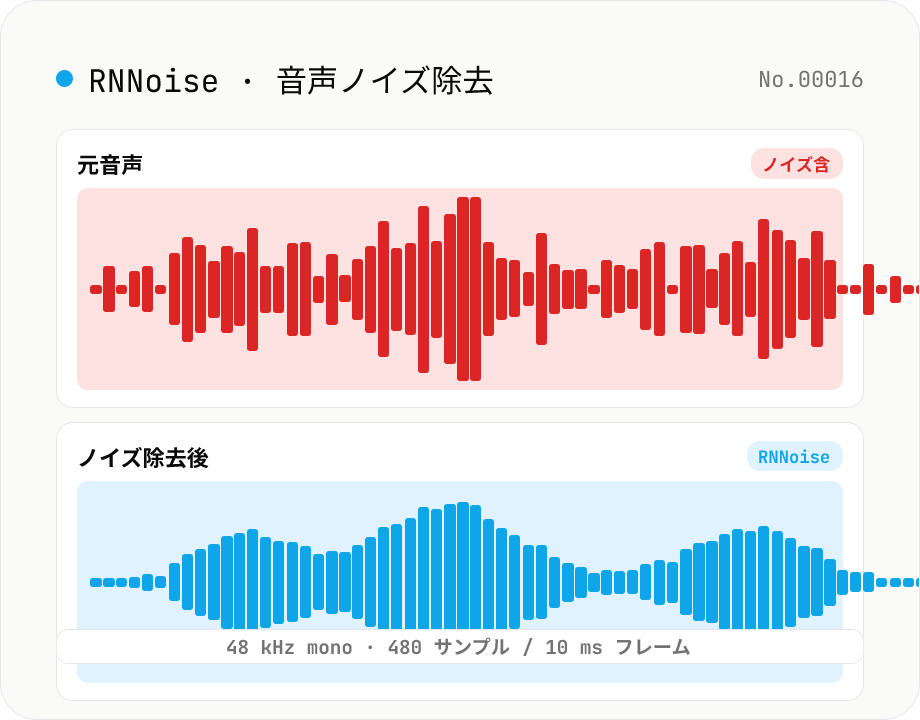
音声ノイズ除去 — RNNoise (機械学習) でホワイトノイズや空調音を抑制
アップロードした音声ファイルから空調音・キーボード打鍵音・ホワイトノイズ・ブレスノイズなどの背景ノイズをディープラーニングで抑制し、ノイズ除去後の WAV をダウンロードできます。Xiph.org の RNNoise (BSD-3-Clause) を WebAssembly で実行するため、音声データはサーバーに送信されず、すべてブラウザ内で処理されます。Web Audio API で 48 kHz mono にリサンプリングし、RNNoise (10 ms = 480 サンプルのフレーム単位) で発話確率 (VAD) と一緒に推論。学習済みモデルが声を保ちつつ背景音を消すので、Zoom 録画 / Web 会議録音 / ポッドキャスト原稿 / 配信切り抜きの後処理に向きます。
使い方
音声ファイルを選んで「ノイズ除去を実行」を押すと、まず RNNoise の WebAssembly モデル (約 100 KB) をブラウザにロードし、入力音声を 48 kHz mono にリサンプリングして 10 ms (= 480 サンプル) ごとに RNNoise で推論します。完了すると元音声とノイズ除去後の音声を並べて聴き比べでき、WAV (16-bit / 48 kHz / mono) としてダウンロードできます。Zoom 録画 / Web 会議録音 / ポッドキャスト原稿 / 配信切り抜きの後処理にどうぞ。
よくある質問
- どんなノイズが消えますか?
- RNNoise は『常に鳴っている背景音 (空調・PC ファン・ホワイトノイズ・ヒス・キーボード打鍵)』のような定常〜準定常ノイズに特に効きます。逆に『突発音 (くしゃみ・ドアバン・電話着信)』や『音楽 BGM』はあまり消えません。発話部分は学習済みモデルが声を識別して残すので、声の劣化はほとんど感じません。
- 対応している音声フォーマットは?
- MP3 / WAV / M4A (AAC) / OGG / FLAC など、ブラウザの `decodeAudioData` が読めるものすべて。出力は 16-bit / 48 kHz / mono WAV 固定です。ステレオ音声は処理前に mono にダウンミックスされます。
- RNNoise って何ですか? 通常のローパスフィルタや spectral subtraction とは違いますか?
- RNNoise は Xiph.org / Mozilla の Jean-Marc Valin が開発した、信号処理と機械学習を組み合わせた小型ノイズ抑制ライブラリ (~85 KB の重みファイル) です。BFCC + ゲート/帯域分割で 22 のクリティカルバンドごとに利得を推定する GRU ネットワークで、従来の spectral gating より声を保ったまま強いノイズ抑制ができます。BSD-3-Clause で公開されています。
- なぜ 48 kHz に強制リサンプリングされますか?
- RNNoise のモデルは 48 kHz mono / 10 ms フレーム (= 480 サンプル) に特化して学習されています。他のレートでは推論結果が大きく劣化するため、本ツールでは入力を必ず 48 kHz mono にリサンプリングしてから処理しています。
- VAD 平均 / 最大は何を示していますか?
- VAD = Voice Activity Detection の確率値 (0〜1)。RNNoise はノイズ抑制と同時に各フレームで『この瞬間に人の声が含まれている確率』を返します。平均値が高いほど発話中心のファイル、低いほど無音や音楽中心のファイルです。あくまで参考値で、ノイズ除去結果は VAD と独立に適用されます。
- 処理時間の目安は?
- 推論は 1 分の音声を数秒〜10 数秒で処理します (デバイス依存)。初回のみ WASM (~200 KB) と RNNoise モデル (~85 KB) のダウンロードと初期化に 1-2 秒かかります。以後は同タブ内では再ロードなしで動きます。
- 音声データはサーバーに送信されますか?
- いいえ。RNNoise の WebAssembly モデルもツール内で完結し、音声データはブラウザ外に一切送信されません。Web Worker 上で実行するので、UI もスムーズに動きます。
類似のツール
ボイスレコーダー — MP3 / WAV ブラウザ録音
マイクから録音して MP3 / WAV としてダウンロードできます。すべてブラウザ内で処理。
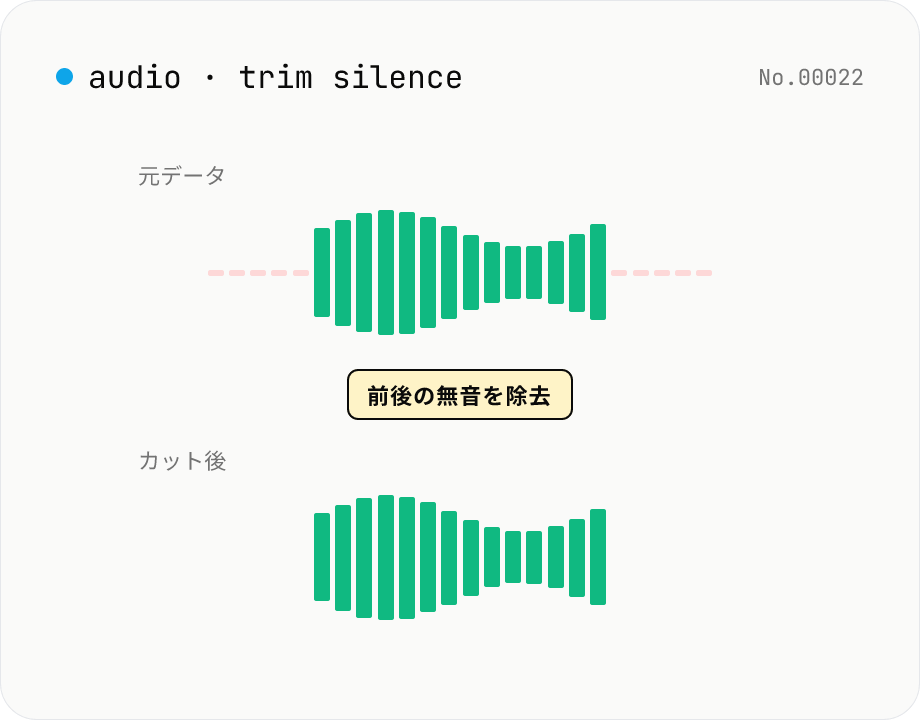
音声の無音カット — 前後の無音を自動で除去 (ffmpeg.wasm)
MP3 / WAV / M4A / AAC / OGG / OPUS / FLAC の先頭と末尾にある無音区間を ffmpeg.wasm の silenceremove フィルタでまるごと自動カットします。録音直後の数秒のしんとした部分、講演の出だしのもたつき、ポッドキャスト末尾の余韻が長すぎる場合などに。しきい値 (dB) と最小無音長 (秒) を細かく調整でき、前後どちらをカットするかも切り替えられます。複数ファイルを一括処理して ZIP でまとめて受け取れます。すべての処理はブラウザ内で完結し、ファイルは外部に送信されません。
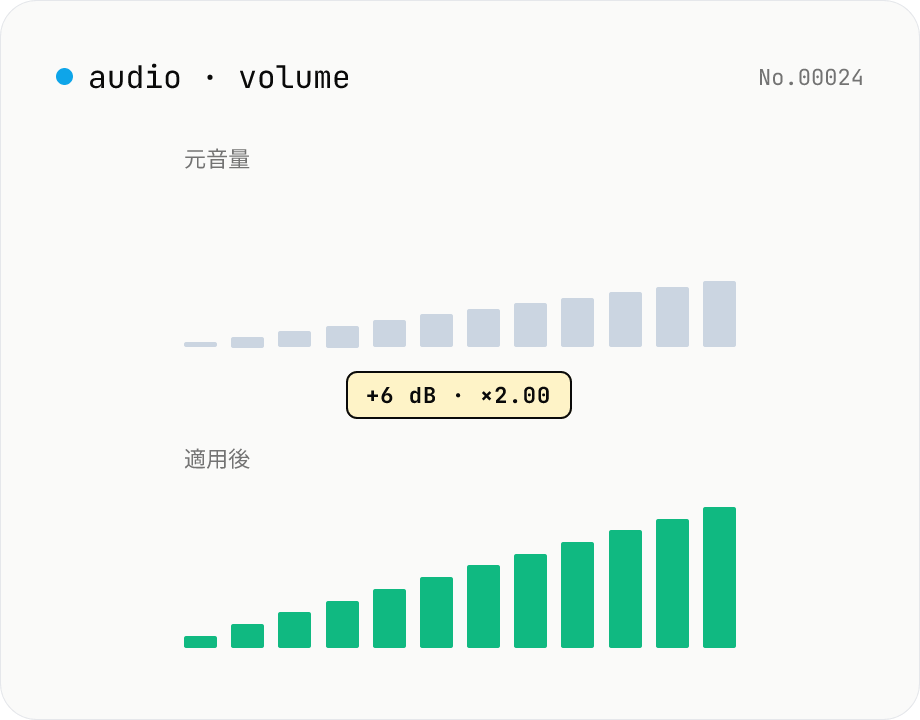
音量調整 — dB 変更 / ノーマライズ / 倍率
音声ファイルの音量を ffmpeg.wasm の volume フィルタで一括調整します。dB スライダ (-30〜+30 dB) または倍率 (×0.03〜×31.6) を選択。+6 dB ≒ 2 倍、−6 dB ≒ 半分。クリッピングを避けたいときはピークメーター代わりにマイナス側で試して比較を。複数ファイル一括処理 + ZIP ダウンロード対応。すべてブラウザ内で完結し、音声は外部に送信されません。
音声リアルタイム文字起こし — マイク入力 Whisper
マイクから話した内容をブラウザ内で動く Whisper でリアルタイムに文字起こし。無音で区切ってチャット風に表示し、クリックでコピー。音声・モデルともに外部送信なし。動作速度・対応モデルの大きさはお使いの端末スペック (CPU / GPU / メモリ) に依存します。