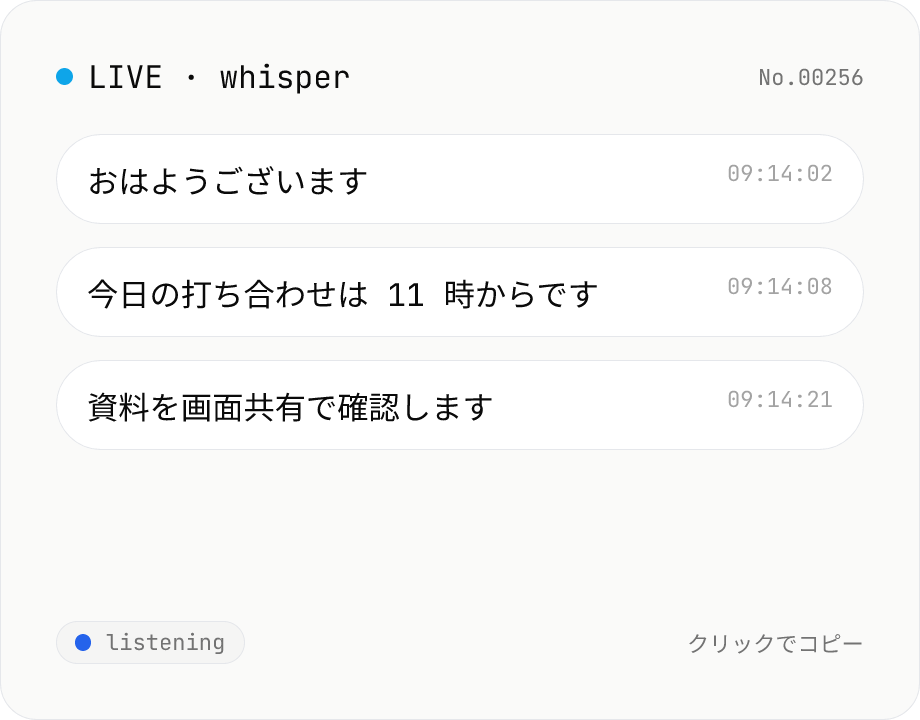
音声リアルタイム文字起こし — マイク入力 Whisper
マイクから話した内容をブラウザ内で動く Whisper でリアルタイムに文字起こし。無音で区切ってチャット風に表示し、クリックでコピー。音声・モデルともに外部送信なし。動作速度・対応モデルの大きさはお使いの端末スペック (CPU / GPU / メモリ) に依存します。
使い方
モデル (tiny / base / small / turbo) と言語を選んで「開始」を押すと、ブラウザがマイク許可を求めます。許可後はリアルタイムに音声が解析され、無音区間で文章が区切られてチャットバブルとして追加されます。各バブルをクリックでテキストコピー、「すべてコピー」で全文を取得できます。初回はモデルがブラウザにダウンロードされるので少し時間がかかります。
よくある質問
- 音声や生成テキストはサーバーに送信されますか?
- いいえ。Whisper モデルもブラウザ内 (transformers.js + ONNX Runtime Web) で動かしており、音声・モデル・結果のいずれも端末外には送信されません。
- なぜ最初は遅いのですか?
- 初回はモデルファイル (数十〜数百 MB) を端末にダウンロード&キャッシュするためです。2 回目以降はキャッシュ済みなので素早く起動します。
- どのモデルを選べばよい?
- 速度重視なら tiny / base、精度重視なら small / turbo。turbo は WebGPU が利用できる端末で特に有利。スペックが厳しい端末では大きいモデルが選べないことがあります。
- 認識精度が低いのはなぜ?
- モデルサイズの限界に加え、マイク品質・周囲ノイズ・話者の発話速度の影響を受けます。VAD 感度の調整、より大きいモデルへの切替で改善することがあります。
- 認識される言語は?
- 「言語」セレクタで指定した言語に最適化されます。確実に動かしたい場合は言語を明示してください。
類似のツール
ボイスレコーダー — MP3 / WAV ブラウザ録音
マイクから録音して MP3 / WAV としてダウンロードできます。すべてブラウザ内で処理。

音声文字起こし — Whisper で多言語対応
MP3 / WAV / M4A などの音声ファイルをアップロードして、ブラウザ内で動く Whisper で文字起こし。長尺ファイルは自動でチャンク分割します。音声・モデルともに外部送信なし。動作速度・対応モデルの大きさはお使いの端末スペック (CPU / GPU / メモリ) に依存します。
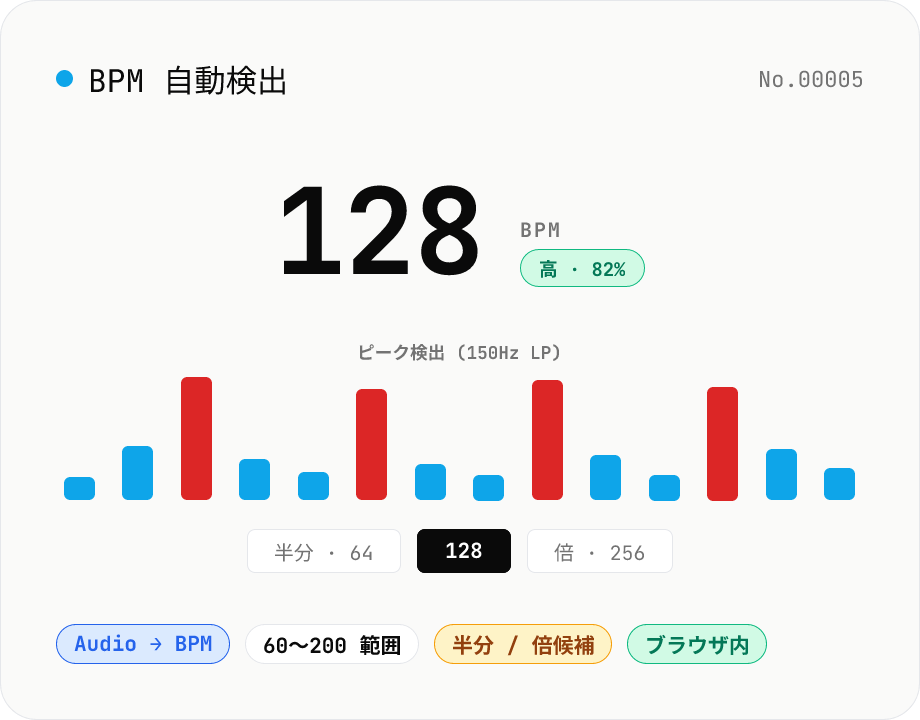
BPM 自動検出 — 音声から BPM を推定
音声ファイル (MP3 / WAV / M4A / FLAC / OGG) をドロップすると、Web Audio API のローパスフィルタ + ピーク検出 + ヒストグラム解析で曲の BPM を自動推定します。DJ ミックスの相手曲、サンプル素材のテンポ確認、踊りやランニングのテンポ合わせ、bpm-time-stretch で揃える前の参考値取得などに便利。半分・倍テンポの候補も併記するので、4 つ打ちで 60 BPM と出たけど実際は 120 BPM、のような誤検出も自分で判断できます。音声はブラウザ内で完結。
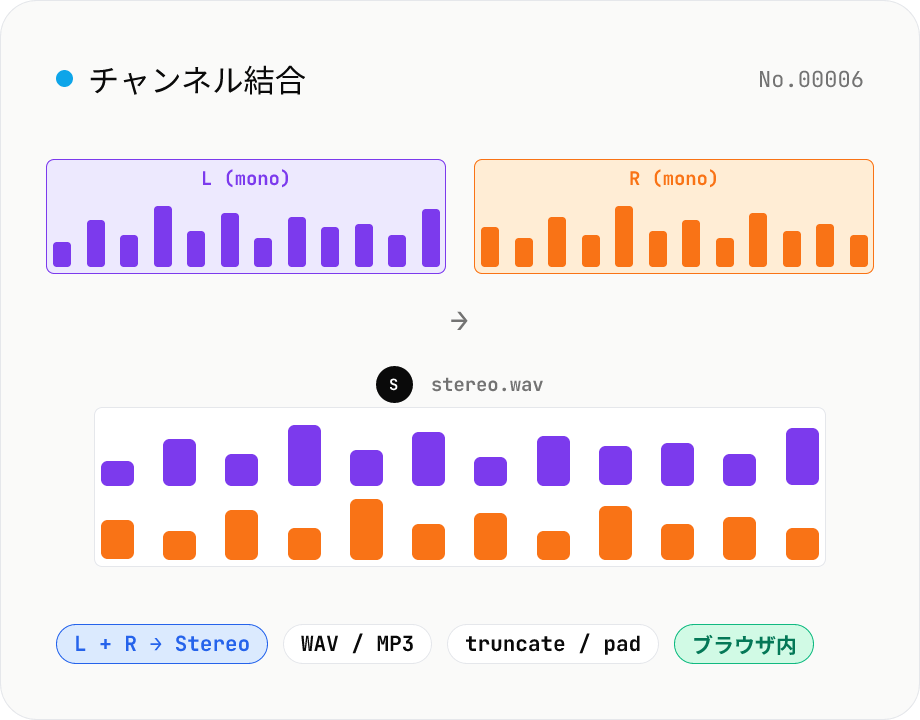
音声チャンネル結合 — 2 つのモノラルを L + R のステレオに
2 つのモノラル音声ファイル (MP3 / WAV / M4A / FLAC / OGG) を 1 つのステレオ音声に結合します。L チャンネルと R チャンネルを別々に渡すと、内部で interleave して 1 つの stereo WAV / MP3 として出力。インタビューの A 話者 / B 話者を別収録 → L / R に振り分けたい、片チャンネル素材から擬似ステレオを作りたい、audio-channel-split の逆操作で再合成したいときに使えます。長さが違う場合は短い方に合わせる / 長い方に合わせる (無音パディング) を選択可能。音声はブラウザ内で完結します。