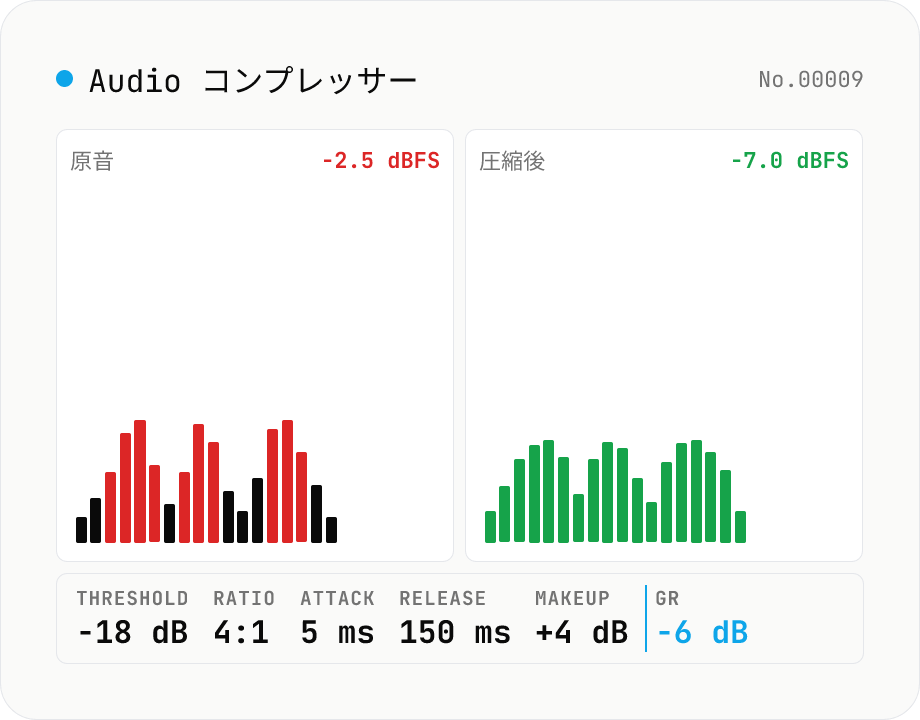
Audio コンプレッサー — threshold / ratio / attack / release を調整して WAV 出力
Web Audio API の DynamicsCompressorNode を使い、しきい値 (threshold) を超えた音声を比率 (ratio) で圧縮する古典的ダウンワード・コンプレッサーです。threshold (-60 〜 0 dB)、ratio (1:1 〜 20:1)、attack (0 〜 1 秒)、release (0 〜 1 秒)、knee (0 〜 40 dB) に加えて、補正の makeup gain (0 〜 24 dB) も指定可能。OfflineAudioContext でオフライン (= リアルタイムより高速) レンダリングし、16-bit PCM の WAV を生成します。ボーカル・ナレーション・ポッドキャストの音量を整える、ドラムを潰す、マスターでピーク抑制する、など用途は広いです。`audio-volume` (一括ゲイン)、`audio-loudness-lufs` (測定だけ)、`audio-true-peak` (測定だけ) と棲み分け。複数ファイル一括処理 + per-file WAV / ZIP 全件保存対応。音声はブラウザ内でだけ処理され、サーバーには送信されません。
使い方
音声ファイル (MP3 / WAV / M4A / AAC / FLAC / OGG / Opus) をドロップ。 Threshold / Ratio / Attack / Release / Knee / Makeup gain を調整するか、プリセット (ボーカル / ポッドキャスト / ドラム / マスタリング / リミッター) を選択。 WAV (16-bit PCM) で出力。複数ファイル時は全件 ZIP ダウンロード可能。 パラメータを変えると自動的に再処理します (元のファイルは保持)。
詳細解説
コンプレッション処理に持ち込む素材は、たいてい未公開の最終仕上げ前
コンプレッサーをかける局面は、音楽制作ではマスタリングの直前、ポッドキャスト制作では編集後の書き出し前、ボーカル録音では DAW でのミックス工程という具合に、ほぼ例外なく「もうすぐ完成するが、まだ完成していない」タイミングに集中します。この段階の素材は、アーティスト名・タイトル・歌詞の一部が含まれていたり、クライアントワークで守秘義務が生きていたりすることがほとんどです。
動的な処理であるコンプレッションは、元のダイナミクス情報をそのまま保ったファイルをサーバーに渡さなければ実行できません。言い換えると、「コンプレッサーを試したい」という意図のためだけに、制作中の生素材をそのまま外部に送る、という構造がオンラインツールには常にあります。
音声編集クラウドサービスとコンテンツ権利の問題
音声処理系のオンラインサービスは、ファイルを受け取り処理して返すアーキテクチャが標準です。この形式では利用規約でコンテンツへの使用権が設定されることが多く、「コンプレッサーのパラメータを変えながら試聴する」という操作ごとに音声ファイルが送信され、サーバー側のアクセスログに記録されます。
無料サービスほど広告収益と引き換えにデータを活用する傾向があります。制作中の音源が「サービス向上のための学習データ」として利用されることを明示的に禁止する手段は、利用者側にはほとんどありません。完成前の音楽を外部のサーバーで処理するリスクは、目に見えにくいだけで実在します。
Web Audio API の DynamicsCompressorNode がブラウザ内で処理する
このツールは音声ファイルを Web Audio API の decodeAudioData でデコードし、DynamicsCompressorNode に threshold / ratio / attack / release / knee の各パラメータを設定して OfflineAudioContext で処理します。Makeup gain は GainNode をチェーンに追加することで適用しています。いずれの工程もブラウザのメモリ内で完結し、サーバーとの通信は発生しません。
パラメータを変えるたびに自動再処理が走りますが、この再処理もすべてローカルで動いています。DevTools の Network タブを開いたまま操作すると、音声関連のリクエストが一切発生しないことを確認できます。実装コードは GitHub で公開されており、DynamicsCompressorNode の設定値を含めて監査できます。
コンプレッサーをかける前に確認しておくべきこと
コンプレッションは不可逆な処理です。元のダイナミクスを後から復元することはできないため、WAV 出力で受け取ったファイルを元素材とは別に保存する習慣をつけておくことを強くお勧めします。プリセット (ボーカル / ポッドキャスト / ドラム) から始めて、耳で聴きながら threshold と ratio を微調整するのが最も確実な調整方法です。
Makeup gain は出力音量を補正するもので、コンプレッサー本体のパラメータとは独立しています。かけすぎると後段の処理 (リミッターや最終エンコード) でクリッピングが発生することがあるので、audio-loudness-lufs や audio-true-peak でレベルを確認しながら調整してください。最終ゲイン補正だけならコンプレッサーを通さず audio-volume で済むケースもあります。
Threshold / Ratio / Knee の挙動とエンベロープ追従の仕組み
コンプレッサーは入力レベルがしきい値 (threshold) を上回ったときに、超過分を圧縮比 (ratio) で割って出力レベルを下げる仕組みです。threshold = -18 dB、ratio = 4:1 なら、-10 dB の入力 (しきい値超過 +8 dB) は -18 + (8 / 4) = -16 dB に圧縮されます。ratio が 1:1 だと素通り、∞:1 ならリミッター動作になります。Knee はしきい値前後の遷移を硬い (hard knee = 0 dB) か柔らかい (soft knee = 30 dB) かを指定するパラメータで、ボーカルやアコースティックギターでは soft knee (20〜40 dB) が自然な圧縮感を出すために好まれます。
attack は入力レベルがしきい値を上回ってからゲインリダクションが目標値に達するまでの時間、release は入力レベルが下回ってから減衰がリセットされるまでの時間です。Web Audio API の DynamicsCompressorNode は内部でレベル検出を RMS 系の包絡線で行い、attackTime / releaseTime を持つ exponential averaging で追従させます。attack = 3 ms は瞬間的な打撃 (キックドラム、子音) を抑え、attack = 30 ms はトランジェントを生かしながら平均レベルだけ整える効果を生みます。release は 100〜300 ms がポンピング (聴感上の音量の脈動) を避けるための一般的なレンジで、ドラムの密度が高い素材では 60〜80 ms、ボーカルや会話では 150〜250 ms が出発点です。
ジャンル別の典型設定と「コンプレッサーで何を直すか」の整理
ボーカル / ナレーション / ポッドキャストでは threshold -18〜-14 dB / ratio 3:1〜4:1 / attack 10〜20 ms / release 150〜250 ms が一般的な出発点で、子音や口蓋音の鋭さを抑えつつ平均音量を持ち上げて聞き取りやすくする目的です。マスターバス (楽曲全体に薄くかける) では threshold -8〜-6 dB / ratio 1.5:1〜2:1 / attack 30 ms / release 100 ms 程度の「glue compression」が標準で、ミックス全体をまとめる効果を狙います。ドラムバスは threshold -10 dB / ratio 4:1 / attack 5〜10 ms / release 50〜100 ms でアタックを残しつつ余韻を引き上げる、というセッティングが教科書的です。
落とし穴として、(a) ratio を上げすぎると音楽的なダイナミクスが失われて「呼吸感」が消える、(b) attack を短くしすぎると子音やドラムのアタックが潰れて鈍い音になる、(c) release が長いとピアノやアコースティックギターの減衰が不自然に持ち上がる、(d) makeup gain を強くかけすぎると後段の audio-loudness-lufs 測定で -14 LUFS を超えてプラットフォーム側で自動減衰される、などがあります。配信先のラウドネス基準 (Spotify / Apple Music / YouTube: -14 LUFS、Apple Podcasts: -16 LUFS、EBU R128: -23 LUFS) を意識して、最終段で測定 → 微調整するルーチンを組むのが安全です。
よくある質問
- コンプレッサーは何のために使う?
- 音声のダイナミックレンジ (最大音量と最小音量の差) を圧縮するエフェクトです。ボーカルやナレーションで「大きすぎる/小さすぎる箇所」を均一化、ドラムをタイトに、マスターでピーク制御するなど、ほぼすべての音楽・音声制作で使われます。
- threshold と ratio の選び方は?
- Threshold は「圧縮を始める音量」、Ratio は「しきい値を超えた分をどれくらい圧縮するか」。ボーカルなら threshold -18 〜 -12 dB、ratio 3:1 〜 5:1 が典型。マスターなら threshold -6 dB、ratio 2:1 程度で軽めに。リミッターは ratio 10:1 以上 + 速い attack。プリセットを試して耳で確認するのが近道です。
- attack と release の影響は?
- Attack は短い (1 〜 5 ms) ほどトランジェント (キック・スネアの頭) を潰し、長い (50 ms+) ほどトランジェントを残します。Release は短い (50 ms) ほどポンピング感が出やすく、長い (300 ms+) ほど自然な余韻に。素材ごとに耳で合わせるのが定石。
- Makeup gain は必要?
- コンプレッサーは「平均音量を上げず、ピークを下げる」エフェクトなので、結果的に音量が下がります。Makeup gain は出力ステージで一律に持ち上げる補正用ゲイン。一般に「圧縮量 (Gain Reduction) と同じ dB」を補えば元の体感音量になります。
- なぜ出力が WAV のみ?
- ブラウザネイティブで圧縮形式 (MP3 / AAC) を再エンコードできないためです。WAV → MP3 が必要なら、本ツールで処理した WAV を `audio-convert` (MP3 化対応) にかけてください。
- データは外部に送信されますか?
- いいえ。Web Audio API のみで完結します。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール
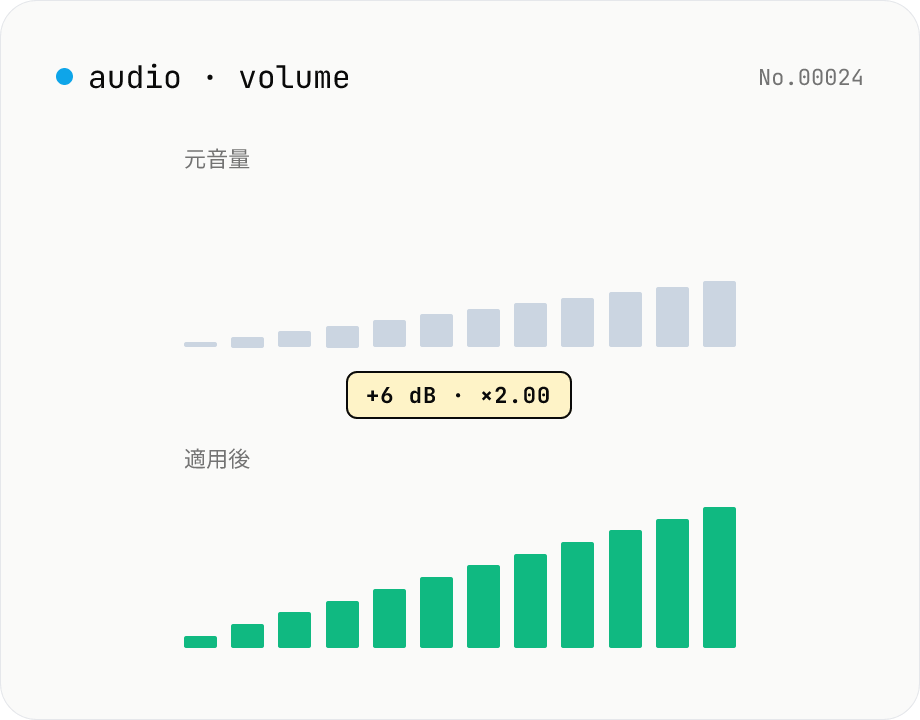
音量調整 — dB 変更 / ノーマライズ / 倍率
音声ファイルの音量を ffmpeg.wasm の volume フィルタで一括調整します。dB スライダ (-30〜+30 dB) または倍率 (×0.03〜×31.6) を選択。+6 dB ≒ 2 倍、−6 dB ≒ 半分。クリッピングを避けたいときはピークメーター代わりにマイナス側で試して比較を。複数ファイル一括処理 + ZIP ダウンロード対応。すべてブラウザ内で完結し、音声は外部に送信されません。
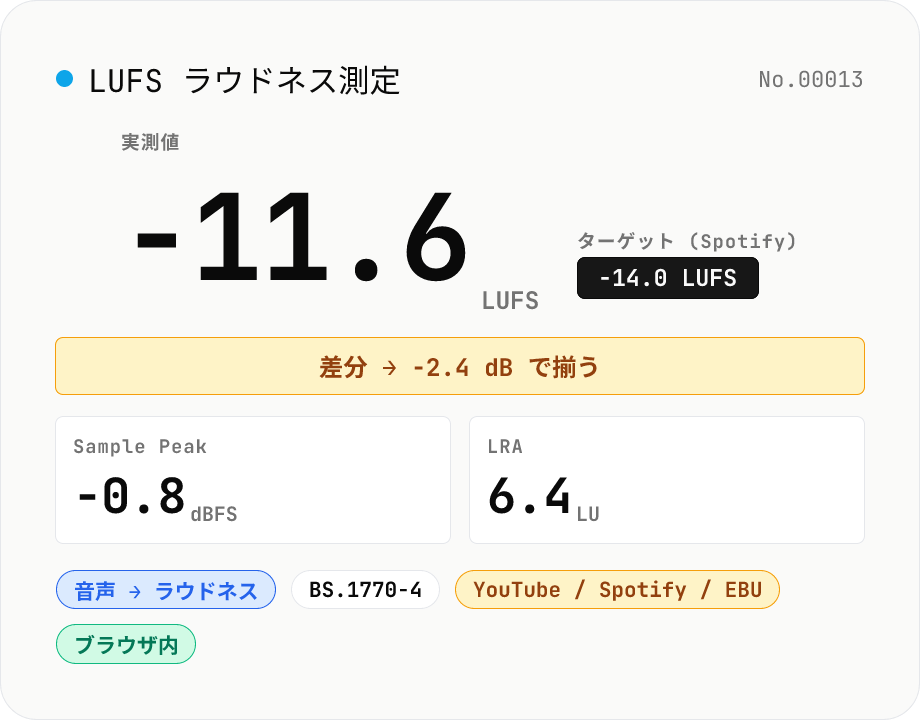
LUFS ラウドネス測定 — 配信ターゲット (YouTube / Spotify / EBU) との差分
音声ファイル (MP3 / WAV / M4A / FLAC / OGG / Opus) をドロップすると、ITU-R BS.1770-4 準拠の Integrated LUFS / Loudness Range (LRA) / Sample Peak (dBFS) をブラウザ内で測定します。配信プラットフォームのターゲットラウドネス (YouTube / Apple Music / Amazon Music: -14 LUFS, Spotify: -14 LUFS, Apple Podcasts: -16 LUFS, EBU R128 / 放送: -23 LUFS) を選ぶと、現状値とターゲットの差分 (LU) を表示。あといくつ ±dB で audio-volume を適用すれば良いかを直感的に把握できます。K-weighting フィルタ + 400 ms 矩形窓 + Absolute (-70 LUFS) + Relative (-10 LU) のゲーティングを自前 biquad で実装、ステレオは ITU 重み付け (L=R=C=1)。音声はブラウザ内で完結。
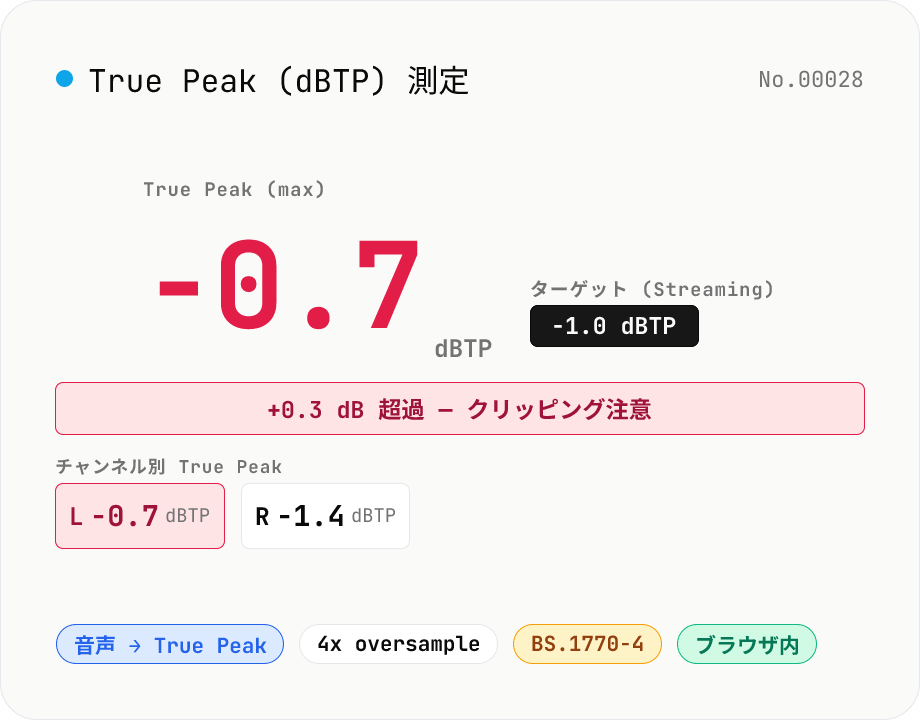
True Peak (dBTP) 測定 — 4x オーバーサンプリングで inter-sample peak を検出
音声ファイル (MP3 / WAV / M4A / FLAC / OGG / Opus) をドロップすると、ITU-R BS.1770-4 Annex 2 準拠の 4 倍オーバーサンプリング (poly-phase FIR low-pass) で Inter-sample Peak を補間して True Peak (dBTP) を測定します。Sample Peak (dBFS) では検出できない MP3 / AAC エンコード後のクリッピングを事前に把握できます。ストリーミング配信のターゲット (Spotify / Apple Music / EBU R128 = -1.0 dBTP, YouTube = -1.0 dBTP, ラジオ = -2.0 dBTP) と比較して、リミッターの追い込み具合を可視化。L/R 別の値とどちらが上限を超えているかも一目で分かります。音声はブラウザ内で完結。
音声フェード — フェードイン / フェードアウトを秒単位で適用
音声ファイルの先頭と末尾に任意秒のフェードイン / フェードアウト効果を入れます。ffmpeg.wasm の afade フィルタを使い、MP3 / WAV / M4A / OGG / FLAC など主要フォーマットに対応。複数ファイル一括処理 + ZIP ダウンロード対応。音声はサーバーに送信されません。