
音声文字起こし — Whisper で多言語対応
MP3 / WAV / M4A などの音声ファイルをアップロードして、ブラウザ内で動く Whisper で文字起こし。長尺ファイルは自動でチャンク分割します。音声・モデルともに外部送信なし。動作速度・対応モデルの大きさはお使いの端末スペック (CPU / GPU / メモリ) に依存します。
使い方
モデルと言語を選び、音声ファイル (MP3 / WAV / M4A など) をドロップまたはピックして読み込みます。複数ファイルの一括処理に対応。「文字起こし」ボタンで処理を開始すると、長尺ファイルは自動的にチャンク分割されて順次解析されます。完了したらテキストをコピーまたは .txt として保存できます。初回のみモデルがダウンロードされます。
よくある質問
- 音声ファイルはサーバーに送信されますか?
- いいえ。Whisper モデルもブラウザ内で動かしており、ファイル・モデル・結果のいずれも端末外には出ません。
- どのくらいの長さまで処理できる?
- 端末メモリが許せば 1 時間以上のファイルも処理可能です。内部で 30 秒程度のチャンクに分割するので、メモリ使用量はチャンク単位に抑えられます。
- 動作が遅い場合は?
- 小さいモデル (tiny / base) に切り替えるか、WebGPU 対応ブラウザを使用してください。turbo モデルは WebGPU 環境で特に高速です。
- M4A や OGG にも対応?
- ブラウザの AudioContext がデコードできるフォーマットなら対応します。MP3 / WAV / M4A / OGG / FLAC など主要フォーマットは問題なく読み込めます。
- 結果のフォーマットは?
- 全文プレーンテキストです。タイムスタンプ付きの SRT / VTT が必要な場合はリアルタイム文字起こしツールの方が向いています。
類似のツール
音声リアルタイム文字起こし — マイク入力 Whisper
マイクから話した内容をブラウザ内で動く Whisper でリアルタイムに文字起こし。無音で区切ってチャット風に表示し、クリックでコピー。音声・モデルともに外部送信なし。動作速度・対応モデルの大きさはお使いの端末スペック (CPU / GPU / メモリ) に依存します。
音声フォーマット変換 — MP3 / WAV / M4A / OGG / FLAC
音声ファイルを mp3 / wav / m4a / ogg / flac へ変換します。ffmpeg.wasm が出力拡張子に応じてコーデックを選択して再エンコード。複数ファイル一括処理 + ZIP ダウンロード対応。ファイルはサーバーに送信されません。
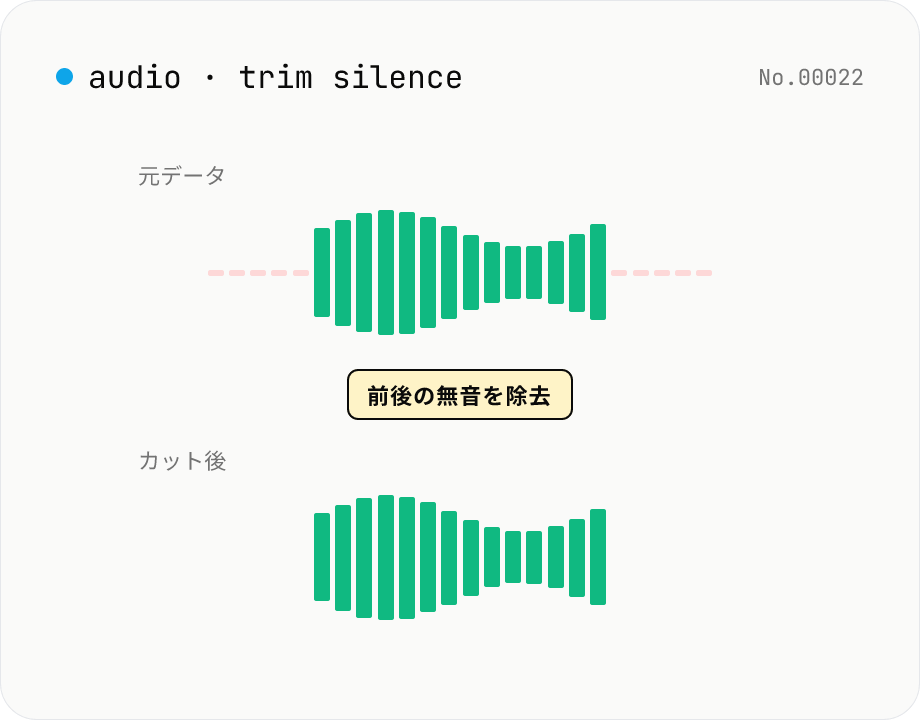
音声の無音カット — 前後の無音を自動で除去 (ffmpeg.wasm)
MP3 / WAV / M4A / AAC / OGG / OPUS / FLAC の先頭と末尾にある無音区間を ffmpeg.wasm の silenceremove フィルタでまるごと自動カットします。録音直後の数秒のしんとした部分、講演の出だしのもたつき、ポッドキャスト末尾の余韻が長すぎる場合などに。しきい値 (dB) と最小無音長 (秒) を細かく調整でき、前後どちらをカットするかも切り替えられます。複数ファイルを一括処理して ZIP でまとめて受け取れます。すべての処理はブラウザ内で完結し、ファイルは外部に送信されません。

MIDI ファイル情報ビューア
MIDI ファイル (.mid / .midi) をドロップして、テンポ・拍子・調号・PPQ・トラック数・トラック毎の楽器 (GM 楽器ファミリ)・ノート数・演奏時間・チャンネル・コピーライト/テキストイベントを一覧表示します。書き換えなしの読み取り専用、@tonejs/midi (MIT) でブラウザ内のみ実行。