使い方
形式 (俳句 5-7-5 / 短歌 5-7-5-7-7) を選び、句を 1 行で入力するだけで OK。漢字混じりの文を **kuromoji** で形態素解析して読み (カタカナ) に変換し、モーラ (拍) 単位に分解して各句のモーラ数を数えます。**モーラ集計ルール**: 拗音 (キョ / シャ / チュ / ピョ など) は前の音と合体して 1 モーラ、促音 (ッ)・撥音 (ン)・長音 (ー) はそれぞれ単独で 1 モーラ。例: 「東京 (トウキョウ)」は ト・ウ・キョ・ウ = 4 モーラ、「ニッポン」は ニ・ッ・ポ・ン = 4 モーラ。各句のカードには期待モーラ数・実モーラ数・差分 (字足らず / 字余り) + 読み (モーラ区切り) を表示。改行・空白・句読点は無視するので、原文をそのまま貼り付けて OK。
詳細解説
未発表の俳句・短歌を入力することの意味
俳句・短歌のモーラ数確認ツールを使うタイミングは、創作の途中段階であることがほとんどです。推敲中の作品、投稿前の公募向け句、句会に提出する前の最終チェック — いずれも「まだ公開していない」作品です。未発表の文芸作品は著作権の観点でも機微であり、外部サービスに送信することで、作者が意図しないログとして記録される可能性があります。
出版社や文芸誌の編集者が、著者から預かった原稿を校正するために使う場合も同様です。著者の未発表作品を外部サービスに入力することは、著者との守秘義務に抵触する可能性があります。音数確認という単純な操作のために、作品の内容を外部に送ることは避けたいものです。
オンライン俳句チェックサービスへの送信リスク
インターネット上には俳句・短歌の音数を確認できるサービスが複数あります。サーバー側で形態素解析を行うサービスでは、入力した句がリクエストとしてサーバーに渡り、ログに残ります。無料の API 形式で提供されているサービスでは、入力データを「サービス改善目的」で蓄積する利用規約になっている場合があります。
俳句・短歌の句集を AI に学習させる商業サービスが登場している現在、作家が意図せずに自身の未発表作品を学習データとして提供してしまうリスクも実在します。単純なモーラ数確認の操作が、その入口になることを認識しておく価値があります。
kuromoji とモーラ分解がブラウザ内で動く仕組み
このツールは kuromoji.js (Apache 2.0) と IPADIC 辞書をブラウザ内で動作させます。入力された句を形態素解析してカタカナ読みに変換し、そのカタカナ列をモーラ (拍) 単位に分解します。拗音 (キョ・シャなど) を 1 モーラとして扱い、促音 (ッ)・撥音 (ン)・長音 (ー) をそれぞれ独立した 1 モーラとカウントする処理も、ブラウザ内の JavaScript で完結します。
辞書の初回ダウンロード (約 12MB) を除いて、句の処理はすべてオフラインで動作します。DevTools の Network タブを開いた状態で句を変更しても、通信は発生しません。作品をどれだけ推敲しても、その過程がサーバーに記録されることはありません。
創作フローの中での活用と習慣づけ
俳句・短歌の作成フローでは「書く → 音数確認 → 推敲 → 再確認」を繰り返します。この確認ステップを、外部送信なしのブラウザ内ツールに固定しておくことで、推敲の各段階で作品が外部に出るリスクをなくせます。特に公募や賞への応募作品は、提出前に外部サービスに送ることを避けるべきです。
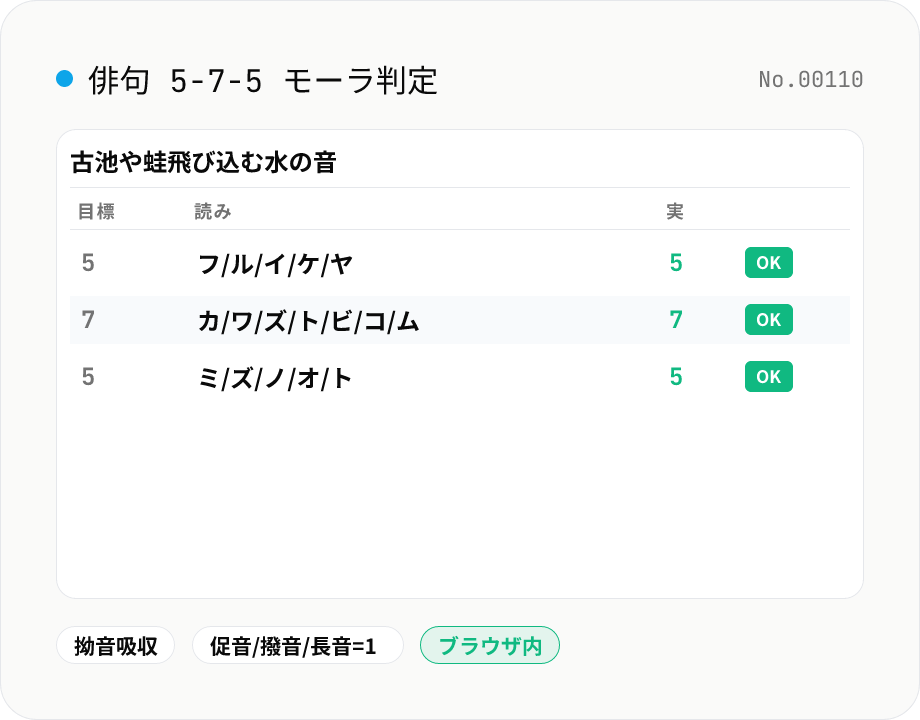
「古池や蛙飛び込む水の音」のような教科書的な句でサンプル動作を確認してから、自分の句を入力するという順序は、ツールの動作確認と作品管理の両方を兼ねる良い習慣です。
モーラ (拍) と音節の違い、俳句固有のカウントルール
日本語の音数は、英語などの音節 (syllable) ではなく モーラ (拍) で数えます。モーラは「等しい時間長を持つ音の単位」と定義され、ひらがなで あ・い・う・え・お や か・き・く・け・こ のような清音は 1 モーラ、きゃ・しゅ・ちょ のような 拗音 は 2 文字でも 1 モーラとカウントします。対して ッ (促音)、ン (撥音)、ー (長音) は単独で 1 モーラを占めます。たとえば 東京 (トーキョー) は 4 モーラ (ト・ー・キョ・ー)、札幌 (サッポロ) は 4 モーラ (サ・ッ・ポ・ロ) と数えます。読みの抽出を句単位で見たい場合は kanji-to-hiragana で全文をひらがな化してから貼り直すと、モーラ分解の根拠を確認しやすくなります。
俳句・短歌の世界では、このモーラ計算が伝統的なルールに従って厳格に運用されます。古池や蛙飛び込む水の音 は フルイケヤ・カワズトビコム・ミズノオト で 5-7-5 = 17 モーラ、ぴったり収まります。一方、口語俳句や現代俳句では「字余り (5 を 6 にする)」「字足らず (5 を 4 にする)」が技法として許容されます。本ツールは厳密な 5-7-5 / 5-7-5-7-7 ルールに基づいて過不足を表示しますが、自由律俳句 (種田山頭火・尾崎放哉) や口語短歌では音数制約を意図的に破る作風があり、カウント結果はあくまで「伝統規範からの差分」として読むのが適切です。
流派・時代別の俳句ルールと現代俳句の音数感
伝統俳句では 5-7-5 の音数遵守、季語 の使用、切れ字 (や・かな・けり) の挿入が三大要素ですが、各俳句結社・流派で運用が微妙に異なります。日本伝統俳句協会 系は厳密な定型を重視し、現代俳句協会 系は字余り・無季語をある程度許容します。短歌でも アララギ派 (写実) と 心の花派 (浪漫主義) で技法が違い、現代短歌 (俵万智・穂村弘) では口語の流れを優先して 5-7-5-7-7 を逸脱する作品が多くなっています。本ツールはあくまで音数のカウンタなので、流派ごとの作風や季題の使い方の評価まではできません。
外国語訳された俳句では、音節とモーラの違いから音数が一致しないのが普通です。英語俳句で 5-7-5 を音節で数えると、日本語原文より遥かに情報量が多くなり、結果として日本語俳句の短さ・余白の効果が失われます。Robert Hass・R. H. Blyth の英訳俳句は音節制約を緩めて意味を優先する立場を取り、Cor van den Heuvel 編の The Haiku Anthology も自由な音節数を採用しています。逆に、外国人作家による日本語俳句 (May Sarton・Ezra Pound らの作品の和訳) を本ツールで確認すると、文化背景の違いから生まれる音数のずれを観察できます。創作の補助ツールとしての本ツールは「伝統規範からの距離を測る」用途で活用するのが最も実用的です。トークン単位で品詞・読みを掘り下げたいときは wakati-tokenize も併用できます。
よくある質問
- 入力データはサーバーに送信されますか?
- いいえ。すべてブラウザ内で完結します。kuromoji の形態素解析もブラウザ側で動作し、辞書 (約 12MB) は初回ロード後にキャッシュされます。
- 拗音 (キョ・シャなど) はなぜ前のモーラに合体するんですか?
- 俳句・短歌のモーラ (拍) のカウントは、日本語のリズム単位 (音節 ≒ モーラ) に基づきます。拗音は「直音 (キ・シ・チ等) + 半母音 (ャ・ュ・ョ)」がひとつの音節として発音されるため 1 モーラ扱い。同様に「キャ・キュ・キョ / シャ・シュ・ショ / ツァ・ツィ・ツェ・ツォ」なども 1 モーラです。
- 促音 (ッ)・撥音 (ン)・長音 (ー) はそれぞれ 1 モーラ?
- はい、日本語のモーラ理論で促音・撥音・長音は独立した 1 モーラとしてカウントします。例: 「学校 (ガッコウ)」は ガ・ッ・コ・ウ = 4 モーラ、「東京 (トウキョウ)」は ト・ウ・キョ・ウ = 4 モーラ、「ニッポン」は ニ・ッ・ポ・ン = 4 モーラ。俳句・短歌でも同じカウント方式です。
- 字余り・字足らずは無効なんですか?
- 伝統的には 5-7-5 (俳句) / 5-7-5-7-7 (短歌) が標準ですが、字余り・字足らずも俳人・歌人の表現技法として広く認められています (松尾芭蕉の自由律も)。本ツールは正規パターンとの差分を **+N / -N** で見える化するだけで、不一致でもエラー扱いはしません。仕上げ前のチェックや創作のドラフト確認用に。
- なぜサンプルの「古池や蛙飛び込む水の音」は完全に 5-7-5 になるんですか?
- 読み下し: フ・ル・イ・ケ・ヤ (5) / カ・ワ・ズ・ト・ビ・コ・ム (7) / ミ・ズ・ノ・オ・ト (5) = 17 モーラ。芭蕉の代表作で、教科書的に必ず 5-7-5 に収まる例として知られています。一方、漢字の読みが kuromoji の辞書登録と違うと音数がずれることがあります (例: 固有名詞・古語)。
- 初回ロードが遅いです
- kuromoji の辞書ファイル (約 12MB) を初回だけダウンロードするためです。2 回目以降はブラウザキャッシュから即起動します。ロード状態は画面上にも表示されます。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール

日本語 分かち書き / 形態素解析 — kuromoji で品詞タグ付きトークン化
日本語テキストを kuromoji (MIT) で形態素解析し、**スペース区切りの分かち書き** に変換します。NLP 前処理、検索インデックス (Elasticsearch / Algolia / Meilisearch) のトークン化、Word2Vec / fastText の学習データ準備などに使用。出力には、各トークンの **表層形 / 品詞 (名詞・動詞・助詞 等 13 種類) / 品詞細分類 / 活用形 / 基本形 / 読み / 発音** を併記した詳細テーブルも表示。フィルタで「名詞だけ抽出」「助詞・記号を除外」「重複を集約」も可能。GiNZA / MeCab / Sudachi の挙動確認、検索キーワード抽出、形態素解析の Tips 確認に。辞書は初回のみブラウザにダウンロード (~12MB) され、以降はオフライン動作。すべてブラウザ内で処理、テキストはサーバーに送信されません。
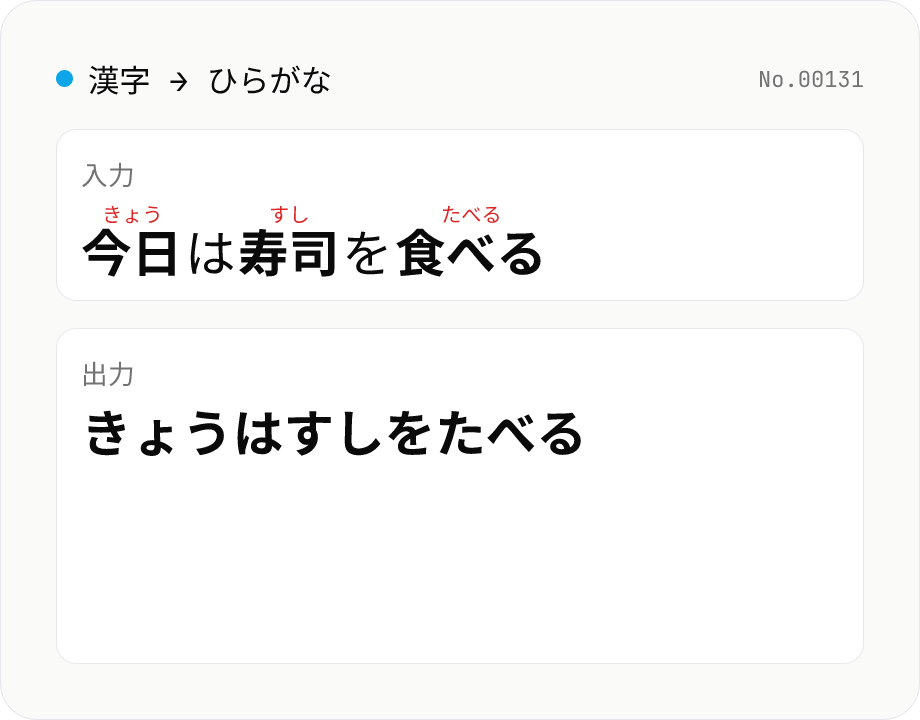
漢字 → ひらがな 変換 — kuromoji 形態素解析で読み付与
日本語テキストを kuromoji の形態素解析で読み (ひらがな) に変換します。全文ひらがな化と、漢字の上にルビを振る「ふりがな」モードに対応。辞書は初回のみブラウザにダウンロードされ、以降はオフライン動作。すべてブラウザ内で処理。
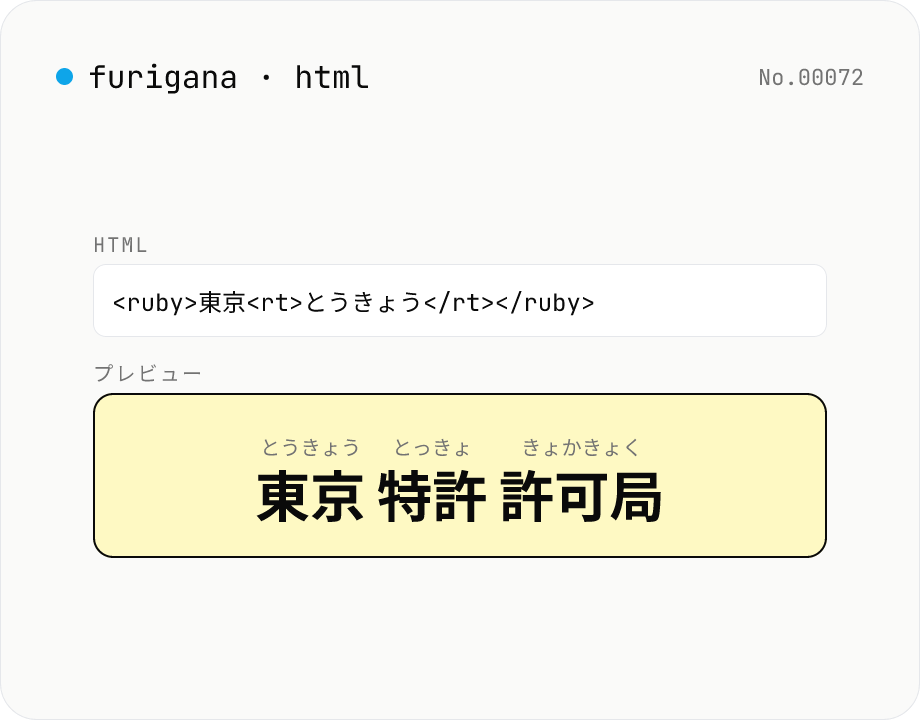
ふりがな HTML 生成 — <ruby> タグで漢字に振る
日本語テキストを kuromoji で形態素解析し、漢字部分に `<ruby>漢字<rt>かんじ</rt></ruby>` のふりがな HTML を付与したソースコードを出力します。WordPress / 各種 CMS / Markdown 記事に貼り付けて使えます。フリガナはひらがな・カタカナを選択可能。`<rp>` フォールバックも追加可能。すべてブラウザ内で処理します。
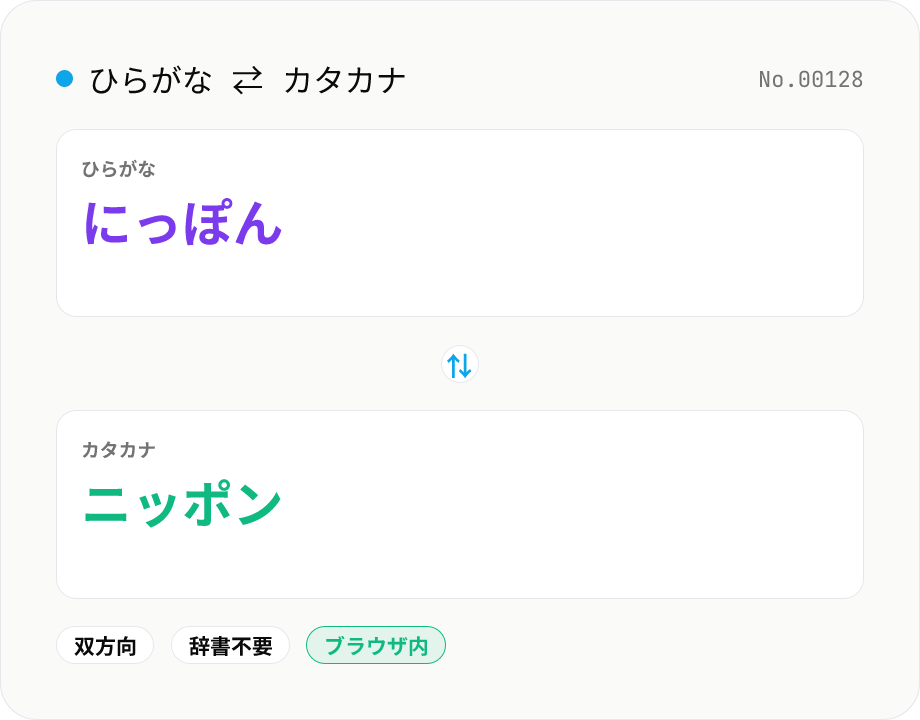
ひらがな ⇄ カタカナ 変換 — 文字単位で一括相互変換
ひらがな⇄カタカナをモード切替で双方向に変換します。文字単位の機械的な置換なので辞書ダウンロード不要、瞬時に動作。長音「ー」や記号、漢字・英数字はそのまま保持。すべてブラウザ内で処理。