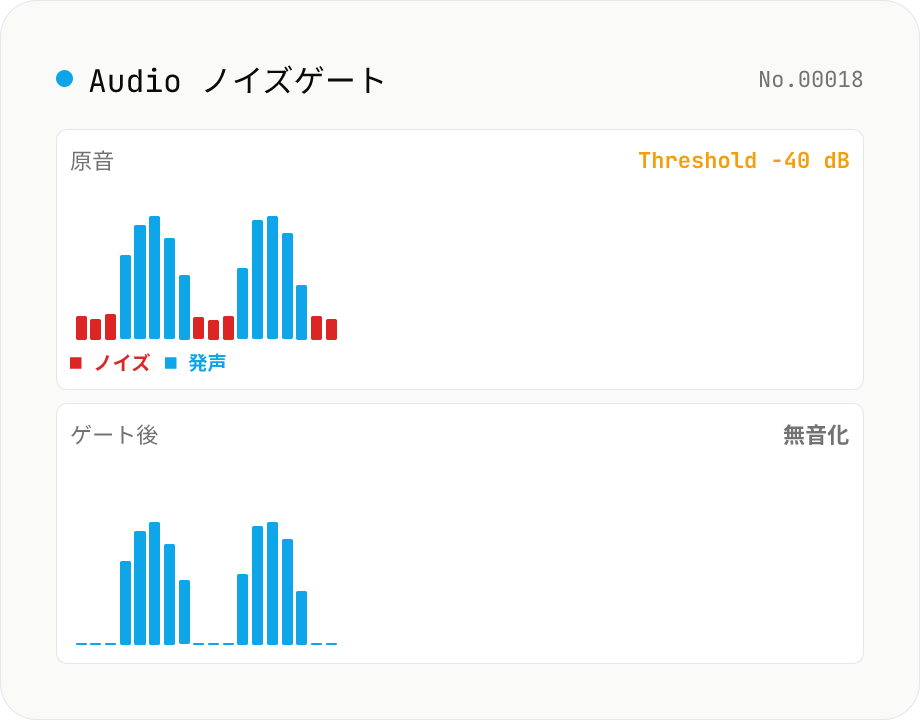
Audio ノイズゲート — threshold 以下を無音化、しゃべりとしゃべりの間のサーノイズを除去
Web Audio API を使ったソフトニーノイズゲート。**信号レベルがしきい値 (threshold) を下回ったら音量を 0 に絞る** 古典的ダイナミクスエフェクトです。ボーカル / ナレーション / 配信音声で、息継ぎの間に乗るマイクアンプのサーノイズや、PC ファン音、空調ノイズなどをクリーンに除去できます。パラメータは threshold (-80 〜 0 dB)、attack (0 〜 100 ms、ゲートが開く速さ)、hold (0 〜 500 ms、レベル復帰後にゲートが開きっぱなしになる時間)、release (10 〜 500 ms、ゲートが閉じる時間)、reduction (-100 〜 0 dB、しきい値以下のときの減衰量)。reduction = -100 dB なら完全無音、-20 dB なら静かにしてかすかに残す (= 完全無音だと不自然な場合に有効)。OfflineAudioContext + ScriptProcessor 相当の手書きエンベロープ追従でレンダリング → 16-bit PCM WAV を出力。複数ファイル一括処理 + ZIP 全件保存対応。`audio-compressor` (大きい音を抑える) と `audio-trim-silence` (前後の無音を削る) の中間を埋めるツール。すべてブラウザ内で完結。
使い方
音声ファイル (MP3 / WAV / M4A / AAC / FLAC / OGG / Opus) をドロップ。 threshold / attack / hold / release / reduction を調整するか、プリセット (ボーカル / 放送 / ゲーム配信 / ドラム / 完全無音) を選択。 WAV (16-bit PCM) で出力。複数ファイル時は全件 ZIP ダウンロード可能。 パラメータを変えると自動的に再処理します (元のファイルは保持)。
詳細解説
ノイズゲートをかける音声が持つ生活・業務文脈
ノイズゲートの用途を具体的に挙げると、ポッドキャスト収録の空調ノイズ除去、ゲーム実況配信のマイクハム音カット、会議録音のキーボード打鍵音抑制、ボーカル録音の息継ぎ処理、インタビュー音声のバックグラウンド雑音削除、などが代表的です。いずれも、音声の中にある発話の内容そのものが制作物や記録の核心です。
ノイズゲートは「小さい音を消す」処理ですが、消す前の音声ファイルは発話のすべてを含んでいます。これを外部サービスにアップロードして処理させると、目的は「ノイズを消すこと」でも、実際には「会話や収録内容をサーバーに渡す」という結果になります。
配信音声・業務録音をクラウドで処理するリスク
音声処理サービスのビジネスモデルには、無料で処理を提供しながらアップロードデータを活用するものがあります。会議録音やポッドキャスト原稿、ゲーム配信の事前テスト音声は、商業的な価値や機密性を持つことがあります。パラメータを変えるたびに再処理を依頼する操作感は、そのつど音声を送信しているという実感を薄れさせます。
個人レベルでも、声は生体的な識別情報です。録音の内容が機微でなくても、音声が誰のものであるかはデータとして残ります。近年の声紋認識・音声合成技術の進歩を考えると、不必要な声データの外部送信は、数年前より大きなリスクを持つようになっています。
Web Audio API のサンプルレベル処理がブラウザ内だけで動く
このツールは Web Audio API の decodeAudioData で音声をデコードし、threshold / attack / hold / release の各パラメータで定義されたゲートロジックをサンプル単位で実行します。具体的には、各サンプルの RMS を計算してゲート状態 (open / closed) を決定し、attack / release の傾きで滑らかに遷移させ、reduction の値だけ音量を下げることで「完全無音」ではなく「ソフトゲート」の再現も可能にしています。この処理全体がブラウザのメモリ内で完結します。
DevTools の Network タブを開きながらパラメータを変えて再処理を何度行っても、音声関連のリクエストは発生しません。実装コードは GitHub で公開されており、ゲートロジックの状態遷移を含めて確認できます。
ゲート処理の前後でするべき確認と組み合わせ
ノイズゲートは「threshold より小さい音を消す」処理なので、threshold の設定が重要です。ノイズフロアより 3〜6 dB 高い値に設定すると、声が入っていない区間だけが消えます。audio-loudness-lufs でノイズフロアの dB を事前に計測しておくと、threshold 設定の根拠が数値で出ます。先頭末尾の無音だけ消したい場合は audio-trim-silence のほうがクリーンに処理できます。
ノイズゲートと audio-compressor の組み合わせは、配信・ポッドキャスト音声の定番仕上げです。ゲート → コンプの順にかけると、ノイズが消えた上で声の音量ムラも均一化されます。最終的な音量確認は audio-loudness-lufs と audio-true-peak でブラウザ内チェックを。
エンベロープ追従と Threshold / Attack / Hold / Release の関係
ノイズゲートの中身は、入力信号のレベルを追跡する エンベロープフォロワー と、それを threshold と比較してゲインを 1.0 (open) か reduction (closed) に切り替える状態機械の組み合わせです。本ツールはサンプルごとに |sample| (絶対値) または短い RMS 窓 (~5 ms) でレベルを推定し、attack (open → 目標ゲイン到達までの時間、0〜100 ms) と release (closed → 目標ゲイン到達までの時間、10〜500 ms) のエクスポネンシャル係数 exp(-1 / (sampleRate · attackTime)) でゲインを滑らかに補間します。hold (0〜500 ms) は信号がしきい値を下回ってもすぐにゲートを閉じない待機時間で、これがないと発話の途中の小さな間 (ブレス間や子音の谷) で頻繁にゲートが開閉して「チャタリング」と呼ばれる不自然な切れが発生します。
reduction パラメータの -100 dB は完全無音を意味し、-20 dB は「小さく残す」設定で、ナレーションや会話の自然な間を保ちながらノイズを目立たなくします。シネマ的な音響では完全無音は不自然に感じられることが多く、室内のごく薄い暗騒音 (room tone) を残す目的で -15〜-20 dB の reduction が好まれます。エンベロープ追従の単位は典型的に RMS (連続音の知覚に近い) か Peak (瞬間的なトランジェントに反応する) で、本ツールは絶対値ベースに近い Peak-like 検出を採用しています。これによりキーボード打鍵音 (1〜2 ms の鋭いトランジェント) も適切にゲートで処理できます。
用途別の設定パターンとサイドチェイン的応用
ポッドキャスト・ナレーションでは threshold = -45〜-35 dB / attack = 5〜10 ms / hold = 100〜200 ms / release = 150〜300 ms / reduction = -20 dB が一般的な出発点です。発話のダイナミクスを保ちながら、空調・ファン・キーボード音を -20 dB 程度に抑える設定です。ゲーム配信のマイク処理では threshold = -50 dB / attack = 2 ms / release = 80 ms のような速い設定で、メカニカルキーボードの打鍵音を即座にカットします。ボーカル録音では、子音 (s, t, k) のアタックを潰さないように attack = 1〜3 ms の極短設定を選びます。
audio-compressor との組み合わせ順序は gate → compressor が原則で、コンプレッサーが小さい音 (=ノイズフロア) を持ち上げる前にノイズを消しておく必要があります。逆順だとノイズもコンプで持ち上げられて、SN 比が悪化します。サイドチェイン応用としては、ダッキング (BGM をナレーションに合わせて自動で下げる) のような効果も理論的には可能ですが、本ツールは内部信号 (self-keyed) のみをサポートし、外部キー入力には対応しません。落とし穴として、(a) threshold をノイズフロアより下に設定するとノイズが除去されない、(b) 上に設定しすぎると小声や子音の谷が消える、(c) release が短すぎるとゲート開閉が聴感に出る、(d) ステレオ素材では L/R を独立にゲート処理すると位相がずれて mono 互換性が悪化する (本ツールは L/R 同期処理を採用)、などがあります。配信前は audio-loudness-lufs でラウドネス、audio-true-peak で True Peak を確認してから書き出すのが標準的なワークフローです。
よくある質問
- ノイズゲートはコンプレッサーとどう違う?
- コンプレッサーは「**大きい音を抑える**」(threshold を超えた信号を圧縮)、ノイズゲートは「**小さい音を無音にする**」(threshold を下回ったら attenuate)。マイクの息継ぎ・エアコン音・ファン音などをクリーンに除去する用途はノイズゲート。声を均一化する用途はコンプレッサー。両方を直列に使うのが配信音声の定番。
- audio-trim-silence との違いは?
- trim-silence は**冒頭と末尾の連続無音**を 1 回だけカット (ffmpeg `silenceremove` 相当)。本ツールは **発話中の連続的に走るゲート**で、ナレーション中の息継ぎ・無音区間でも常時 threshold 以下を無音化します。配信や Podcast の「ずっと薄く乗ってるサーノイズを消す」用途は本ツール。
- threshold の選び方は?
- 1. 静かな部分 (無音時のノイズフロア) を audio-loudness-lufs などで dB 確認。2. ノイズフロアより 3〜6 dB 上を threshold に。例: ノイズフロア -50 dB → threshold -45 dB。低すぎると声が切れ、高すぎるとノイズが残る。実音で耳確認しながら調整するのが定石。
- hold って何のためにある?
- 発話中の自然な無音 (子音間の短い無音、間など) でゲートが閉じてしまうと「途切れ途切れの音」になる。hold は信号がしきい値を下回ってからもゲートを開けっぱなしにする時間で、典型値は 50〜200 ms。話し方が早ければ短く、ゆっくりなら長めに。
- reduction = -100 dB と -20 dB の違いは?
- -100 dB は完全無音 (実質 0)。-20 dB は元の音量から 20 dB だけ下げた「ソフトゲート」。完全無音にすると音が不自然 / 急に切れる印象になることがあるので、放送業界では -10 〜 -20 dB の「室音 (room tone)」を残すのが好まれます。
- なぜ出力が WAV のみ?
- ブラウザネイティブで圧縮形式 (MP3 / AAC) を再エンコードできないためです。WAV → MP3 が必要なら、本ツールで処理した WAV を `audio-convert` (MP3 化対応) にかけてください。
- データは外部に送信されますか?
- いいえ。Web Audio API のみで完結します。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール
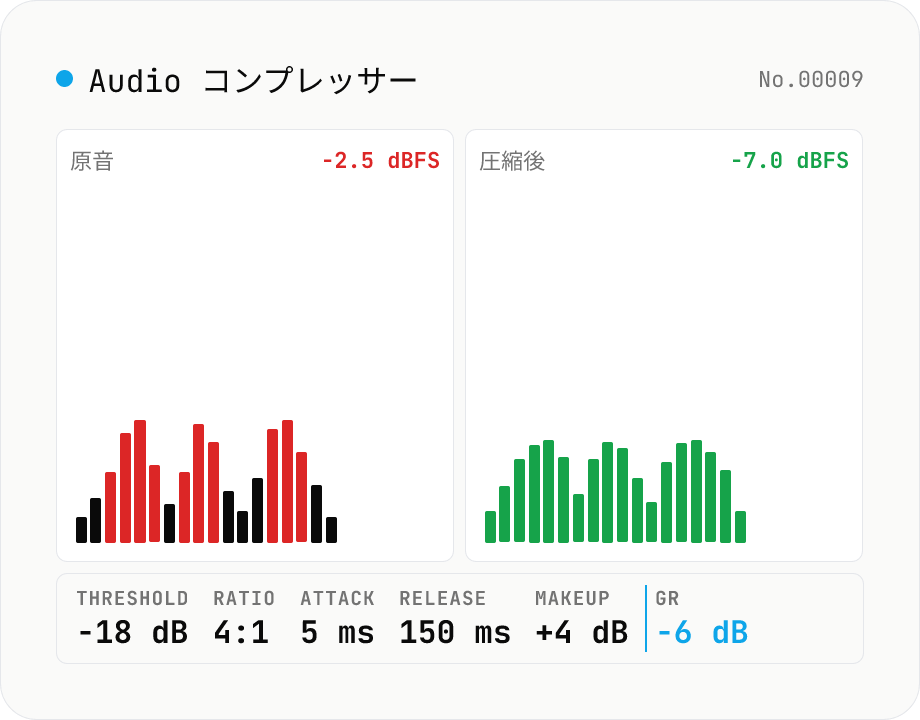
Audio コンプレッサー — threshold / ratio / attack / release を調整して WAV 出力
Web Audio API の DynamicsCompressorNode を使い、しきい値 (threshold) を超えた音声を比率 (ratio) で圧縮する古典的ダウンワード・コンプレッサーです。threshold (-60 〜 0 dB)、ratio (1:1 〜 20:1)、attack (0 〜 1 秒)、release (0 〜 1 秒)、knee (0 〜 40 dB) に加えて、補正の makeup gain (0 〜 24 dB) も指定可能。OfflineAudioContext でオフライン (= リアルタイムより高速) レンダリングし、16-bit PCM の WAV を生成します。ボーカル・ナレーション・ポッドキャストの音量を整える、ドラムを潰す、マスターでピーク抑制する、など用途は広いです。`audio-volume` (一括ゲイン)、`audio-loudness-lufs` (測定だけ)、`audio-true-peak` (測定だけ) と棲み分け。複数ファイル一括処理 + per-file WAV / ZIP 全件保存対応。音声はブラウザ内でだけ処理され、サーバーには送信されません。
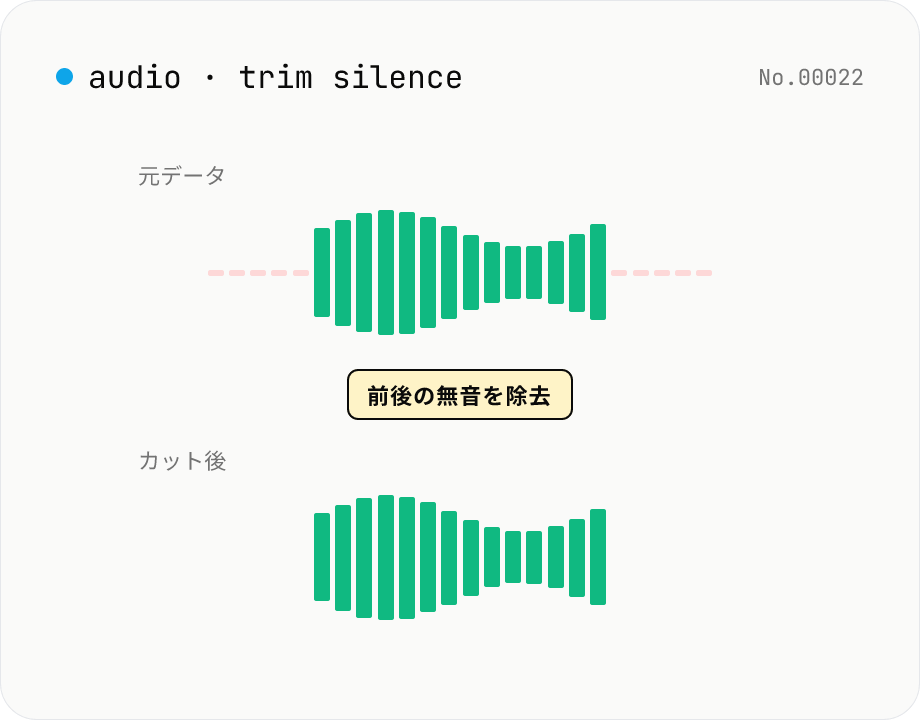
音声の無音カット — 前後の無音を自動で除去 (ffmpeg.wasm)
MP3 / WAV / M4A / AAC / OGG / OPUS / FLAC の先頭と末尾にある無音区間を ffmpeg.wasm の silenceremove フィルタでまるごと自動カットします。録音直後の数秒のしんとした部分、講演の出だしのもたつき、ポッドキャスト末尾の余韻が長すぎる場合などに。しきい値 (dB) と最小無音長 (秒) を細かく調整でき、前後どちらをカットするかも切り替えられます。複数ファイルを一括処理して ZIP でまとめて受け取れます。すべての処理はブラウザ内で完結し、ファイルは外部に送信されません。
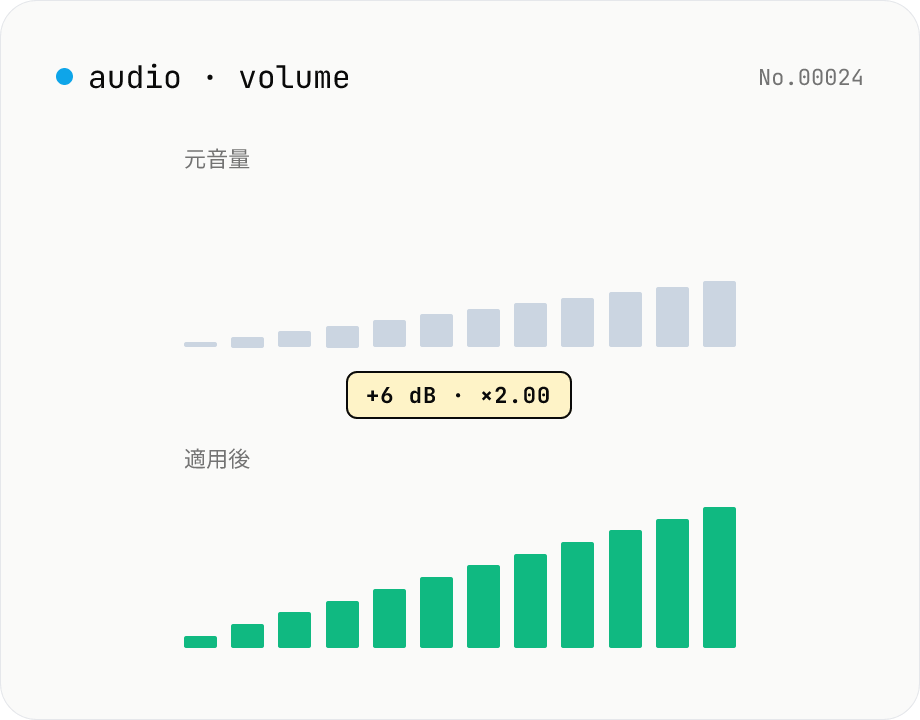
音量調整 — dB 変更 / ノーマライズ / 倍率
音声ファイルの音量を ffmpeg.wasm の volume フィルタで一括調整します。dB スライダ (-30〜+30 dB) または倍率 (×0.03〜×31.6) を選択。+6 dB ≒ 2 倍、−6 dB ≒ 半分。クリッピングを避けたいときはピークメーター代わりにマイナス側で試して比較を。複数ファイル一括処理 + ZIP ダウンロード対応。すべてブラウザ内で完結し、音声は外部に送信されません。
LUFS ラウドネス測定 — 配信ターゲット (YouTube / Spotify / EBU) との差分
音声ファイル (MP3 / WAV / M4A / FLAC / OGG / Opus) をドロップすると、ITU-R BS.1770-4 準拠の Integrated LUFS / Loudness Range (LRA) / Sample Peak (dBFS) をブラウザ内で測定します。配信プラットフォームのターゲットラウドネス (YouTube / Apple Music / Amazon Music: -14 LUFS, Spotify: -14 LUFS, Apple Podcasts: -16 LUFS, EBU R128 / 放送: -23 LUFS) を選ぶと、現状値とターゲットの差分 (LU) を表示。あといくつ ±dB で audio-volume を適用すれば良いかを直感的に把握できます。K-weighting フィルタ + 400 ms 矩形窓 + Absolute (-70 LUFS) + Relative (-10 LU) のゲーティングを自前 biquad で実装、ステレオは ITU 重み付け (L=R=C=1)。音声はブラウザ内で完結。