音声 ツール
23 個のツール
録音・変換・編集・文字起こしなど、音声ファイルを扱うためのツール群。
タグ:
並び順:
1 ページあたり:
ツール一覧
23 / 23 件
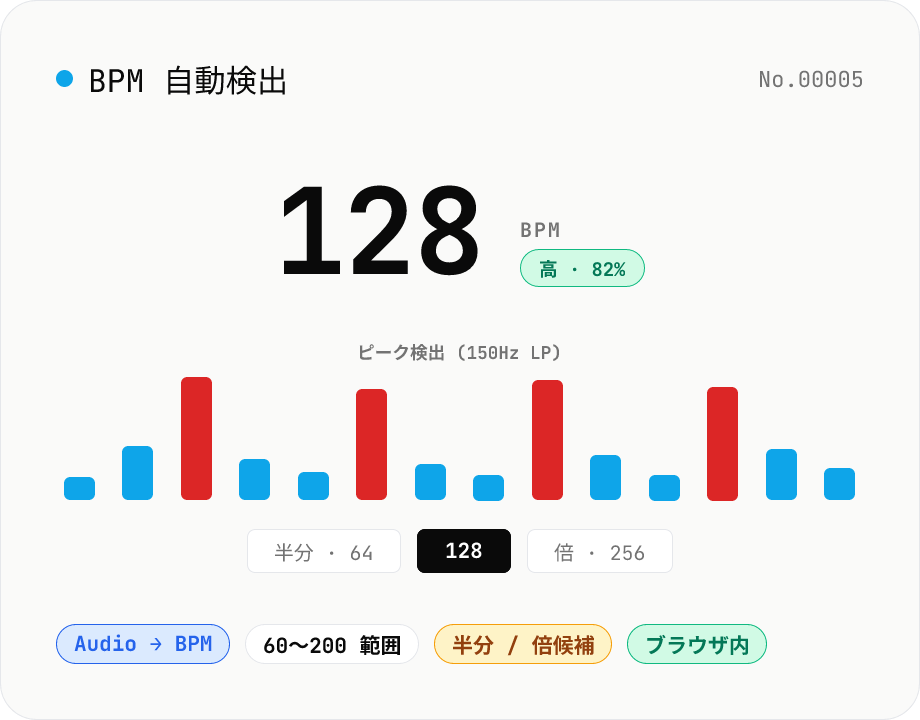
BPM 自動検出 — 音声から BPM を推定
音声ファイル (MP3 / WAV / M4A / FLAC / OGG) をドロップすると、Web Audio API のローパスフィルタ + ピーク検出 + ヒストグラム解析で曲の BPM を自動推定します。DJ ミックスの相手曲、サンプル素材のテンポ確認、踊りやランニングのテンポ合わせ、bpm-time-stretch で揃える前の参考値取得などに便利。半分・倍テンポの候補も併記するので、4 つ打ちで 60 BPM と出たけど実際は 120 BPM、のような誤検出も自分で判断できます。音声はブラウザ内で完結。
音声テンポ
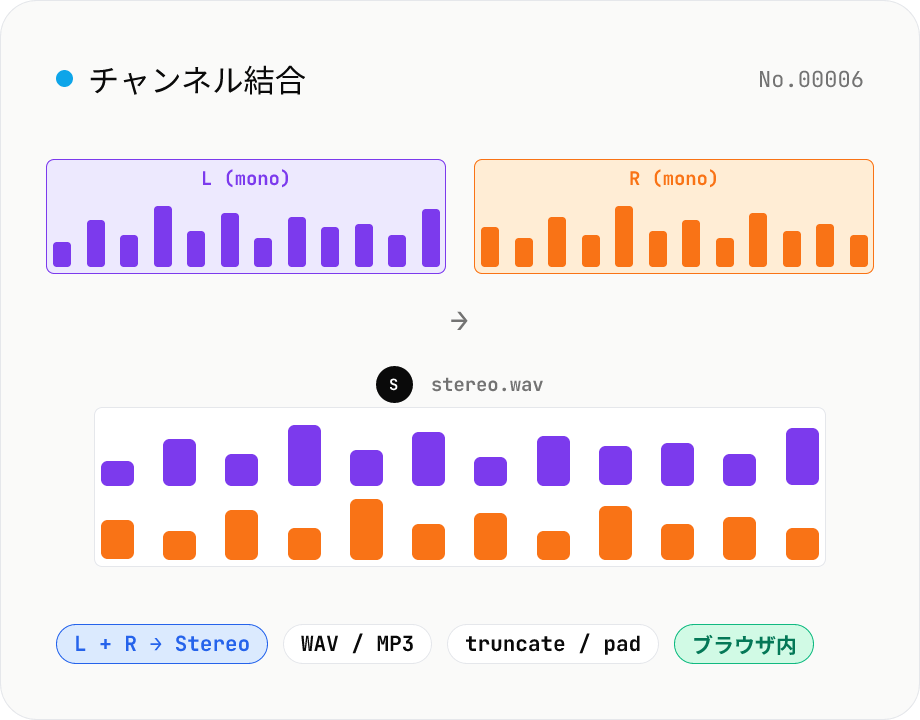
音声チャンネル結合 — 2 つのモノラルを L + R のステレオに
2 つのモノラル音声ファイル (MP3 / WAV / M4A / FLAC / OGG) を 1 つのステレオ音声に結合します。L チャンネルと R チャンネルを別々に渡すと、内部で interleave して 1 つの stereo WAV / MP3 として出力。インタビューの A 話者 / B 話者を別収録 → L / R に振り分けたい、片チャンネル素材から擬似ステレオを作りたい、audio-channel-split の逆操作で再合成したいときに使えます。長さが違う場合は短い方に合わせる / 長い方に合わせる (無音パディング) を選択可能。音声はブラウザ内で完結します。
音声結合
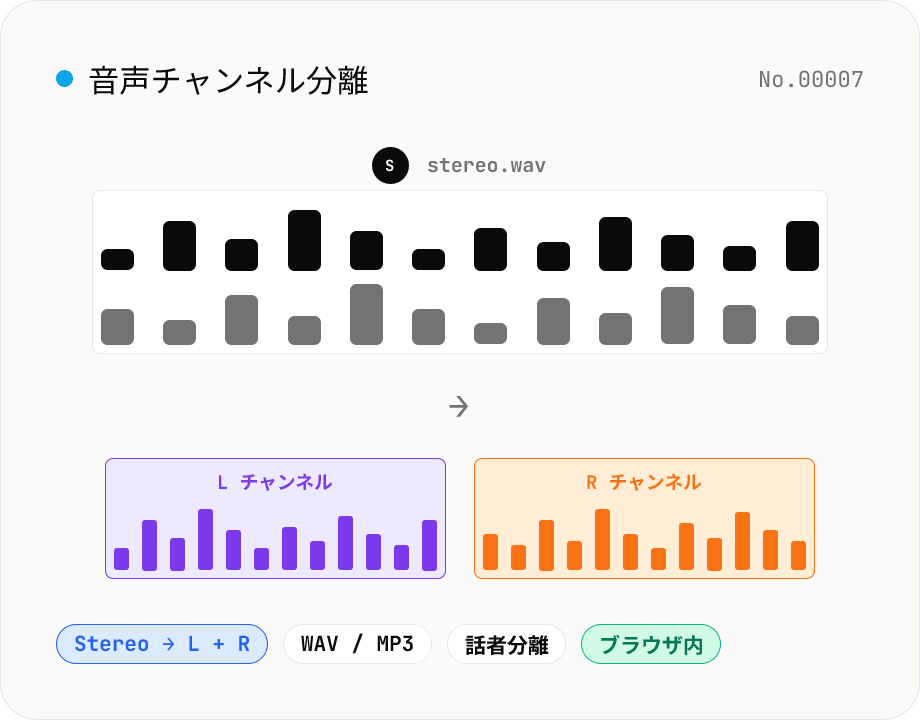
音声チャンネル分離 — ステレオ L / R を 2 つのモノラルに分割
ステレオ音声ファイル (MP3 / WAV / M4A / FLAC / OGG) を L (左) と R (右) の 2 つのモノラル WAV / MP3 として書き出します。社外録音 (インタビュー、口述記録、ZOOM 録音、ハンディレコーダー) で話者を L チャンネル / R チャンネルに分けて録ったときの分離編集、片チャンネルだけのノイズ除去、ステレオ素材から片側だけ DAW に取り込みたいときに最適。モノラル素材はそのまま 1 ファイル出力。音声はブラウザ内で完結します。
音声
音声フォーマット変換 — MP3 / WAV / M4A / OGG / FLAC
音声ファイルを mp3 / wav / m4a / ogg / flac へ変換します。ffmpeg.wasm が出力拡張子に応じてコーデックを選択して再エンコード。複数ファイル一括処理 + ZIP ダウンロード対応。ファイルはサーバーに送信されません。
音声変換

音声カット — 範囲指定で再エンコードなし切り出し
音声ファイルの特定区間を ffmpeg.wasm の stream copy で切り出します。再エンコードなし・拡張子そのまま。カット点はキーフレーム境界にスナップ。複数ファイル一括処理 + ZIP ダウンロード対応。
音声分割
音声フェード — フェードイン / フェードアウトを秒単位で適用
音声ファイルの先頭と末尾に任意秒のフェードイン / フェードアウト効果を入れます。ffmpeg.wasm の afade フィルタを使い、MP3 / WAV / M4A / OGG / FLAC など主要フォーマットに対応。複数ファイル一括処理 + ZIP ダウンロード対応。音声はサーバーに送信されません。
音声
音声結合 — 複数ファイルを 1 つに連結
複数の音声ファイルを ffmpeg.wasm の concat demuxer で結合します。ドラッグで並び替え。stream copy なので再エンコードなしですが、コーデック・サンプルレートが同じファイル同士のみ結合可能。
音声結合
音声メタデータ削除 — ID3 / アートワーク一括
音声ファイルから ID3 / Vorbis comment / iTunes メタなどを ffmpeg.wasm でブラウザ内だけで削除します。コーデックそのままの stream copy なので再エンコードなし・拡張子そのまま。複数ファイル一括処理 + ZIP ダウンロード対応。
音声EXIF
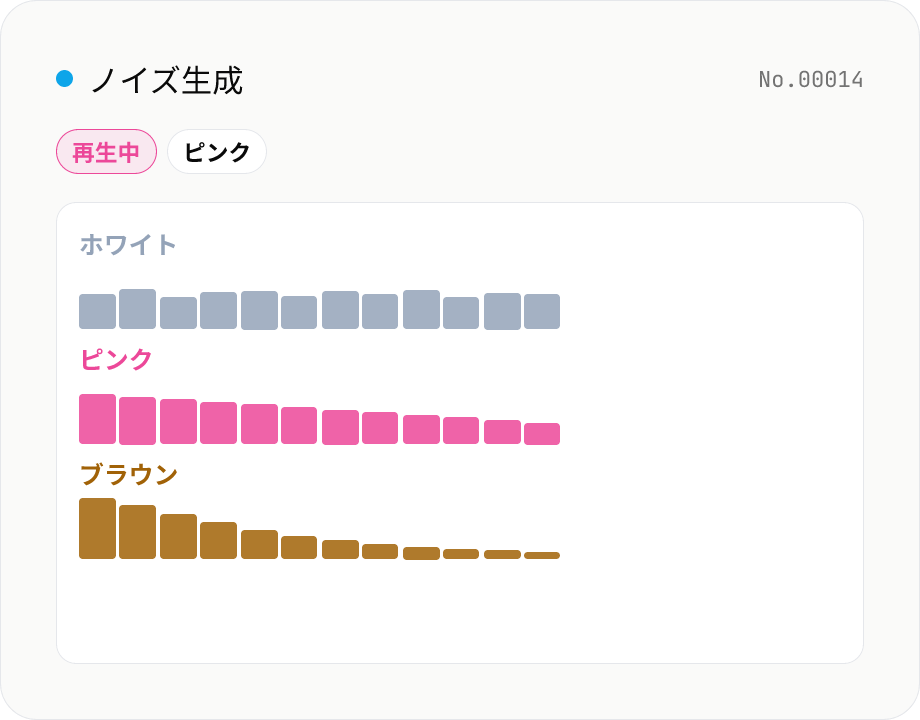
ノイズ生成 (ホワイト / ピンク / ブラウン)
ホワイトノイズ・ピンクノイズ・ブラウン (赤) ノイズをブラウザ内で合成してリアルタイム再生 + WAV ダウンロード。**ホワイト** は全周波数に均一なエネルギー (耳には高音寄り)、**ピンク** は 1 オクターブあたりエネルギー一定 (1/f スペクトル、自然界の音に近い)、**ブラウン** は -6 dB/oct で減衰する低音寄りスペクトル (海・滝の音に近い)。集中作業中のマスキング BGM、赤ちゃんの寝かしつけ、不眠対策、オーディオ機材のテストなどに。WAV (44.1 kHz / 16-bit / mono) で任意の長さ (0.5〜60 秒) をダウンロード可。すべてブラウザ内で完結し、サーバーへ送信しません。
生成
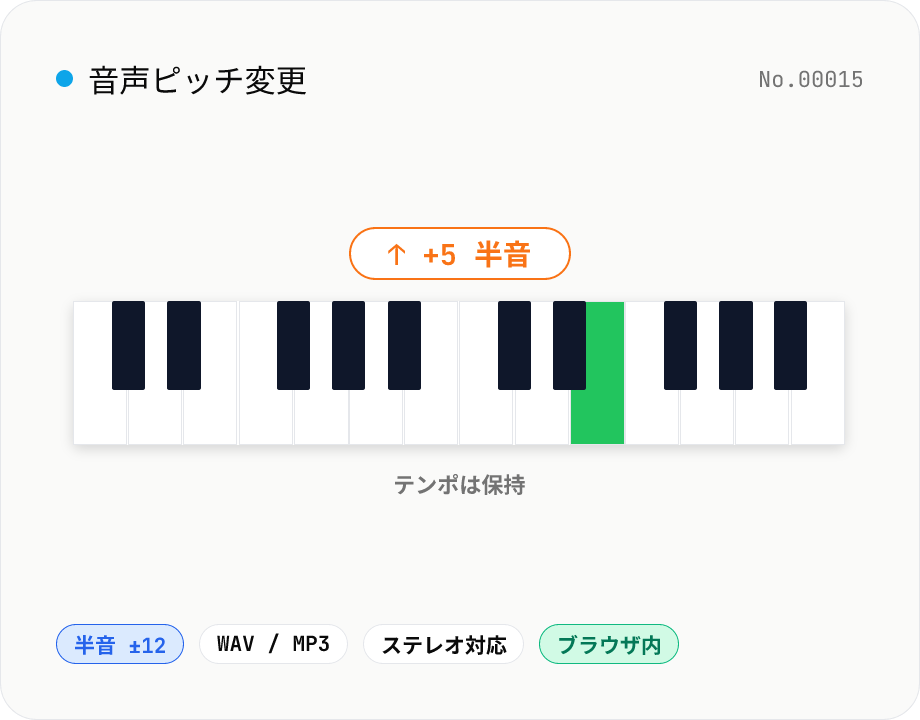
音声ピッチ変更 — テンポを保ったまま半音単位で上下
音声ファイル (MP3 / WAV / M4A / AAC / FLAC / OGG / Opus) のピッチをテンポを保ったまま半音単位 (±12 = 1 オクターブ) で上下できます。soundtouchjs を使い、Web Audio API のサンプルに対して SoundTouch ライブラリのピッチ変換を適用。カラオケのキー調整、語学教材のキー揃え、動画ナレーションのトーン調整、ボイスチェンジ的演出に。WAV / MP3 で書き出し、複数ファイル一括処理に対応。音声はブラウザ内でだけ処理され、外部に送信されません。
音声
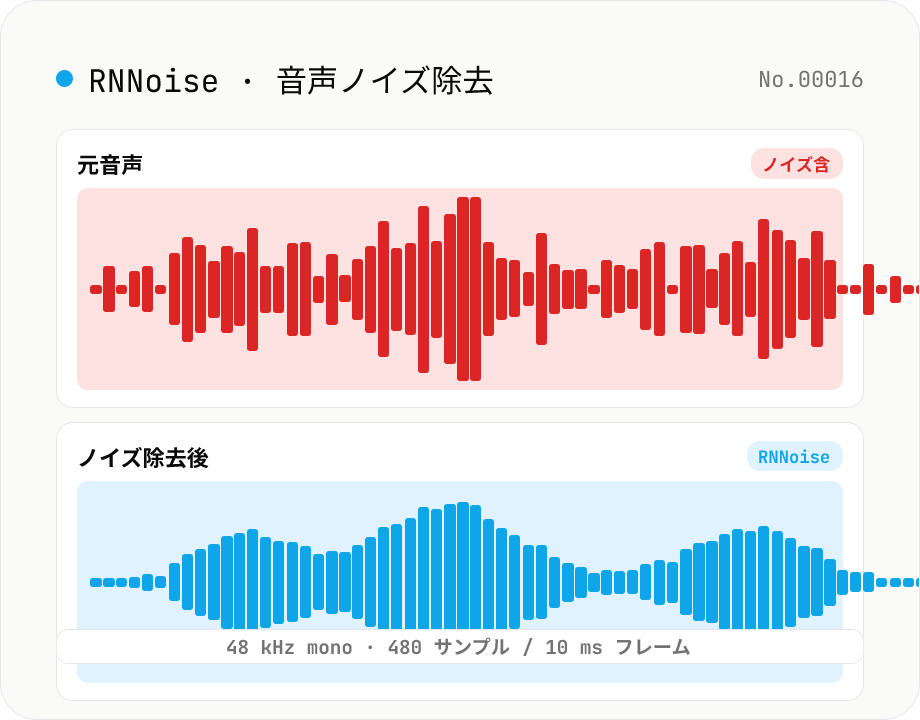
音声ノイズ除去 — RNNoise (機械学習) でホワイトノイズや空調音を抑制
アップロードした音声ファイルから空調音・キーボード打鍵音・ホワイトノイズ・ブレスノイズなどの背景ノイズをディープラーニングで抑制し、ノイズ除去後の WAV をダウンロードできます。Xiph.org の RNNoise (BSD-3-Clause) を WebAssembly で実行するため、音声データはサーバーに送信されず、すべてブラウザ内で処理されます。Web Audio API で 48 kHz mono にリサンプリングし、RNNoise (10 ms = 480 サンプルのフレーム単位) で発話確率 (VAD) と一緒に推論。学習済みモデルが声を保ちつつ背景音を消すので、Zoom 録画 / Web 会議録音 / ポッドキャスト原稿 / 配信切り抜きの後処理に向きます。
音声
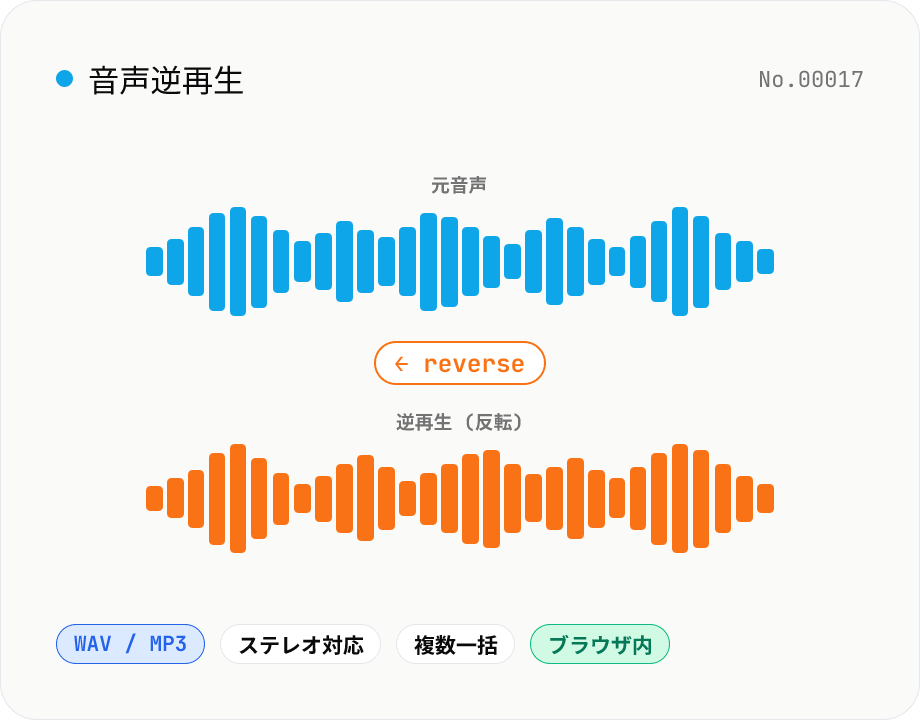
音声逆再生 — 音声を反転して WAV / MP3 で書き出し
音声ファイル (MP3 / WAV / M4A / AAC / FLAC / OGG / Opus) をブラウザ内で逆再生 (リバース) して、WAV または MP3 で書き出します。ASMR / 楽曲制作 / SNS 投稿 / 効果音作成に。Web Audio API でデコードしてサンプルを反転、ステレオはチャンネル別に正しく反転します。複数ファイル一括処理と ZIP まとめダウンロードに対応。元の音声データは外部に送信されません。
音声逆再生
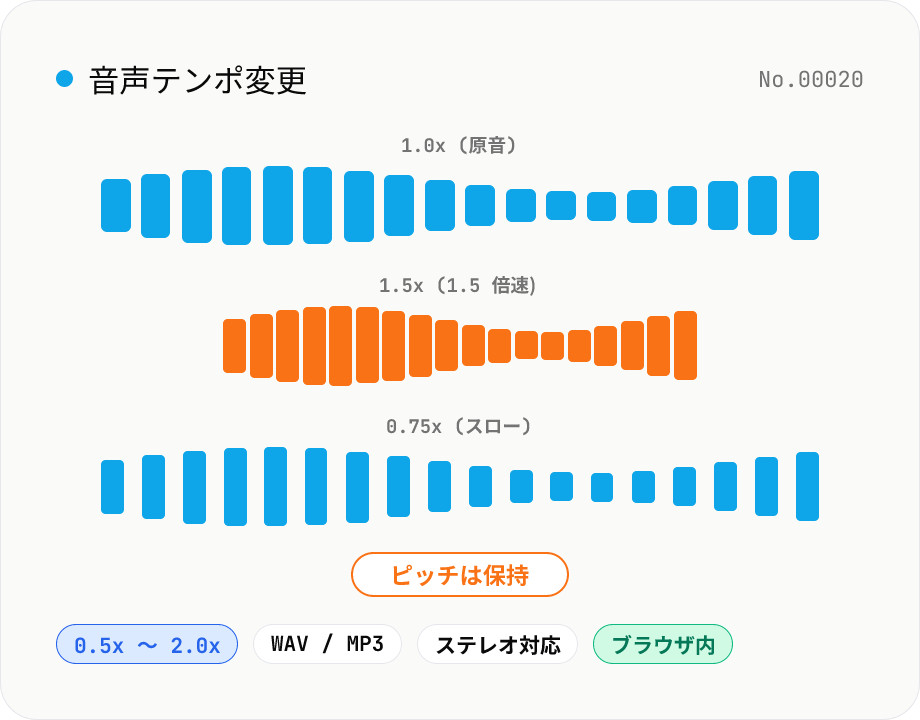
音声テンポ変更 — ピッチを保ったまま速度を変更
音声ファイル (MP3 / WAV / M4A / AAC / FLAC / OGG / Opus) のテンポ (速度) をピッチ (音の高さ) を保ったまま変更できます。soundtouchjs (SoundTouch ライブラリ) のタイムストレッチを使い、Web Audio API のサンプルに対して 0.5x (半分) 〜 2.0x (2 倍) で再エンコード。語学教材のスロー再生、楽器の練習用スピード変更、ナレーションの調整、ポッドキャストの倍速書き出しなどに。WAV / MP3 で出力、複数ファイル一括処理に対応。音声はブラウザ内でだけ処理され、外部に送信されません。
音声

音声文字起こし — Whisper で多言語対応
MP3 / WAV / M4A などの音声ファイルをアップロードして、ブラウザ内で動く Whisper で文字起こし。長尺ファイルは自動でチャンク分割します。音声・モデルともに外部送信なし。動作速度・対応モデルの大きさはお使いの端末スペック (CPU / GPU / メモリ) に依存します。
音声文字起こしAI抽出
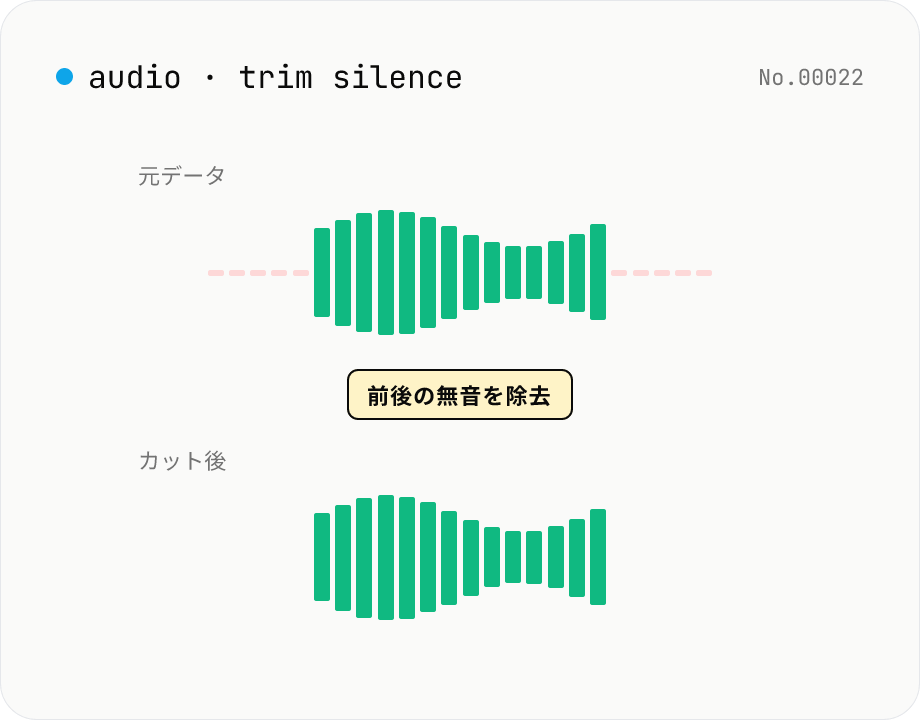
音声の無音カット — 前後の無音を自動で除去 (ffmpeg.wasm)
MP3 / WAV / M4A / AAC / OGG / OPUS / FLAC の先頭と末尾にある無音区間を ffmpeg.wasm の silenceremove フィルタでまるごと自動カットします。録音直後の数秒のしんとした部分、講演の出だしのもたつき、ポッドキャスト末尾の余韻が長すぎる場合などに。しきい値 (dB) と最小無音長 (秒) を細かく調整でき、前後どちらをカットするかも切り替えられます。複数ファイルを一括処理して ZIP でまとめて受け取れます。すべての処理はブラウザ内で完結し、ファイルは外部に送信されません。
音声抽出
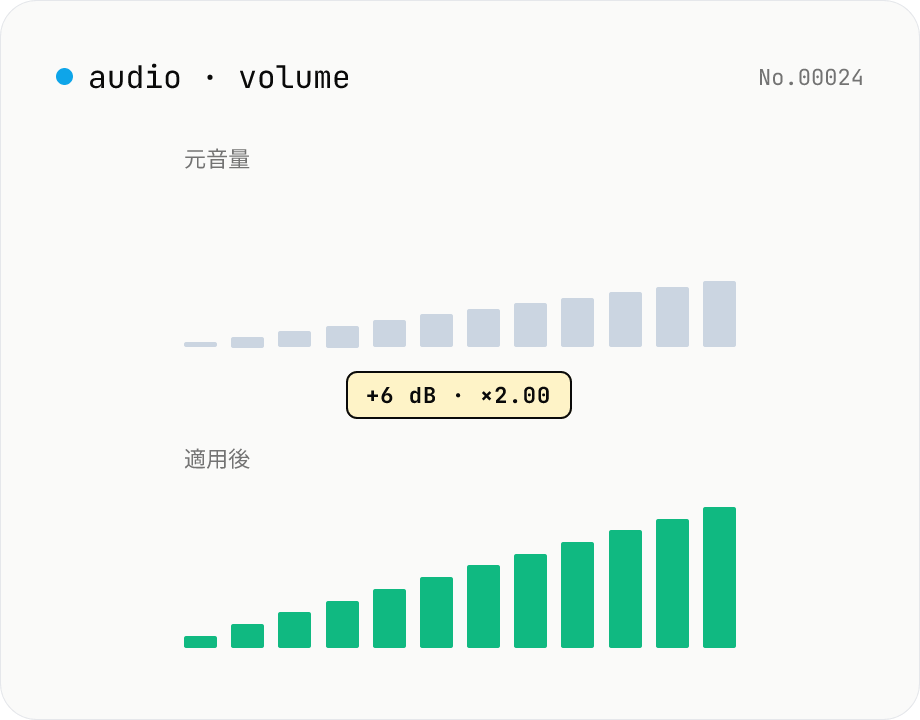
音量調整 — dB 変更 / ノーマライズ / 倍率
音声ファイルの音量を ffmpeg.wasm の volume フィルタで一括調整します。dB スライダ (-30〜+30 dB) または倍率 (×0.03〜×31.6) を選択。+6 dB ≒ 2 倍、−6 dB ≒ 半分。クリッピングを避けたいときはピークメーター代わりにマイナス側で試して比較を。複数ファイル一括処理 + ZIP ダウンロード対応。すべてブラウザ内で完結し、音声は外部に送信されません。
音声
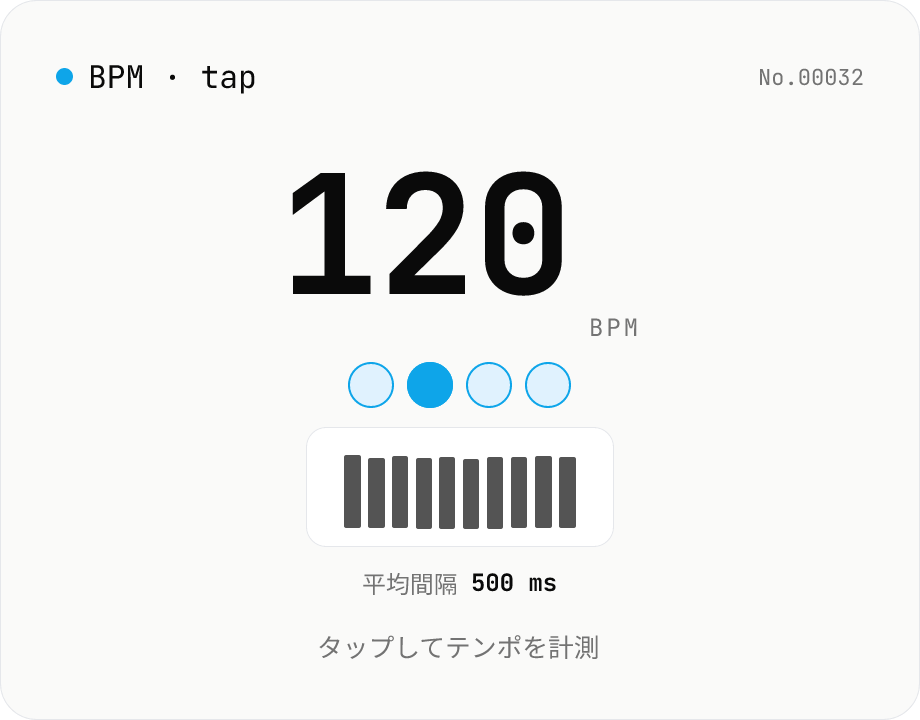
BPM タップ — ボタンを叩いてテンポを計測
リズムに合わせてボタン (またはスペースキー) を叩くと、直近のタップ間隔から BPM (1 分あたりの拍数) を中央値ベースで算出します。外れ値に強い median + IQR 安定度、最大過去 16 タップ、リセット / 履歴クリア対応。Web Audio による拍メトロノーム (任意) も同期再生可能。すべてブラウザ内で処理。
音声テンポ
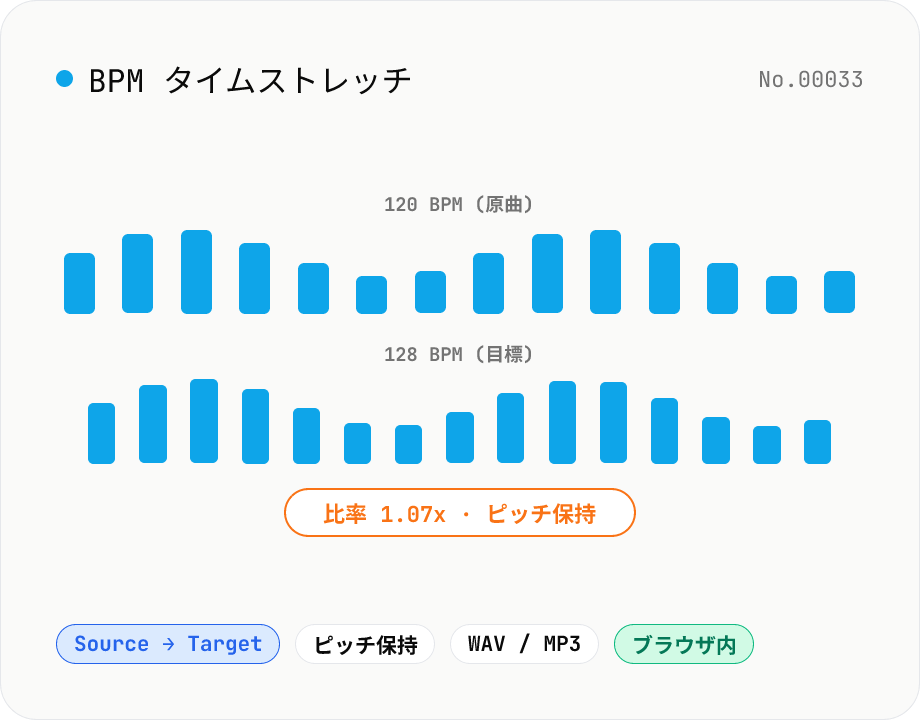
BPM タイムストレッチ — 現 BPM から目標 BPM へテンポを揃える
音声ファイルの現在の BPM と目標 BPM を入力すると、`tempo = target / current` の比率で soundtouchjs (SoundTouch ライブラリ) がテンポを変換します。ピッチは保持されるので、DJ ミックスや楽器練習でテンポを揃える、ポッドキャストの収録ペース統一、ダンスレッスンの BPM 調整などに最適。複数ファイルを違う目標 BPM で揃えたい場合も一括対応。WAV / MP3 出力、音声はブラウザ内で完結します。
音声テンポ

メトロノーム — BPM・拍子・音色を選んで拍を鳴らす
BPM (30〜300)・拍子 (1〜12 拍)・音色 (クリック / 木魚 / カウベル) を選んで Web Audio API で拍を鳴らすメトロノーム。1 拍目に高音のアクセントを付け、現在の拍をライブで視覚表示します。look-ahead スケジューラで高精度なタイミング (テンポずれ <1ms)、音量 / ミュート対応。bpm-tap で計測したテンポを再生するときの相棒に。すべてブラウザ内で生成、データは送信しません。
音声テンポ

MIDI ファイル情報ビューア
MIDI ファイル (.mid / .midi) をドロップして、テンポ・拍子・調号・PPQ・トラック数・トラック毎の楽器 (GM 楽器ファミリ)・ノート数・演奏時間・チャンネル・コピーライト/テキストイベントを一覧表示します。書き換えなしの読み取り専用、@tonejs/midi (MIT) でブラウザ内のみ実行。
音声抽出
このカテゴリについて
音声ファイルの変換・編集・解析を、すべてブラウザ内で行うためのツール群です。ffmpeg.wasm を中心に、MP3 / WAV / M4A / AAC / OGG / Opus / FLAC など主要な音声フォーマットを扱えます。
録音した音声をすぐに編集したい、社外秘のインタビュー音源を外部に送らずに整音したい、長い会議録音から無音部分だけを切り詰めたい、Whisper でブラウザ内文字起こしを行いたい、配布前にファイルのメタデータを除去したい、といった用途に向いています。
主な使い所
- ボイスメモの録音と、そのままの編集・MP3 化
- MP3 ↔ WAV ↔ M4A ↔ FLAC など音声形式の相互変換
- 音声の特定区間の切り出し・複数音声の結合
- 音量の調整・フェードイン / フェードアウトの付与
- 会議録音やナレーション収録から無音部分を自動カット
- ブラウザ内で完結する Whisper ベースの文字起こし
- 音声ファイルからメタデータ(タイトル・アーティスト等)を除去
このカテゴリのよくある質問
- アップロードせずに本当に音声を変換できるのですか?
- はい。ffmpeg.wasm(ffmpeg を WebAssembly 化したもの)がブラウザ内で動くため、音声ファイル自体がサーバーへ送信されることはありません。初回のみ ffmpeg.wasm 本体(約 30 MB)の読み込みがありますが、これはツールのコードであり、あなたの音声ファイルではありません。
- 対応している音声フォーマットは?
- ffmpeg が扱える主要フォーマットすべて(MP3 / WAV / M4A / AAC / OGG / Opus / FLAC / WebM など)に対応しています。MIDI ファイルの解析や音声録音は専用ツールでサポートしています。
- 音声の文字起こしもブラウザ内で行われますか?
- はい。voice-transcribe / audio-transcribe では Whisper モデルをブラウザに読み込み、文字起こしをローカルで実行します。音声データもテキスト結果も外部送信されません。モデルの初回ダウンロードのみネット接続が必要です。
- 編集できる音声の長さに制限はありますか?
- サーバー上限はありませんが、長尺音声は端末のメモリを多く使用します。安定して扱える目安は 1 時間程度までです。それ以上の音声は事前に audio-cut で分割しておくと処理しやすくなります。