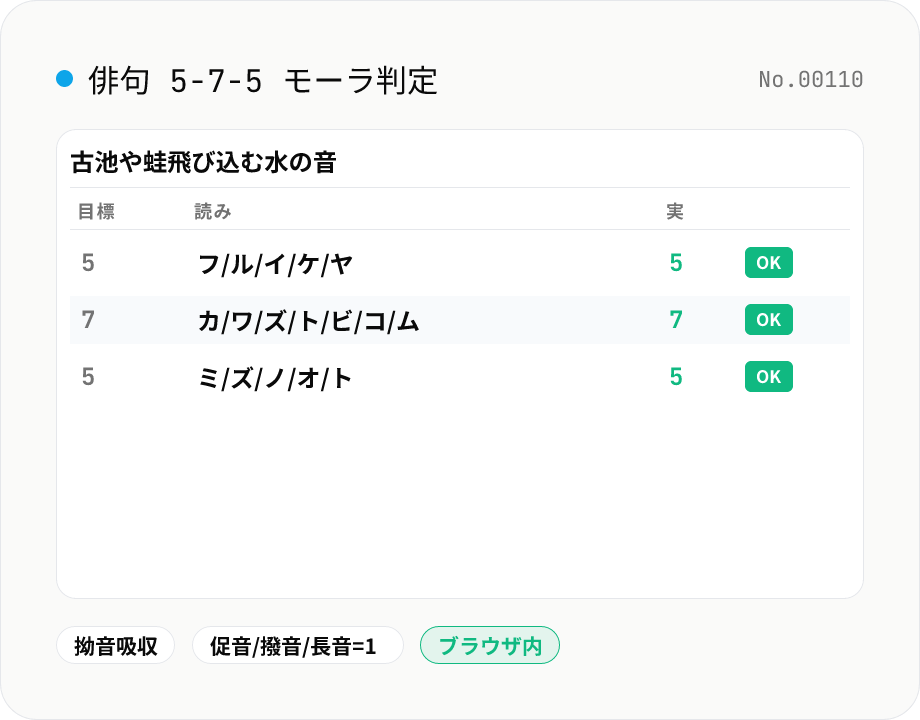
俳句 / 短歌 モーラカウント (5-7-5 / 5-7-5-7-7)
俳句 (5-7-5) や短歌 (5-7-5-7-7) の音数を kuromoji 形態素解析で自動判定。漢字混じりの文を入れると読みを取得 → モーラ列に分解 → 句ごとの音数と期待値の過不足を可視化します。拗音 (キョ, シャ など) は前のモーラに吸収、促音 (ッ)・撥音 (ン)・長音 (ー) は単独 1 モーラの俳句ルール準拠。
日本語テキスト
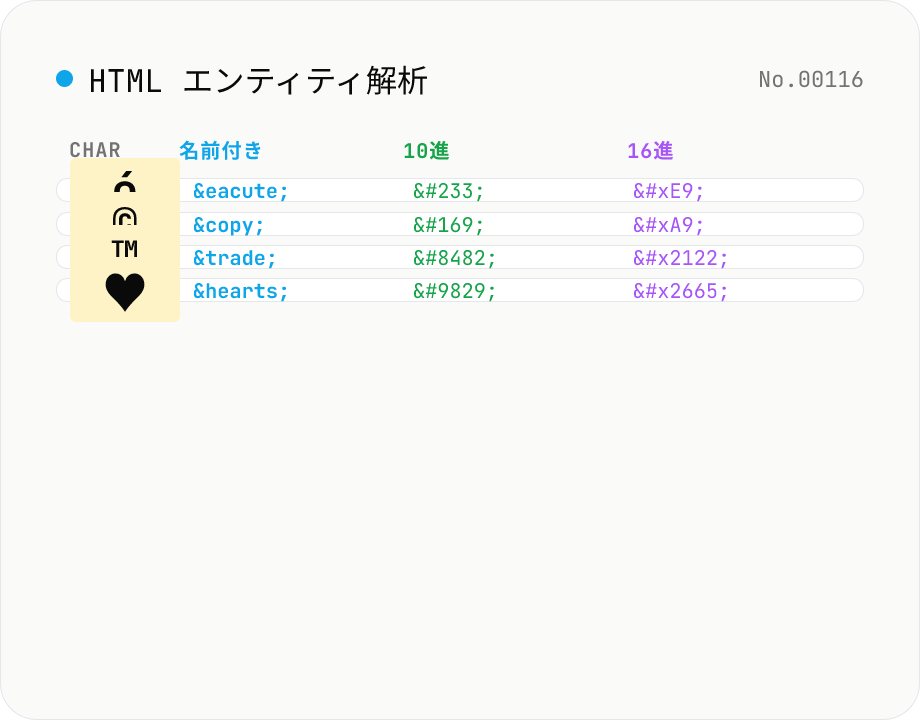
HTML エンティティ解析 — 名前付き / 10進 / 16進 / Unicode 名を並列表示
HTML エンティティを含む文字列を貼り付けると、含まれるすべてのエンティティ (`&` `é` `é` `é` ` ` `©` 等) を検出し、**実際の文字 / 名前付きエンティティ / 10 進数値参照 / 16 進数値参照 / Unicode コードポイント** を一覧表で並列表示します。逆方向の検索 (文字 → エンティティ表記) もサポート: たとえば `é` を入れると 名前付き `é` / 数値 `é` / 16 進 `é` を一気に取得できます。HTML5 仕様の **2125 個の名前付きエンティティ** すべてを内蔵 (`&`, `©`, `&heart;`, `∳` 等)。`html-encode` (文字列全体を encode/decode する) と `unicode-inspect` (Unicode コードポイント詳細) との中間ポジションで、「この絵文字を `♥` で書きたいけど名前あったっけ?」「`™` の数値表記って何?」を解決するためのリファレンスツール。すべてブラウザ内で処理、サーバー送信なし。
開発テキスト
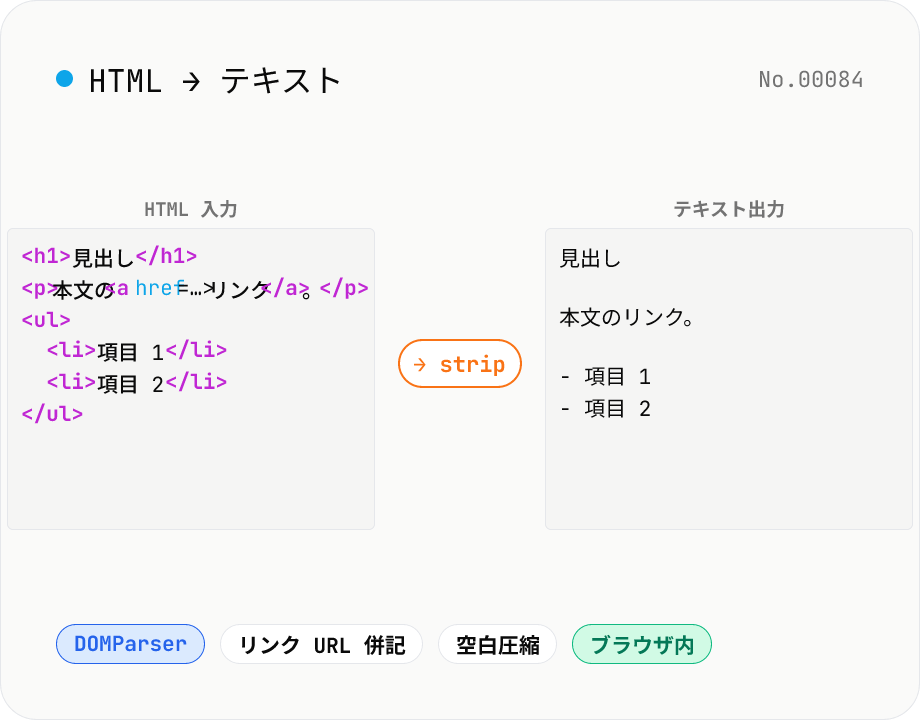
HTML → テキスト変換 — タグを剥がして可視テキストだけ抽出
HTML から script / style / noscript / コメントを除去し、可視テキストだけを取り出します。<p> や <h*>、<li>、<br> などのブロック要素は改行に展開され、リンクは「テキスト + URL 併記」も選択可能。連続空白の圧縮、HTML エンティティのデコード、箇条書きマーカー保持などのオプション。スクレイピング結果から本文だけ取りたい、NLP の前処理、メール本文の plain-text 化、記事のコピペ整形などに。すべてブラウザ内で処理されます。
開発抽出テキストMarkdown

ミーム画像生成 (Impact 風キャプション)
画像の上部と下部に Impact 風のフォントで白文字 + 黒縁取りのキャプションを乗せて、海外掲示板でおなじみの『meme』風画像を生成。フォントサイズ・文字色・縁取り色・縁取り幅・大文字化 を調整可、長文は自動で折り返し (日本語は文字単位、英語は単語単位)。出力は PNG / JPEG / WebP。Canvas のみで実装され、フォントは Impact → Anton → Oswald → Arial Black の順で fallback。画像はアップロード後すべてブラウザ内で処理され、サーバーへ送信しません。
テキスト生成
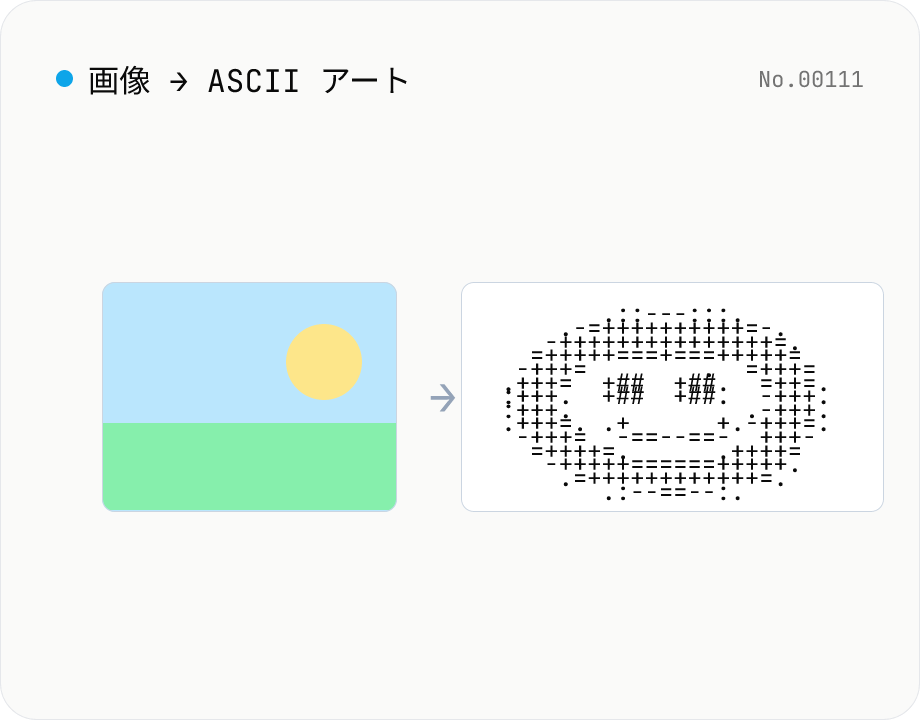
画像 → ASCII アート変換 — 文字で再描画
JPEG / PNG / WebP の画像をブラウザ内で読み込み、各ピクセルの輝度を文字に置換して ASCII アートに変換します。出力幅 (列数)、文字セット (詳細 / 標準 / シンプル / ブロック)、明暗反転を切り替えながらリアルタイムにプレビュー可能。完成した結果はコピー、または .txt ファイルとしてダウンロードできます。画像は外部に送信されず、すべての処理はブラウザ内で完結します。
画像変換テキスト
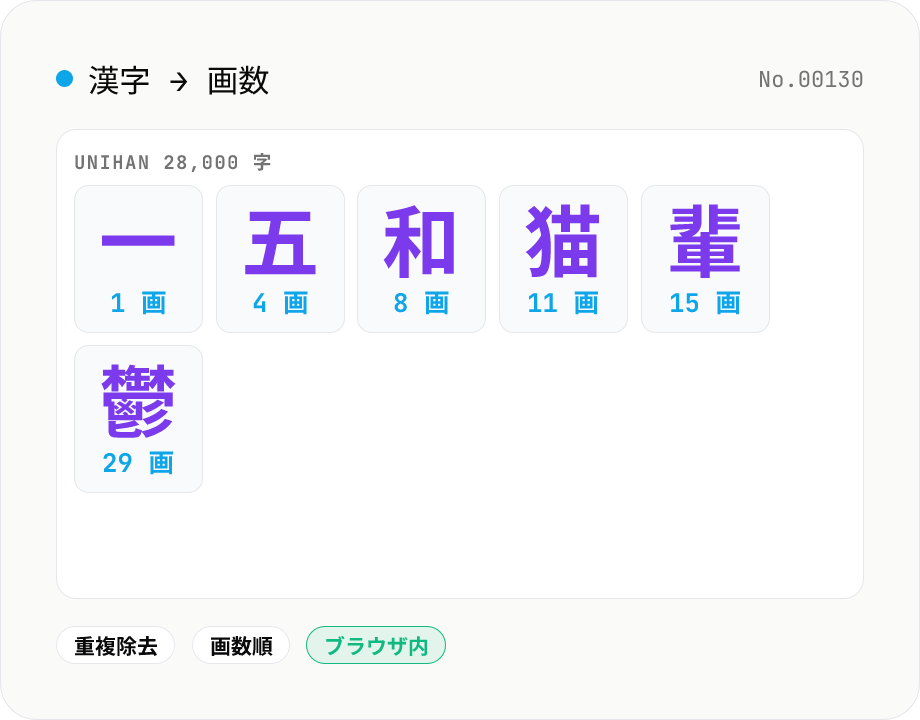
漢字の画数 — 一括カウント / 28,000 字収録
入力テキストから漢字だけを取り出して、1 文字ずつの画数を表で表示します。常用漢字・JIS X 0208 第一・第二水準を含む 28,000 字以上 (Unicode 17 Unihan kTotalStrokes 由来) に対応。重複除去・画数順並び替え・合計画数の集計に対応。学習・名前の画数調べ・字解き・小学校の宿題チェックに。すべてブラウザ内で処理。
日本語テキストカウント
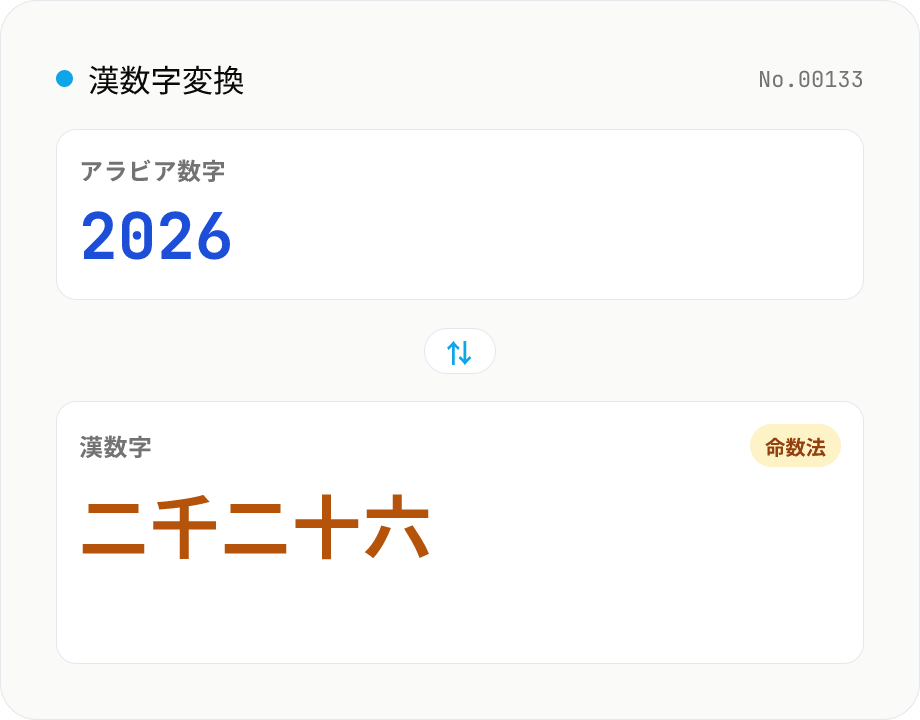
漢数字変換
漢数字とアラビア数字を相互変換します。命数法 (千二百三十四)・大字 (壱弐参拾 — 契約書や手形で使う改ざん防止表記)・位取り (二〇二六) の 3 形式に対応。万・億・兆・京・垓まで対応し、大字や全角数字・桁区切りカンマも自動認識。ブラウザ内のみで実行、サーバーに送信しません。
日本語変換テキスト
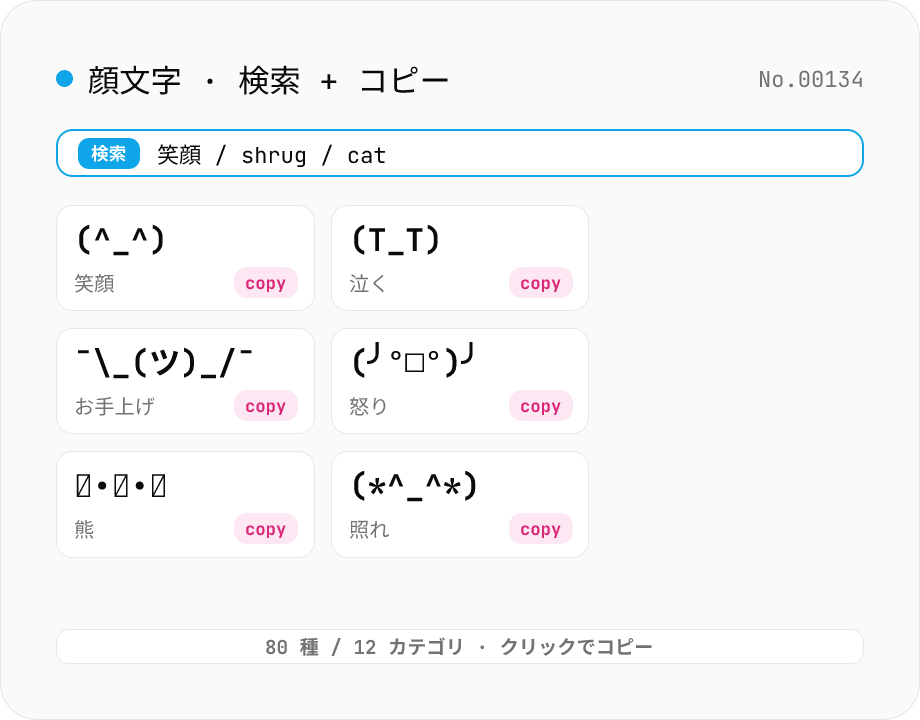
顔文字検索 — (^_^) や ¯\_(ツ)_/¯ などをカテゴリ別にコピー
笑顔・泣き・怒り・驚き・愛・困惑・ちゃぶ台返し・動物・音楽など 12 カテゴリ計 80 種以上の顔文字 (キャラクター絵文字) を、テキスト・タグ・カテゴリの 3 つから横断検索してワンクリックでコピーできます。Unicode と中点・矢印・括弧の組み合わせで構成された顔文字は emoji と違って Slack / Discord / LINE / メールなどあらゆる環境で同じ見た目で表示できるので、絵文字の互換性を気にせず感情を載せられるのが利点。すべてのデータはツールに同梱されており、ネット接続もサーバー送信もなくブラウザ内で動作します。
日本語テキスト
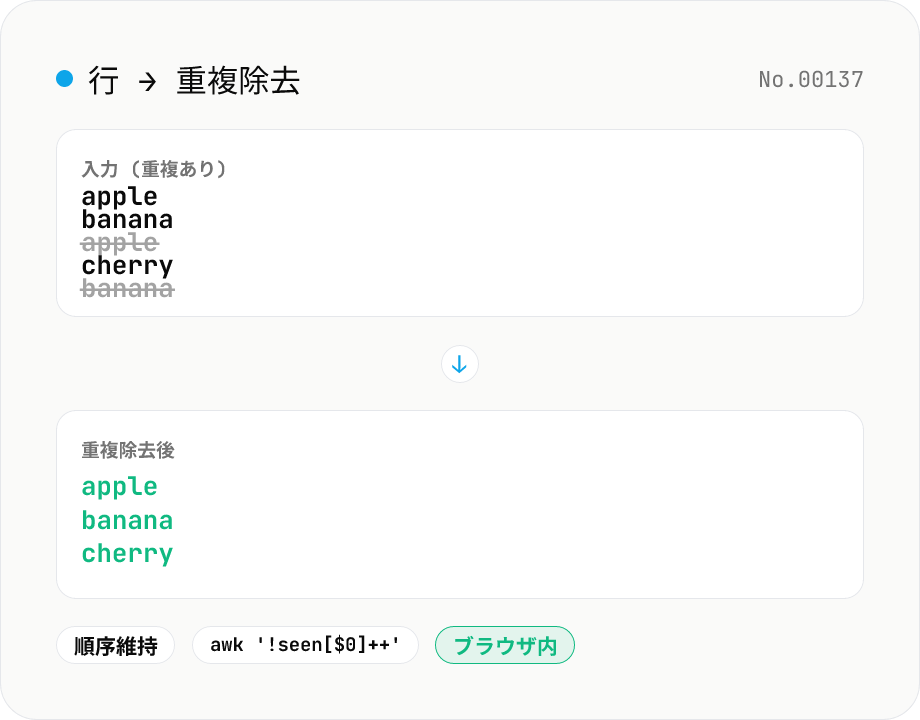
行重複削除 — 全部一意化 / 重複だけ抽出
テキストを行 (\n) で分割し、重複する行を除去します。初出の行だけを保持し、元の順序を維持。連続した重複だけでなく離れた位置の重複も対象 (Unix `awk '!seen[$0]++'` 相当)。すべてブラウザ内で処理。
開発テキスト
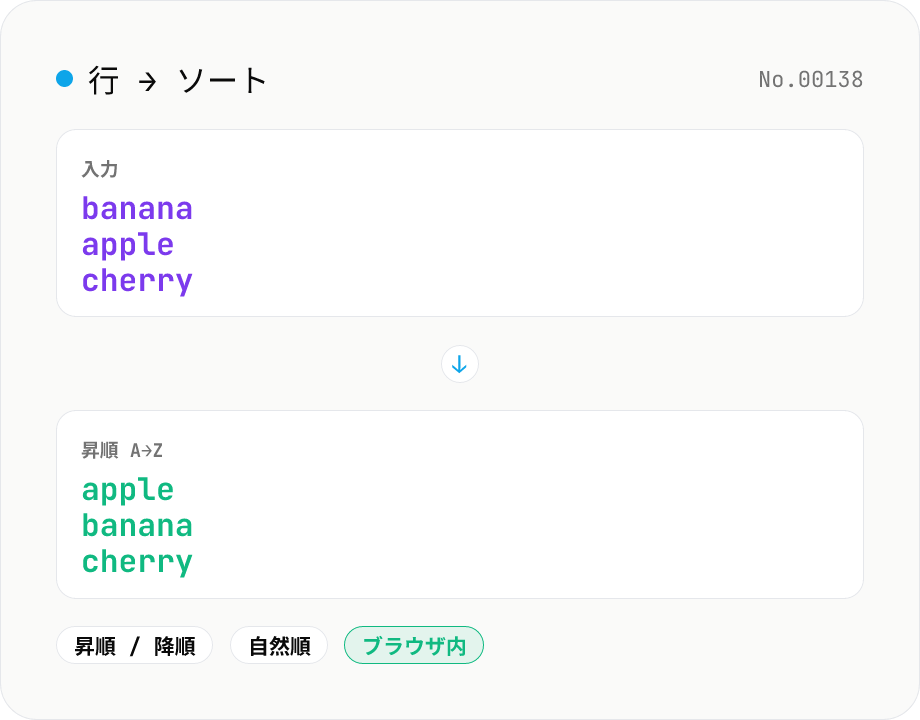
行ソート — 昇順 / 降順 / 数値 / ロケール
テキストを行 (\n) で分割し、Unicode のロケールに従って昇順 (A→Z) または降順 (Z→A) に並び替えます。数値混じり (file1, file2, file10) も自然順に。空行や末尾の改行はそのまま保持。日本語混在テキストにも対応。すべてブラウザ内で処理。
開発テキスト
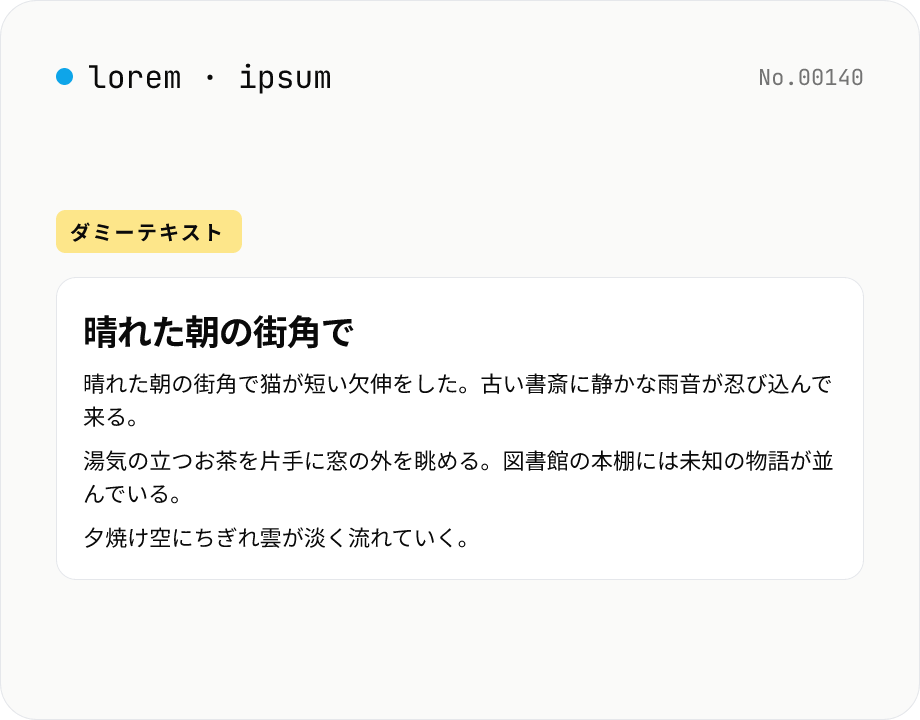
Lorem Ipsum 生成 — ダミー文を段落単位で
デザインカンプ・ワイヤーフレーム・テスト用に、英語の Lorem ipsum と日本語のダミー文をブラウザだけで生成。段落数と 1 段落あたりの文数を指定でき、ワンクリックでコピーやファイルダウンロードができます。外部 API を呼ばないので、社内資料やオフライン作業でも使えます。
開発テキスト生成
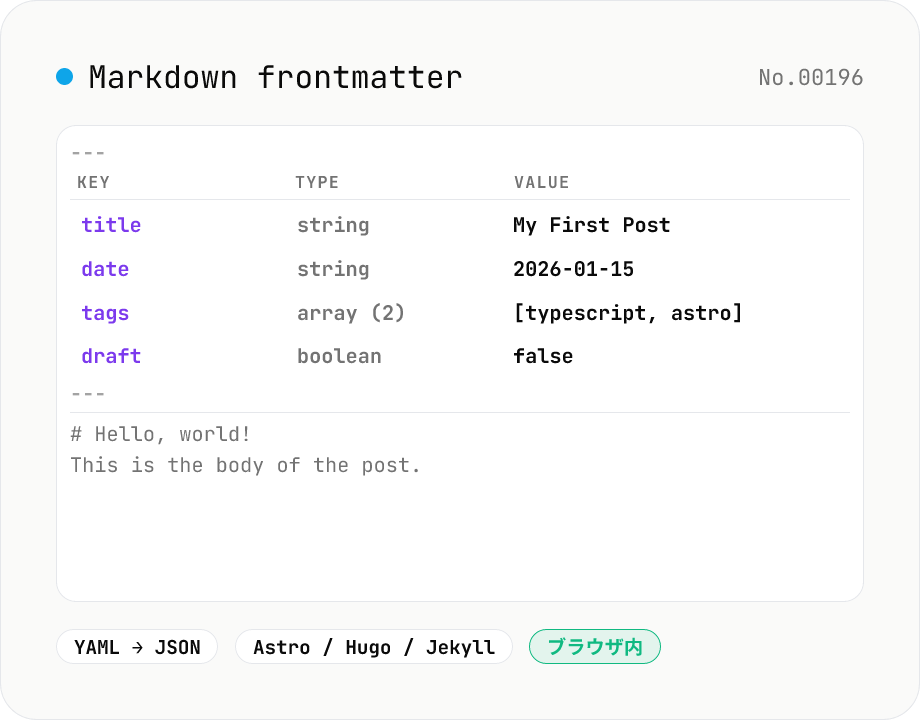
Markdown frontmatter パース / 生成
Astro / Hugo / Jekyll / Next.js MDX の Markdown ファイル先頭に置く YAML frontmatter (--- ... ---) を解析して key-value テーブル + JSON 表示。逆方向では YAML テキストを書いて本文と組み合わせ、frontmatter 付き Markdown を生成。Mode 切替で両方向。ブログ・静的サイト・ドキュメントの編集に。
開発テキスト
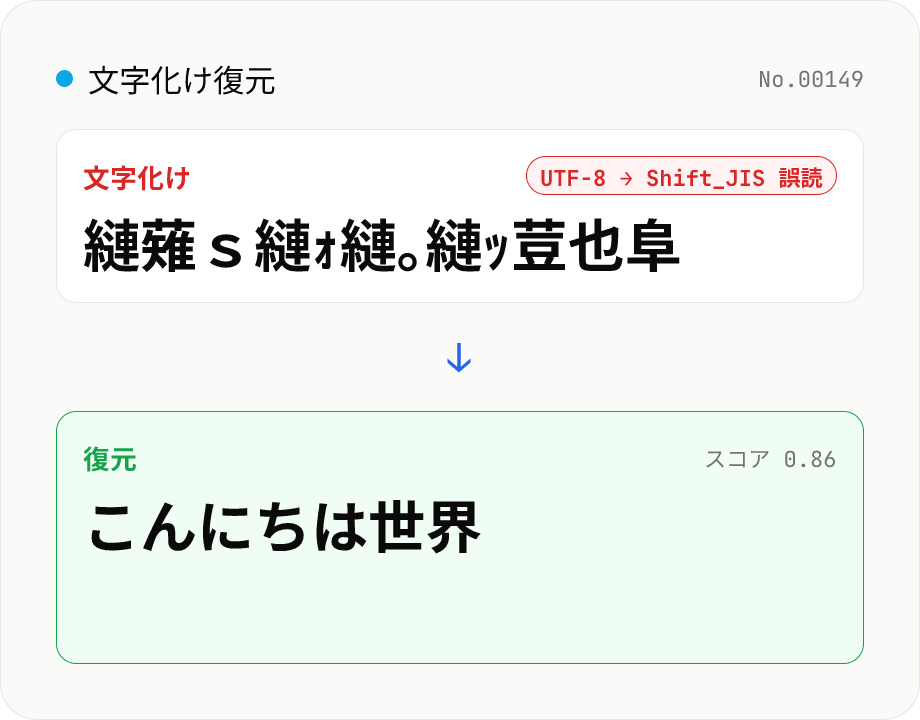
文字化け 解読・変換ツール — Shift_JIS / EUC-JP / UTF-8 自動判定
文字化けしたテキストを貼り付けるだけで日本語に戻す無料オンラインツール。Shift_JIS / EUC-JP / UTF-8 / ISO-2022-JP / Latin-1 の誤読パターンを総当たりで試し、日本語らしさスコアが高い順に復元候補を並べます。メール・CSV・ログの文字化け直しに。すべてブラウザ内で完結し、入力テキストは送信されません。
日本語テキスト変換
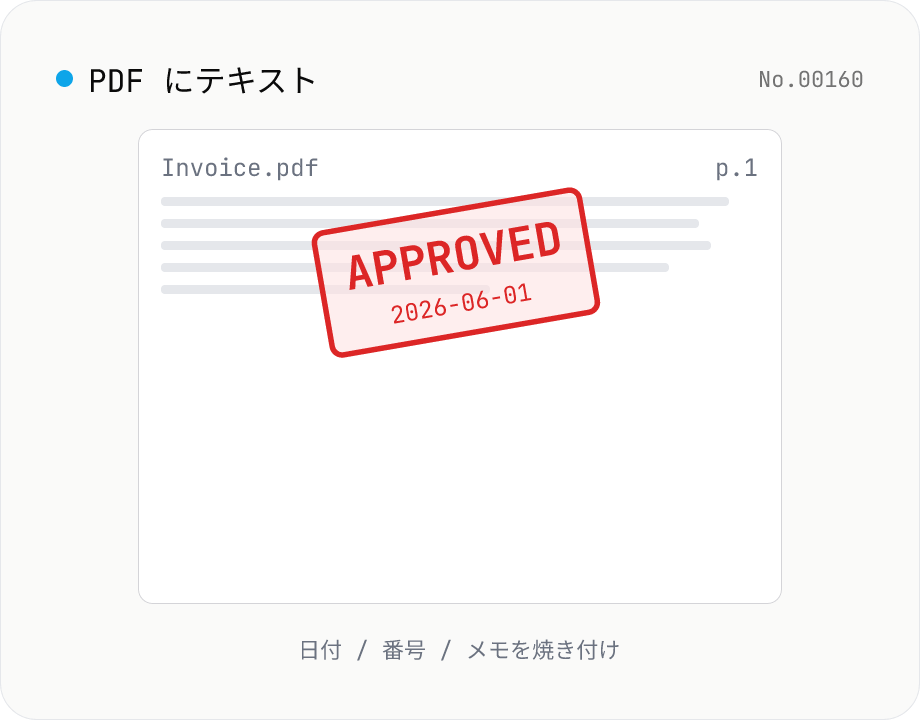
PDF にテキストを書き込む — 注釈 / 日付 / メモを焼き付け
PDF の指定ページにテキストを書き込みます。「日付」「メモ」「ファイル番号」など、見栄えだけ整えればよい英数字の注釈を後付けする用途に最適。位置は 9 グリッド + 余白、フォントサイズ・色・回転・不透明度を調整できます。フォントは pdf-lib 標準の Helvetica (Regular / Bold / Oblique) を使うため英数字専用。日本語テキストを書き込みたい場合は stamp-jp で印鑑風画像を作って pdf-add-image で貼る方法を推奨。複数の PDF をまとめて処理でき、結果は ZIP でダウンロード可能。アップロードした PDF はサーバーに送信されず、すべてブラウザ内で処理されます。
PDFテキスト

PDF テキスト抽出 — .txt 書き出し
PDF からプレーンテキストをブラウザ内だけで抽出します。pdfjs-dist の getTextContent でページごとに文字列を集め、1 ファイル = 1 つの .txt として書き出し。複数 PDF はまとめて ZIP でダウンロードできます。ページ区切りマーカーの有無は切り替え可能。
PDF抽出テキスト