TAG
「音声」タグのツール
37 個のツール
音声ファイルを扱うツール。録音 / 変換 / カット / 結合 / ノイズ除去 / 文字起こし などをブラウザ内で完結。
「音声」タグが付いている NoSend Tools のツール一覧。すべてブラウザ内で完結し、入力データはサーバーへ送信されません。
タグ:
並び順:
1 ページあたり:
ツール一覧
37 / 37 件
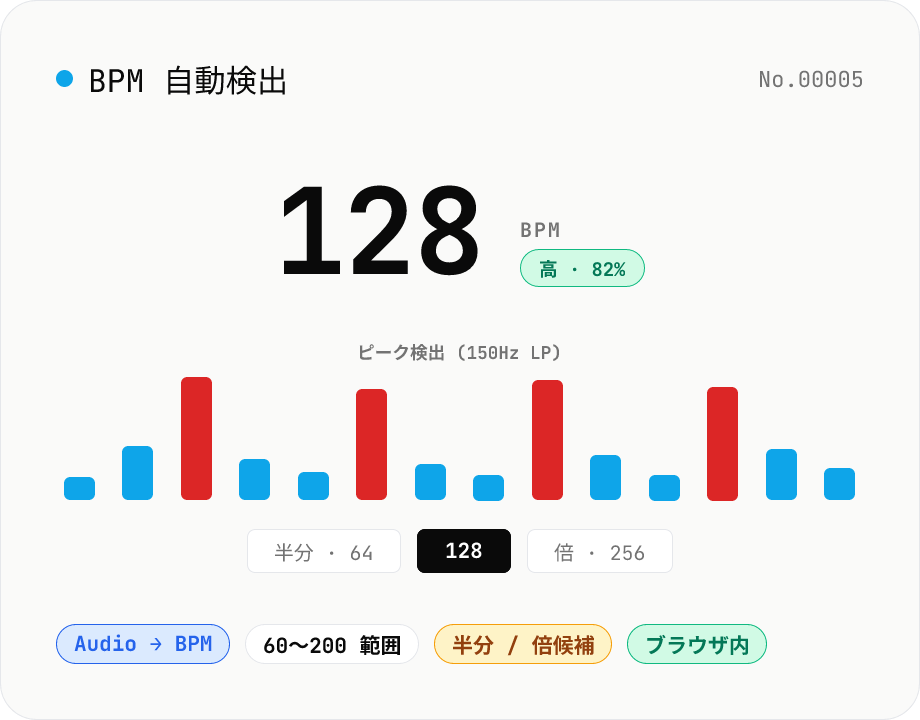
BPM 自動検出 — 音声から BPM を推定
音声ファイル (MP3 / WAV / M4A / FLAC / OGG) をドロップすると、Web Audio API のローパスフィルタ + ピーク検出 + ヒストグラム解析で曲の BPM を自動推定します。DJ ミックスの相手曲、サンプル素材のテンポ確認、踊りやランニングのテンポ合わせ、bpm-time-stretch で揃える前の参考値取得などに便利。半分・倍テンポの候補も併記するので、4 つ打ちで 60 BPM と出たけど実際は 120 BPM、のような誤検出も自分で判断できます。音声はブラウザ内で完結。
音声テンポ
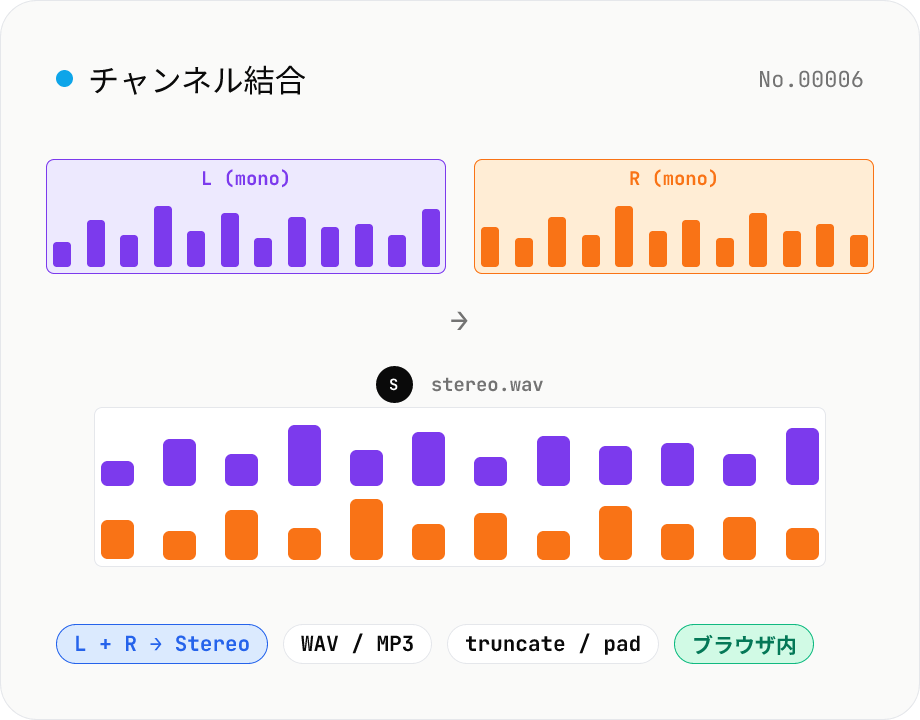
音声チャンネル結合 — 2 つのモノラルを L + R のステレオに
2 つのモノラル音声ファイル (MP3 / WAV / M4A / FLAC / OGG) を 1 つのステレオ音声に結合します。L チャンネルと R チャンネルを別々に渡すと、内部で interleave して 1 つの stereo WAV / MP3 として出力。インタビューの A 話者 / B 話者を別収録 → L / R に振り分けたい、片チャンネル素材から擬似ステレオを作りたい、audio-channel-split の逆操作で再合成したいときに使えます。長さが違う場合は短い方に合わせる / 長い方に合わせる (無音パディング) を選択可能。音声はブラウザ内で完結します。
音声結合
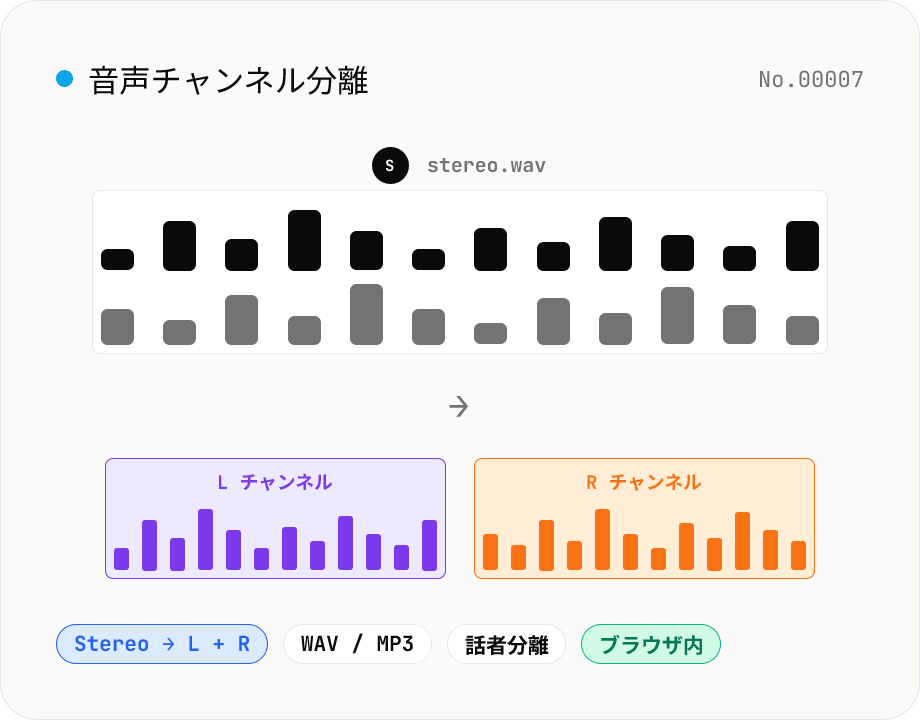
音声チャンネル分離 — ステレオ L / R を 2 つのモノラルに分割
ステレオ音声ファイル (MP3 / WAV / M4A / FLAC / OGG) を L (左) と R (右) の 2 つのモノラル WAV / MP3 として書き出します。社外録音 (インタビュー、口述記録、ZOOM 録音、ハンディレコーダー) で話者を L チャンネル / R チャンネルに分けて録ったときの分離編集、片チャンネルだけのノイズ除去、ステレオ素材から片側だけ DAW に取り込みたいときに最適。モノラル素材はそのまま 1 ファイル出力。音声はブラウザ内で完結します。
音声
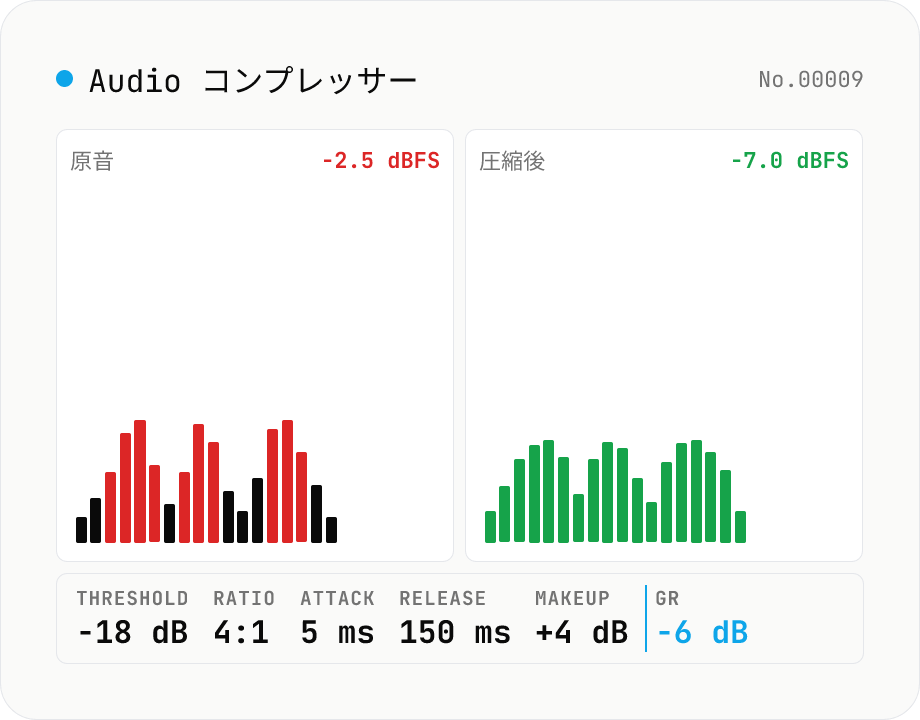
Audio コンプレッサー — threshold / ratio / attack / release を調整して WAV 出力
Web Audio API の DynamicsCompressorNode を使い、しきい値 (threshold) を超えた音声を比率 (ratio) で圧縮する古典的ダウンワード・コンプレッサーです。threshold (-60 〜 0 dB)、ratio (1:1 〜 20:1)、attack (0 〜 1 秒)、release (0 〜 1 秒)、knee (0 〜 40 dB) に加えて、補正の makeup gain (0 〜 24 dB) も指定可能。OfflineAudioContext でオフライン (= リアルタイムより高速) レンダリングし、16-bit PCM の WAV を生成します。ボーカル・ナレーション・ポッドキャストの音量を整える、ドラムを潰す、マスターでピーク抑制する、など用途は広いです。`audio-volume` (一括ゲイン)、`audio-loudness-lufs` (測定だけ)、`audio-true-peak` (測定だけ) と棲み分け。複数ファイル一括処理 + per-file WAV / ZIP 全件保存対応。音声はブラウザ内でだけ処理され、サーバーには送信されません。
音声
音声フォーマット変換 — MP3 / WAV / M4A / OGG / FLAC
音声ファイルを mp3 / wav / m4a / ogg / flac へ変換します。ffmpeg.wasm が出力拡張子に応じてコーデックを選択して再エンコード。複数ファイル一括処理 + ZIP ダウンロード対応。ファイルはサーバーに送信されません。
音声変換

音声カット — 範囲指定で再エンコードなし切り出し
音声ファイルの特定区間を ffmpeg.wasm の stream copy で切り出します。再エンコードなし・拡張子そのまま。カット点はキーフレーム境界にスナップ。複数ファイル一括処理 + ZIP ダウンロード対応。
音声分割
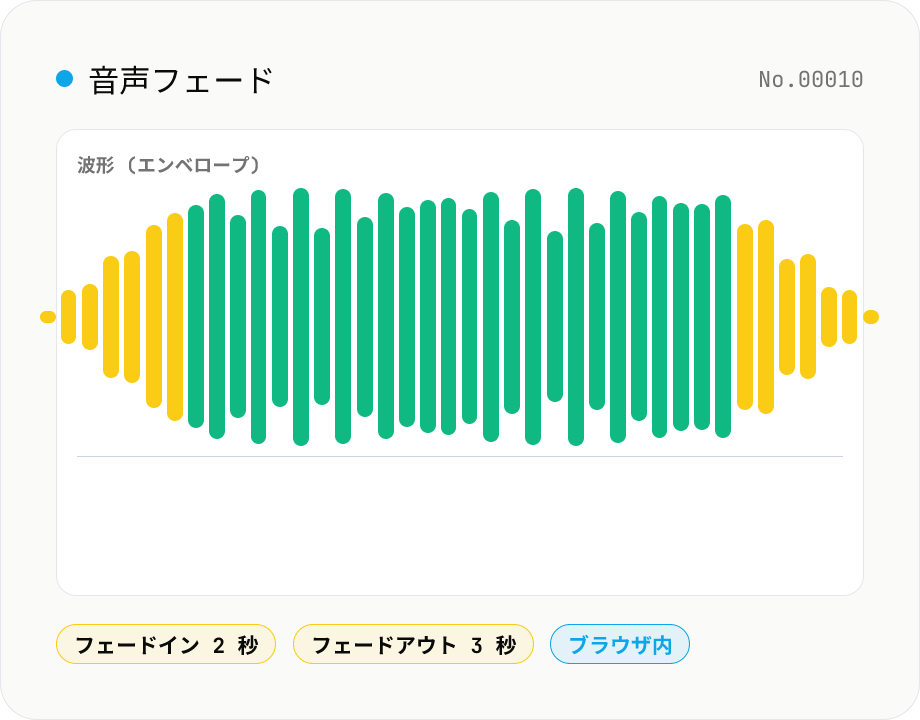
音声フェード — フェードイン / フェードアウトを秒単位で適用
音声ファイルの先頭と末尾に任意秒のフェードイン / フェードアウト効果を入れます。ffmpeg.wasm の afade フィルタを使い、MP3 / WAV / M4A / OGG / FLAC など主要フォーマットに対応。複数ファイル一括処理 + ZIP ダウンロード対応。音声はサーバーに送信されません。
音声
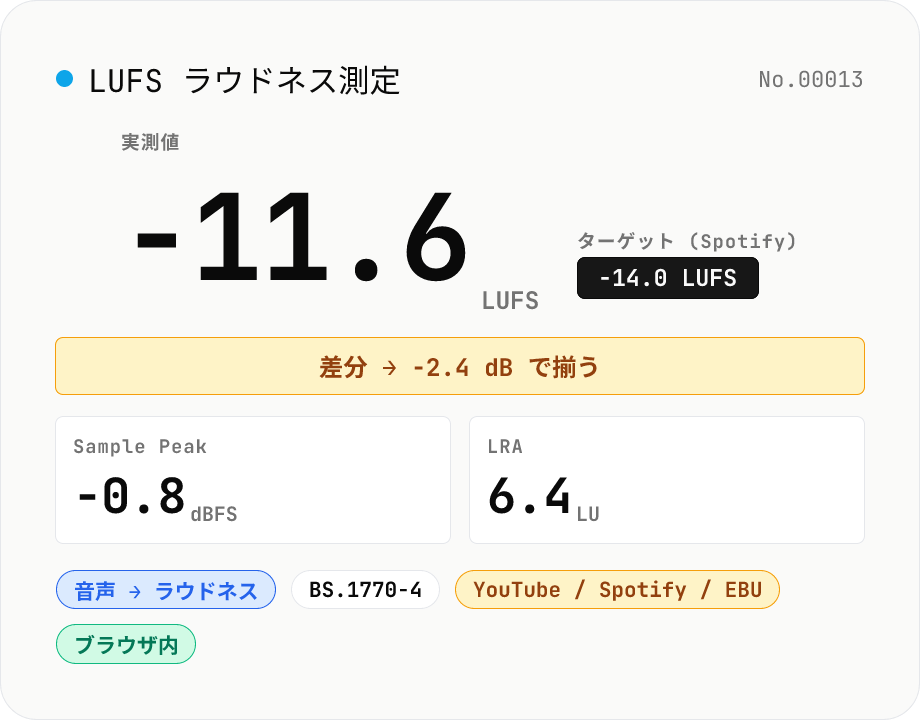
LUFS ラウドネス測定 — 配信ターゲット (YouTube / Spotify / EBU) との差分
音声ファイル (MP3 / WAV / M4A / FLAC / OGG / Opus) をドロップすると、ITU-R BS.1770-4 準拠の Integrated LUFS / Loudness Range (LRA) / Sample Peak (dBFS) をブラウザ内で測定します。配信プラットフォームのターゲットラウドネス (YouTube / Apple Music / Amazon Music: -14 LUFS, Spotify: -14 LUFS, Apple Podcasts: -16 LUFS, EBU R128 / 放送: -23 LUFS) を選ぶと、現状値とターゲットの差分 (LU) を表示。あといくつ ±dB で audio-volume を適用すれば良いかを直感的に把握できます。K-weighting フィルタ + 400 ms 矩形窓 + Absolute (-70 LUFS) + Relative (-10 LU) のゲーティングを自前 biquad で実装、ステレオは ITU 重み付け (L=R=C=1)。音声はブラウザ内で完結。
音声抽出
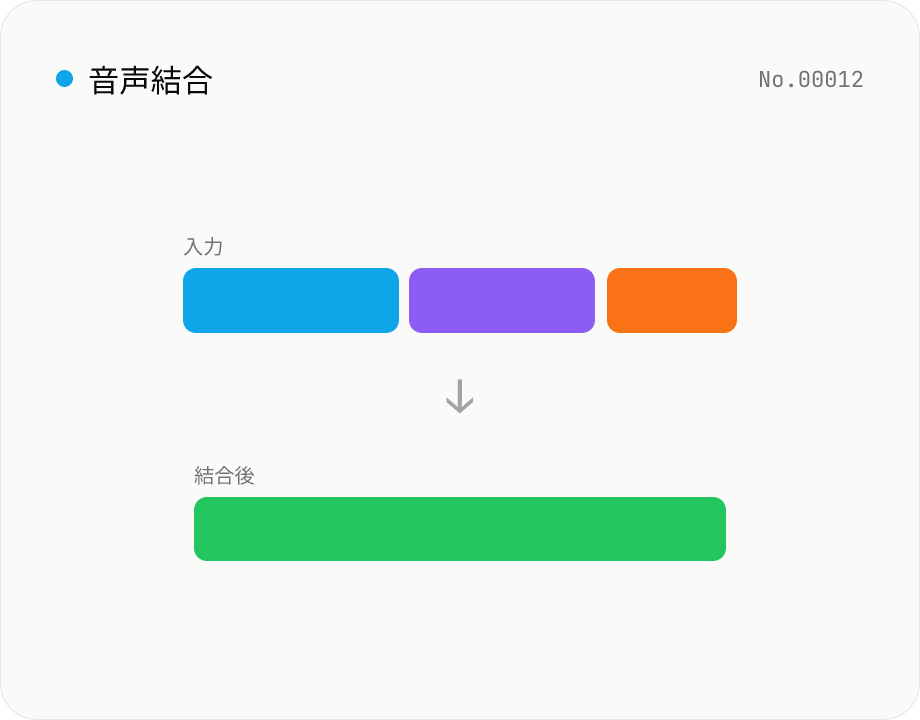
音声結合 — 複数ファイルを 1 つに連結
複数の音声ファイルを ffmpeg.wasm の concat demuxer で結合します。ドラッグで並び替え。stream copy なので再エンコードなしですが、コーデック・サンプルレートが同じファイル同士のみ結合可能。
音声結合
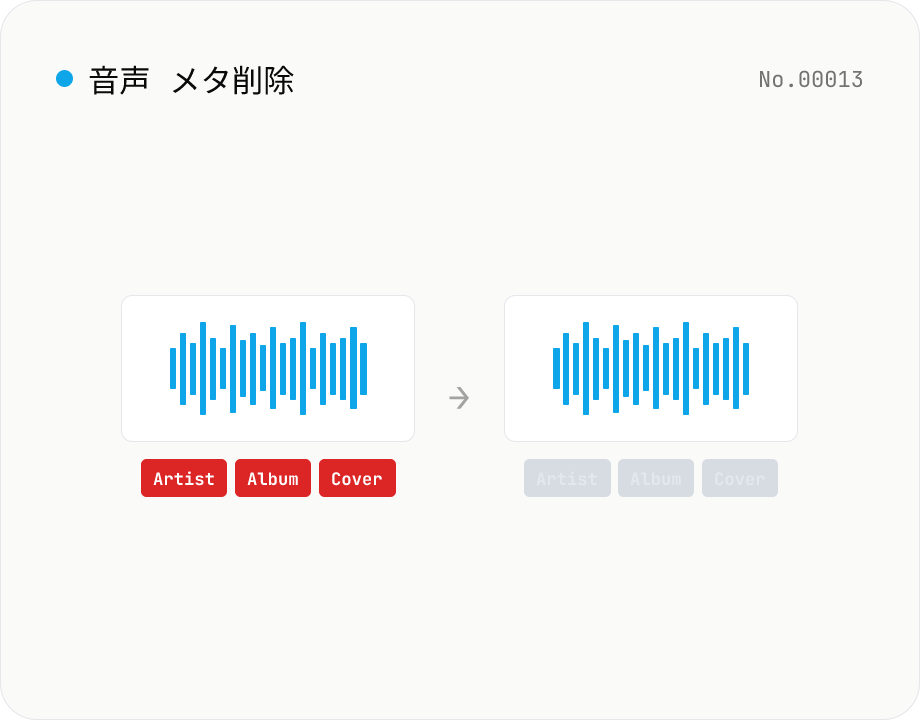
音声メタデータ削除 — ID3 / アートワーク一括
音声ファイルから ID3 / Vorbis comment / iTunes メタなどを ffmpeg.wasm でブラウザ内だけで削除します。コーデックそのままの stream copy なので再エンコードなし・拡張子そのまま。複数ファイル一括処理 + ZIP ダウンロード対応。
音声EXIF

Mid/Side エンコード — ステレオ L/R ↔ M/S 双方向変換
ステレオ音声を Mid (中央成分 = (L+R)/2) と Side (ステレオ差分 = (L-R)/2) の M/S 表現に変換、あるいは M/S 表現を L/R ステレオに戻します。M/S は DAW での mid-side EQ / mid-side コンプレッション (中央のボーカルだけ EQ する、Side だけリミッターをかけて広がりを抑える等) で使われる古典的な編集技法。本ツールは Mode 切替で L/R → M/S と M/S → L/R を選択でき、出力は WAV (16-bit PCM)。複数ファイル一括処理 + per-file ダウンロード + ZIP all 対応。可逆変換 (M+S = L, M-S = R) なので、外部 DAW で M 側だけ EQ → 本ツールで L/R に戻すワークフローが実現できます。音声はブラウザ内で完結。
音声変換
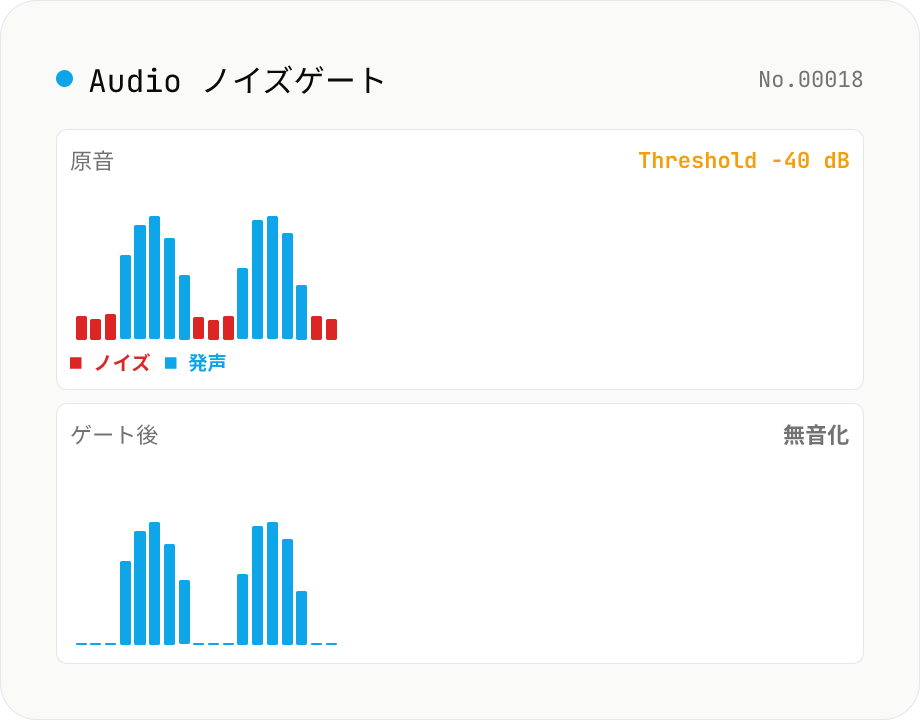
Audio ノイズゲート — threshold 以下を無音化、しゃべりとしゃべりの間のサーノイズを除去
Web Audio API を使ったソフトニーノイズゲート。**信号レベルがしきい値 (threshold) を下回ったら音量を 0 に絞る** 古典的ダイナミクスエフェクトです。ボーカル / ナレーション / 配信音声で、息継ぎの間に乗るマイクアンプのサーノイズや、PC ファン音、空調ノイズなどをクリーンに除去できます。パラメータは threshold (-80 〜 0 dB)、attack (0 〜 100 ms、ゲートが開く速さ)、hold (0 〜 500 ms、レベル復帰後にゲートが開きっぱなしになる時間)、release (10 〜 500 ms、ゲートが閉じる時間)、reduction (-100 〜 0 dB、しきい値以下のときの減衰量)。reduction = -100 dB なら完全無音、-20 dB なら静かにしてかすかに残す (= 完全無音だと不自然な場合に有効)。OfflineAudioContext + ScriptProcessor 相当の手書きエンベロープ追従でレンダリング → 16-bit PCM WAV を出力。複数ファイル一括処理 + ZIP 全件保存対応。`audio-compressor` (大きい音を抑える) と `audio-trim-silence` (前後の無音を削る) の中間を埋めるツール。すべてブラウザ内で完結。
音声
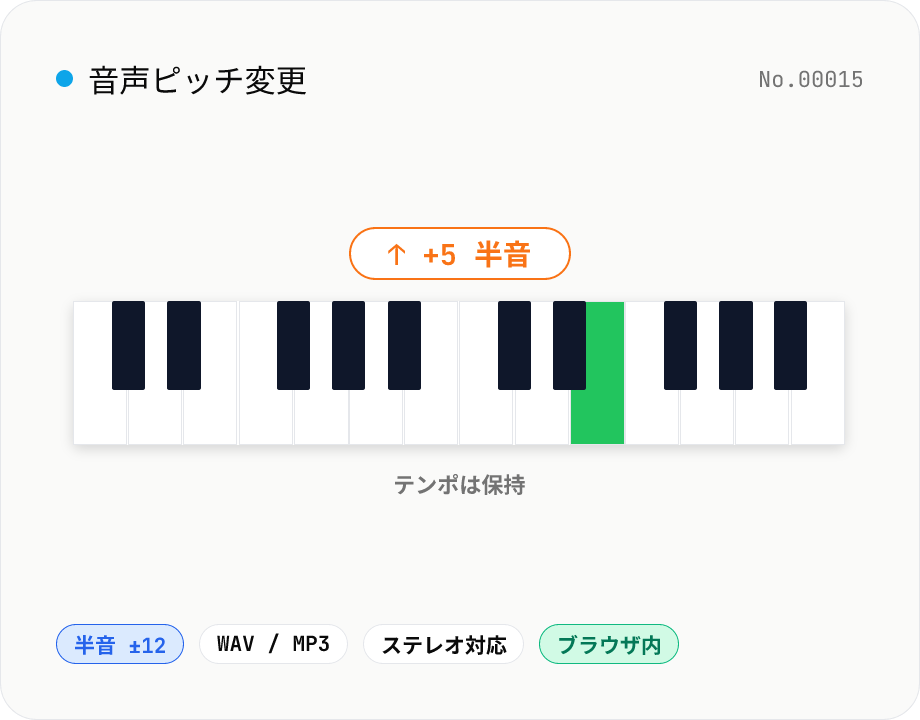
音声ピッチ変更 — テンポを保ったまま半音単位で上下
音声ファイル (MP3 / WAV / M4A / AAC / FLAC / OGG / Opus) のピッチをテンポを保ったまま半音単位 (±12 = 1 オクターブ) で上下できます。soundtouchjs を使い、Web Audio API のサンプルに対して SoundTouch ライブラリのピッチ変換を適用。カラオケのキー調整、語学教材のキー揃え、動画ナレーションのトーン調整、ボイスチェンジ的演出に。WAV / MP3 で書き出し、複数ファイル一括処理に対応。音声はブラウザ内でだけ処理され、外部に送信されません。
音声
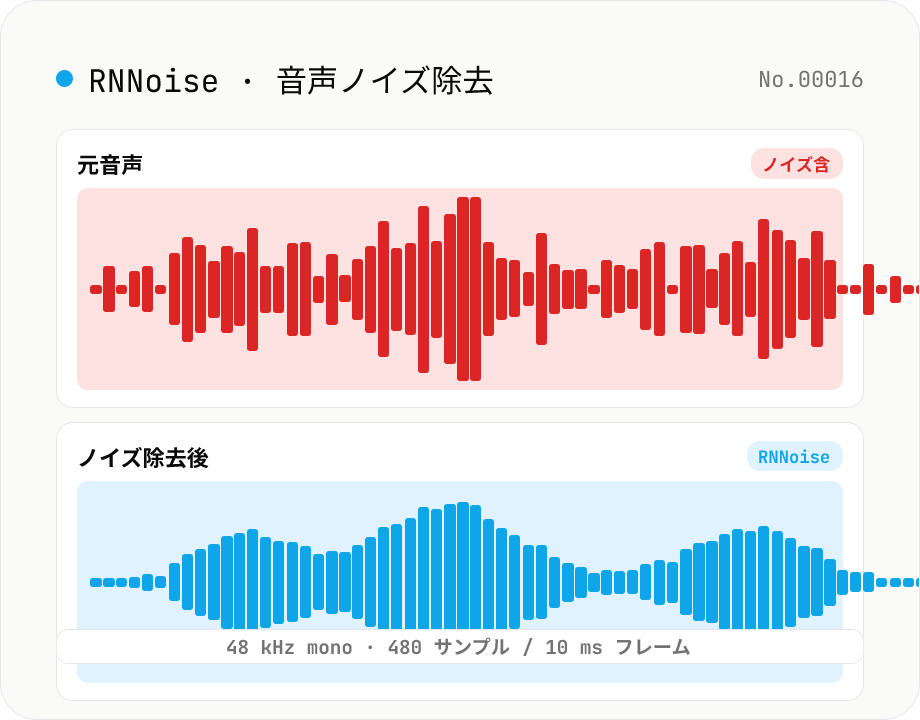
音声ノイズ除去 — RNNoise (機械学習) でホワイトノイズや空調音を抑制
アップロードした音声ファイルから空調音・キーボード打鍵音・ホワイトノイズ・ブレスノイズなどの背景ノイズをディープラーニングで抑制し、ノイズ除去後の WAV をダウンロードできます。Xiph.org の RNNoise (BSD-3-Clause) を WebAssembly で実行するため、音声データはサーバーに送信されず、すべてブラウザ内で処理されます。Web Audio API で 48 kHz mono にリサンプリングし、RNNoise (10 ms = 480 サンプルのフレーム単位) で発話確率 (VAD) と一緒に推論。学習済みモデルが声を保ちつつ背景音を消すので、Zoom 録画 / Web 会議録音 / ポッドキャスト原稿 / 配信切り抜きの後処理に向きます。
音声
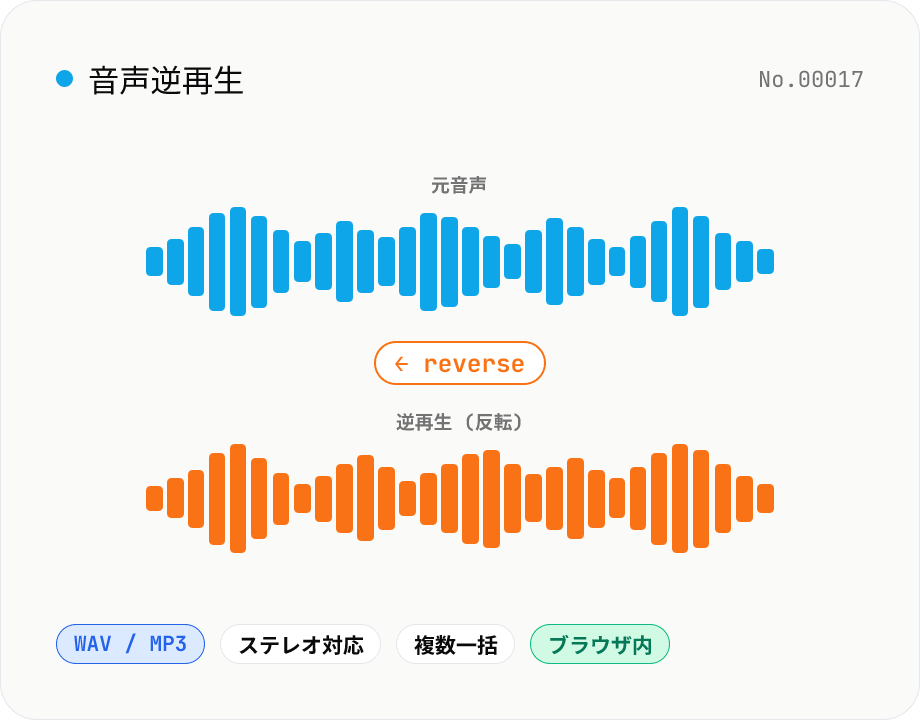
音声逆再生 — 音声を反転して WAV / MP3 で書き出し
音声ファイル (MP3 / WAV / M4A / AAC / FLAC / OGG / Opus) をブラウザ内で逆再生 (リバース) して、WAV または MP3 で書き出します。ASMR / 楽曲制作 / SNS 投稿 / 効果音作成に。Web Audio API でデコードしてサンプルを反転、ステレオはチャンネル別に正しく反転します。複数ファイル一括処理と ZIP まとめダウンロードに対応。元の音声データは外部に送信されません。
音声逆再生
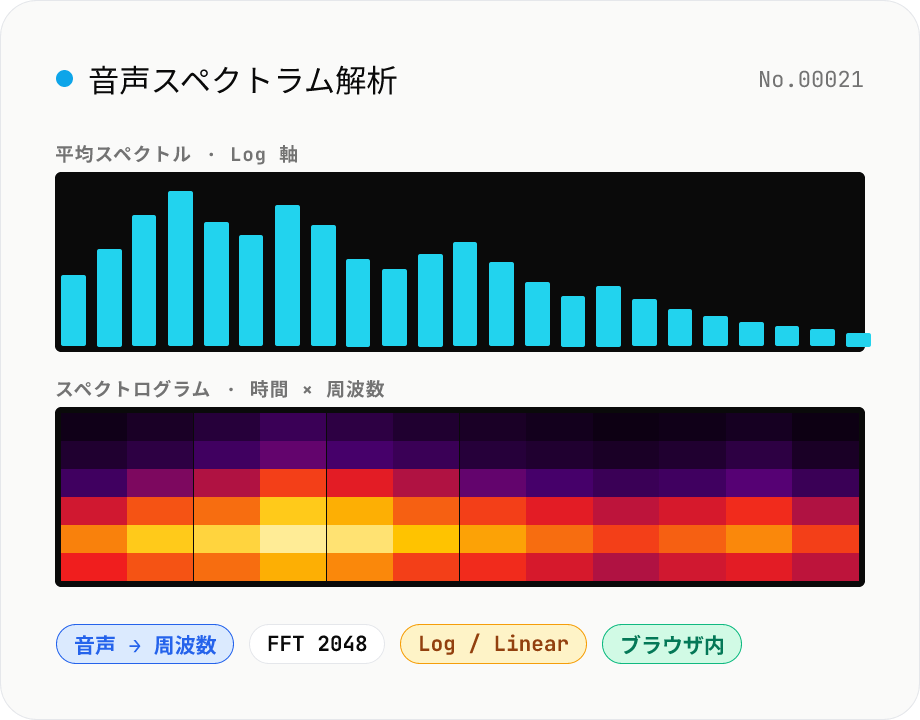
音声スペクトラム解析 — 周波数成分を可視化
音声ファイル (MP3 / WAV / M4A / FLAC / OGG / Opus) をドロップすると、ブラウザ内で FFT 解析を行い周波数スペクトルを可視化します。Mode 切替で、全体の平均スペクトル (周波数 vs 振幅) と、時間軸付きのスペクトログラム (時間 × 周波数 × 振幅) を切り替え可能。FFT サイズ (512 / 1024 / 2048 / 4096) と周波数軸 (Linear / Log) を選べます。マスタリング前のローエンド確認、ノイズ帯域の特定、楽器の倍音構成のチェック、講義音声の S/N 確認などに。Canvas を PNG ダウンロード、平均スペクトルは CSV エクスポート対応。音声はすべてブラウザ内で処理され、サーバーには送信されません。
音声抽出
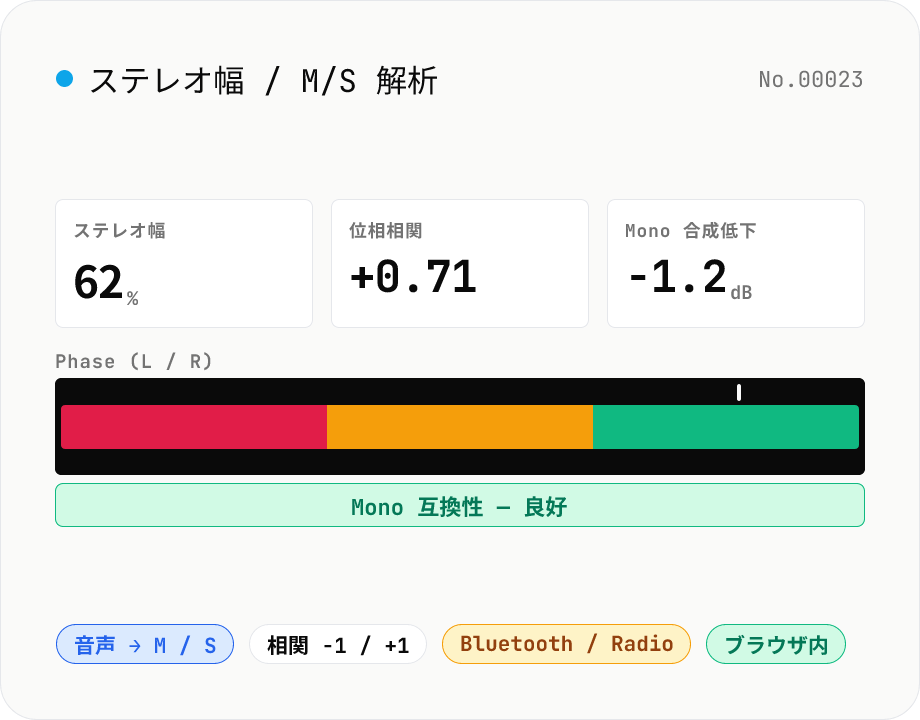
ステレオ幅 / M/S 解析 — 位相相関と mono 互換性チェック
ステレオ音声ファイル (MP3 / WAV / M4A / FLAC / OGG / Opus) をドロップすると、ブラウザ内で M/S 解析 (Mid = (L+R)/2、Side = (L-R)/2) を行い、ステレオ幅 (%) / 位相相関係数 (-1 〜 +1) / Side エネルギー (dB) / Mid エネルギー (dB) / モノラル合成時のレベル低下 (dB) を表示します。Bluetooth スピーカーや Spotify Mobile の mono 縮退、ラジオ放送、テレビの中央ダウンミックスで音が痩せる / 消える問題を事前に検出。位相相関がマイナスに振れている場合は phase issue の警告を出します。音声はブラウザ内で完結。
音声抽出
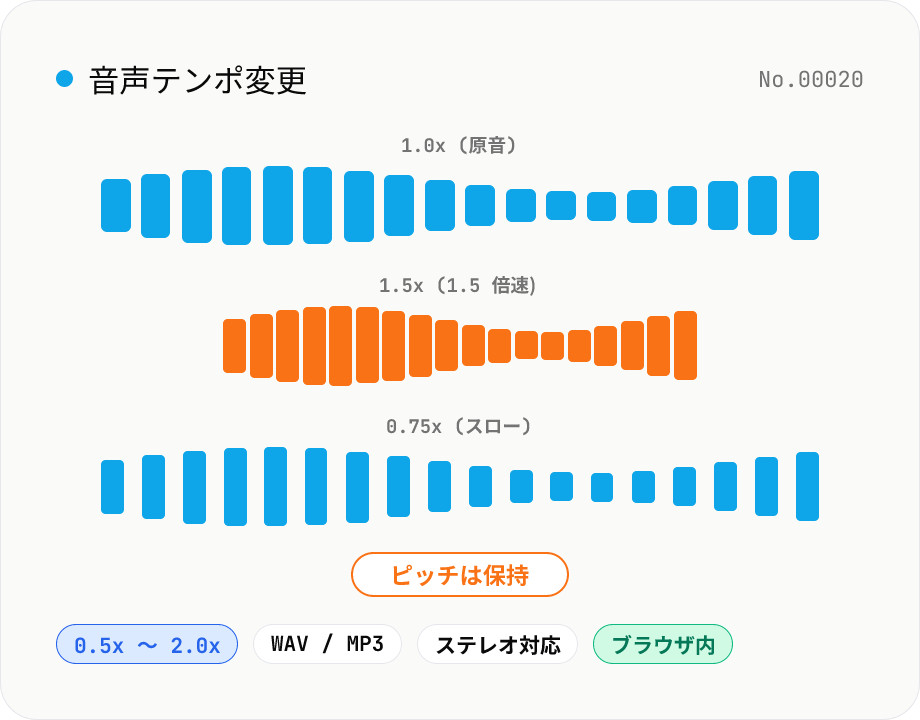
音声テンポ変更 — ピッチを保ったまま速度を変更
音声ファイル (MP3 / WAV / M4A / AAC / FLAC / OGG / Opus) のテンポ (速度) をピッチ (音の高さ) を保ったまま変更できます。soundtouchjs (SoundTouch ライブラリ) のタイムストレッチを使い、Web Audio API のサンプルに対して 0.5x (半分) 〜 2.0x (2 倍) で再エンコード。語学教材のスロー再生、楽器の練習用スピード変更、ナレーションの調整、ポッドキャストの倍速書き出しなどに。WAV / MP3 で出力、複数ファイル一括処理に対応。音声はブラウザ内でだけ処理され、外部に送信されません。
音声
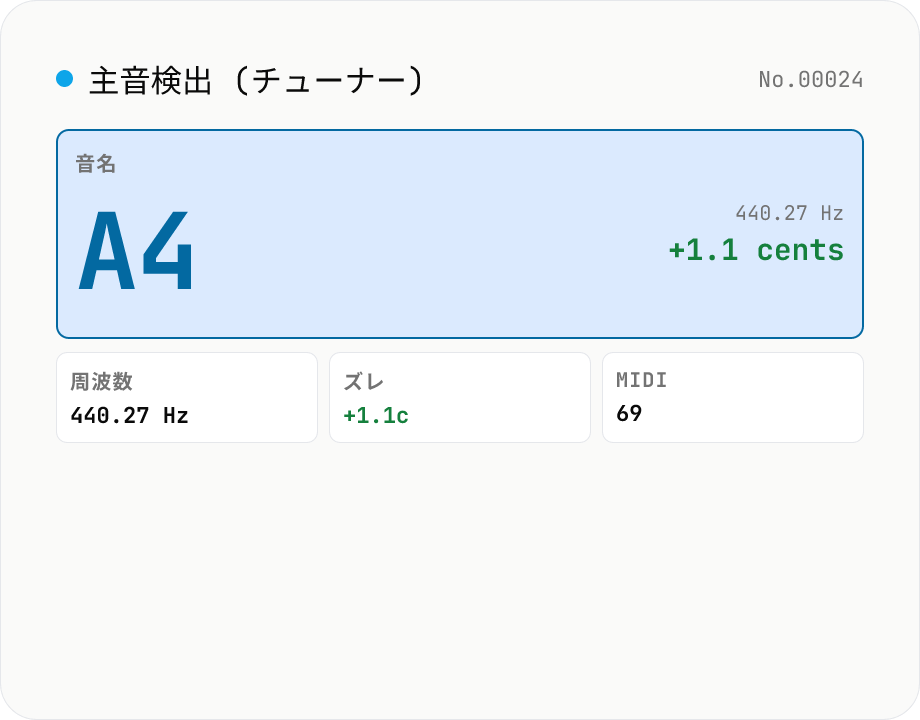
音声 主音検出 (チューナー) — FFT autocorrelation で音名 + cents ズレを表示
音声ファイルをドロップすると、ブラウザ内で **autocorrelation (自己相関) ベースのピッチ検出** を実行し、主音 (fundamental frequency) を **音名 (例: A4 / F#4)** と **cents 単位のズレ** に変換して表示します。**ギター / ベース / ボーカル / 笛 / ホイッスル** の楽器チューナー代わりに、録音した A 音 + 12 セント等を即座に確認できます。さらに **時間軸での主音遷移グラフ** を CSV 出力できるので、ボイスメモのピッチ追従 (intonation 練習) や、シンセサイザーで作った 1 トーンのチューニング微調整に。autocorrelation は短いトーン (50ms+) で高精度、複合音 (和音 / コーラス) は誤検出することがあります。`tone-generate` (任意の周波数のトーンを生成) の対称ツールで、本ツールは **既存音声 → 音名検出** に特化。`audio-spectrum` (周波数分布の可視化) とは異なり、主音 1 つに絞った出力。音声はサーバーに送信されません。
音声

音声文字起こし — Whisper で多言語対応
MP3 / WAV / M4A などの音声ファイルをアップロードして、ブラウザ内で動く Whisper で文字起こし。長尺ファイルは自動でチャンク分割します。音声・モデルともに外部送信なし。動作速度・対応モデルの大きさはお使いの端末スペック (CPU / GPU / メモリ) に依存します。
音声文字起こしAI抽出