Haiku / Tanka Syllable (mora) Counter
Verify the 5-7-5 (haiku) or 5-7-5-7-7 (tanka) mora pattern with kuromoji morphological analysis. Mixed kanji-kana input is parsed into katakana reading, broken into mora, and each line is checked against the target count — over and under shown line by line. Follows traditional rules: yōon (キョ, シャ etc.) absorbs into the previous mora; sokuon (ッ), hatsuon (ン), and chōonpu (ー) each count as 1.
How to use
Pick the form (haiku 5-7-5 / tanka 5-7-5-7-7) and paste a single line of verse. **kuromoji** parses kanji-kana text into katakana reading, then breaks it into mora (rhythmic units). **Mora rules**: yōon syllables (キョ / シャ / チュ / ピョ etc.) merge into the preceding mora; sokuon (ッ), hatsuon (ン), and chōonpu (ー) each count as 1. So 東京 (Tōkyō) = ト・ウ・キョ・ウ = 4 mora; ニッポン = ニ・ッ・ポ・ン = 4 mora. Each line's card shows target vs. actual mora, the under/over diff, and the reading broken on mora boundaries. Line breaks, whitespace, and punctuation in the input are ignored — paste the source verse directly.
In depth
Why an unpublished haiku or tanka deserves careful handling
A mora-count check is almost always done mid-composition: you are revising a draft haiku for a poetry contest, polishing a tanka before sending it to a literary magazine, or fine-tuning a verse before a haiku club meeting. All of those moments involve work that is not yet public. Unpublished poetry carries both copyright significance and a creative vulnerability — it is an expression that the author has not yet chosen to release.
Editors and writing coaches face the same issue when checking the syllable counts of manuscripts entrusted to them by authors. Passing a client’s poem through a server-side tool is, arguably, a breach of the implicit confidentiality that surrounds unpublished work. A mora-count check seems trivial, but the vehicle matters.
The logging risk of online poetry analysis services
Server-side mora-count services receive your poem as an API request, process it remotely, and return the result. That flow produces a server log: a timestamp and the text of the verse. Services that offer morphological analysis ‘for free’ often monetise through advertising or by accumulating text data, sometimes reserving the right in their terms to use submissions for ‘service improvement’.
The commercial market for AI trained on Japanese poetry is growing. Uploading draft verses to an unvetted service is a potential — even if unintended — contribution to a corpus being used for commercial training. The risk is structural, not a matter of any one operator’s intent.
kuromoji and in-browser mora decomposition
This tool runs kuromoji.js (Apache 2.0) with the IPADIC dictionary inside your browser. When you paste a verse, the browser’s JavaScript engine tokenises the text, converts each token to its katakana reading, and then splits the reading into mora. The rules — yōon syllables (キョ, シャ, etc.) merge with the preceding consonant and count as one; sokuon (ッ), hatsuon (ン), and chōonpu (ー) each count as one — are implemented in local JavaScript.
Aside from the one-time dictionary download (~12 MB, cached after first use), all processing runs offline. Open DevTools → Network and edit your verse repeatedly: no outbound request carries your text. The revision cycle — write, count, revise, recount — stays entirely on your device.
Fitting a local mora check into a composition workflow
A practical approach: use the sample button to verify the tool is working correctly on the well-known Bashō verse, then switch to your own draft. This keeps the test and the live composition separate, and means you only enter unpublished work after confirming the tool behaves as expected.
For poetry contest submissions in particular — where the work must be original and unpublished — running all pre-submission checks in a browser-local tool is a clean habit. It removes any ambiguity about whether the poem was ‘submitted’ somewhere before the official submission.
Mora vs. syllable and the rules specific to haiku counting
Japanese counts sound units in mora (拍), not syllables. A mora is a unit of equal time length: in hiragana, single characters like あ・い・う・え・お or か・き・く・け・こ are one mora each, while yōon clusters like きゃ・しゅ・ちょ are two characters but one mora. Sokuon ッ, hatsuon ン, and chōonpu ー each count as one mora on their own. 東京 (トーキョー) is four mora (ト・ー・キョ・ー), and 札幌 (サッポロ) is four mora (サ・ッ・ポ・ロ) — the lengthening and the small tsu pay for their own beat. If you want to see the full kana reading of a kanji-heavy draft before counting, kanji-to-hiragana runs the same kuromoji pipeline.
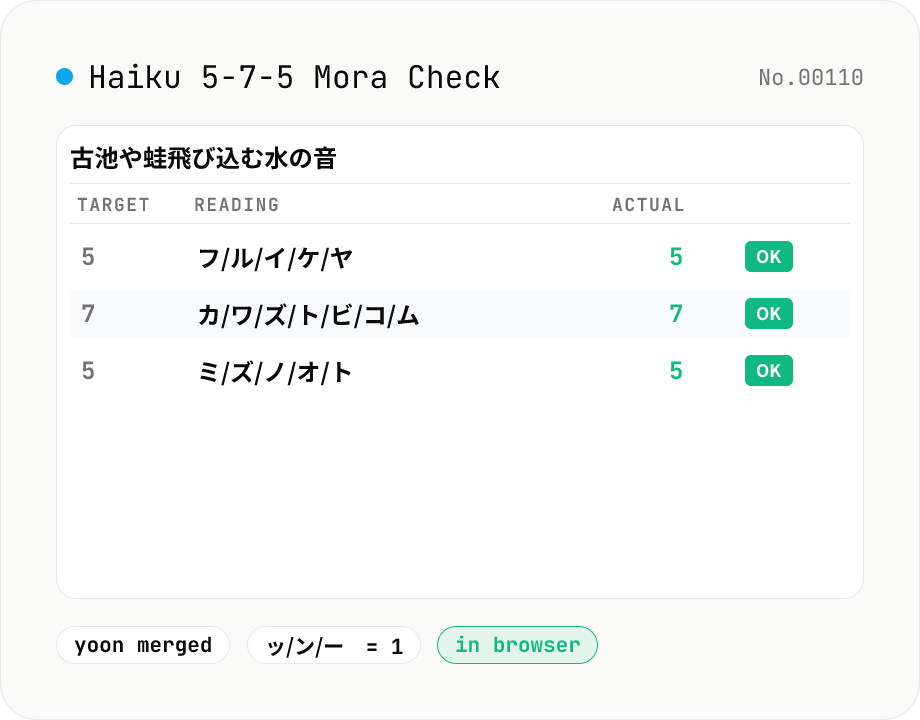
In haiku and tanka the mora rule is applied strictly. Bashō’s 古池や蛙飛び込む水の音 parses as フルイケヤ・カワズトビコム・ミズノオト, exactly 5-7-5 = 17 mora. Modern and colloquial haiku sometimes deliberately bend the form, using 字余り (extra mora) or 字足らず (short mora) as technique. This tool reports the over/under against the strict pattern, but for free-style writers — Santōka Taneda, Hōsai Ozaki, or contemporary colloquial tanka by Machi Tawara and Hiroshi Homura — that diff is best read as “distance from convention” rather than as an error.
School and modernity differences in haiku rules
Traditional haiku enforces the 5-7-5 mora pattern, a seasonal word (季語), and a cutting word (切れ字: や / かな / けり). Different haiku associations take different views: the Nihon Dentō Haiku Kyōkai (traditional) holds firmly to the pattern, while the Gendai Haiku Kyōkai (modern) tolerates extra mora and even drops the seasonal word. Tanka has the same split, with the Araragi school favouring realism and stricter form, and contemporary poets using colloquial Japanese that runs over or under 5-7-5-5-7-7 freely. This tool reports the count; the literary judgment of which deviation is intentional craft is up to you.
Translated haiku in English typically cannot match the mora count because syllables and mora are different units — English syllables can be much shorter, so 5-7-5 in English syllables produces a poem with more information density than the Japanese original, defeating the form’s signature brevity. Translators like Robert Hass, R. H. Blyth, and the editors of The Haiku Anthology (Cor van den Heuvel) generally drop the strict syllable count in favour of conveying meaning. Conversely, running the Japanese translation of a non-native poet’s haiku through this tool reveals where cultural differences in rhythm bend the form. The practical use of the counter is as a distance-from-convention gauge, useful precisely because Japanese mora rules are sufficiently rigid to be measured. For per-token POS and reading analysis of the same verse, wakati-tokenize pairs naturally with this tool.
FAQ
- Is my input uploaded?
- No. Everything runs in your browser. kuromoji's morphological analysis happens client-side and the ~12MB dictionary is cached after the first load.
- Why does yōon (キョ, シャ…) merge into the previous mora?
- Mora in haiku / tanka follow Japanese rhythmic units (≈ syllables). A yōon is a *direct kana + glide* (ャ / ュ / ョ) pronounced as one syllable, so it counts as 1 mora. Same goes for キャ・キュ・キョ / シャ・シュ・ショ / ツァ・ツィ・ツェ・ツォ etc.
- Are sokuon (ッ), hatsuon (ン), and chōonpu (ー) each their own mora?
- Yes. Classical Japanese mora theory treats them as independent. 学校 (gakkō) = ガ・ッ・コ・ウ = 4 mora; 東京 = ト・ウ・キョ・ウ = 4; ニッポン = ニ・ッ・ポ・ン = 4. Haiku and tanka use the same convention.
- Is going over / under count not allowed?
- Traditional form is 5-7-5 / 5-7-5-7-7, but jiamari (over) and jitarazu (under) are widely accepted poetic devices (Bashō wrote free-rhythm verse too). The tool just shows the diff as +N / -N — mismatches aren't flagged as errors. Use it as a draft sanity check.
- Why does the sample 「古池や蛙飛び込む水の音」 land exactly on 5-7-5?
- Reading: フ・ル・イ・ケ・ヤ (5) / カ・ワ・ズ・ト・ビ・コ・ム (7) / ミ・ズ・ノ・オ・ト (5) = 17 mora. This is Bashō's canonical 5-7-5 textbook example. When kuromoji's reading differs from what you intend (proper nouns, archaic words), counts can drift.
- First load is slow
- kuromoji has to download its ~12MB dictionary the first time. Subsequent loads pull from the browser cache and start instantly. The loading state is shown on screen.
How to verify nothing is uploaded
This tool never sends your input outside your browser. The pages below explain how it works, how to audit it, and how the site is run.
Related tools

Japanese wakati / tokenizer — kuromoji morphological analysis with POS tags
Tokenize Japanese text with kuromoji (MIT) and produce **space-separated wakati** output. Useful for NLP preprocessing, search-index tokenization (Elasticsearch / Algolia / Meilisearch), training-data preparation for Word2Vec / fastText, or just debugging differences between GiNZA / MeCab / Sudachi. A detailed token table accompanies the wakati output with **surface form / POS (13 categories: noun, verb, particle, etc.) / POS subtype / conjugation / base form / reading / pronunciation**. Filter to keep only nouns, drop particles and symbols, or deduplicate tokens. Dictionary downloads once (~12 MB) and works offline after. Everything runs in your browser; text is never uploaded.

Kanji → Hiragana converter — kuromoji morphological reading
Convert Japanese text to hiragana using kuromoji morphological analysis. Choose between fully hiragana output, or a furigana mode that keeps kanji and adds hiragana ruby above. The dictionary downloads once and is then offline. Runs entirely in your browser.
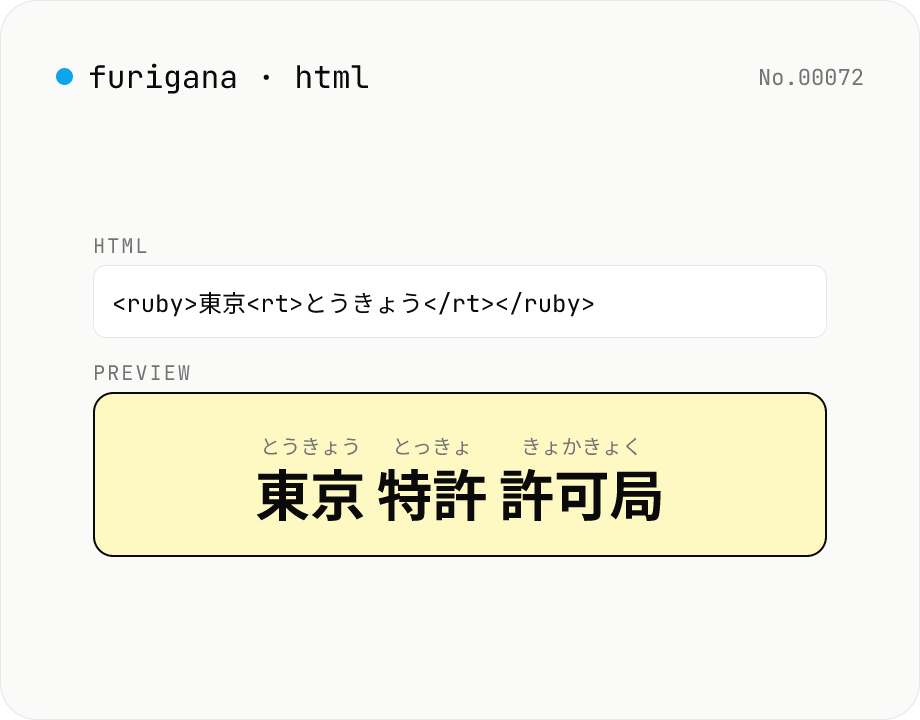
Furigana HTML generator — <ruby> ruby tags for kanji reading
Tokenises Japanese text with kuromoji and wraps each kanji token in `<ruby>漢字<rt>かんじ</rt></ruby>` markup. Copy the source and paste it into WordPress, any CMS, or a Markdown article. Furigana can be hiragana or katakana, with optional `<rp>` fallback for non-ruby browsers. Runs entirely in your browser.
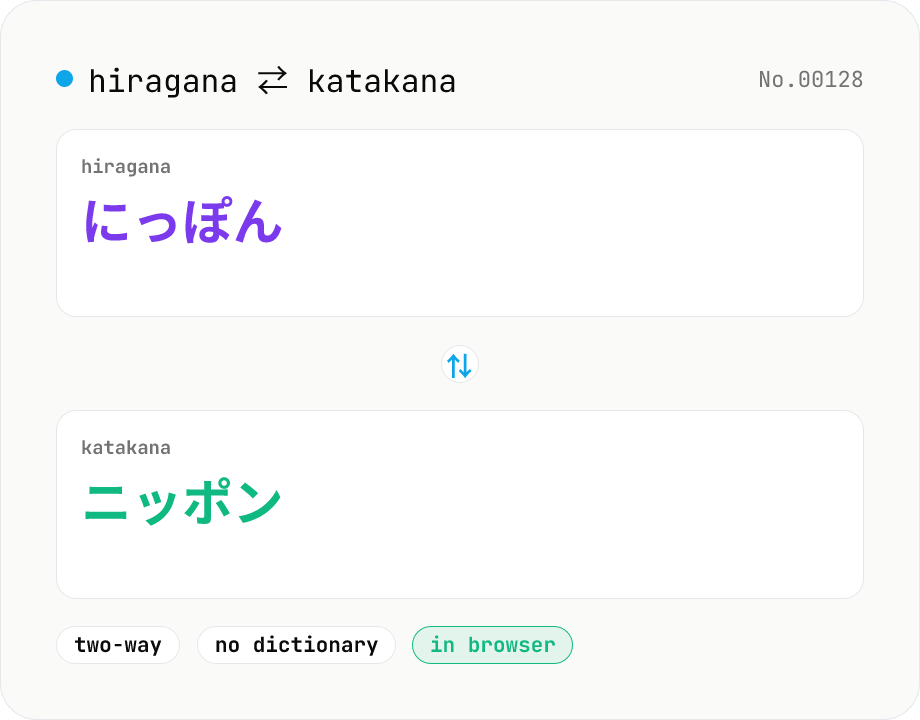
Hiragana ⇄ Katakana converter — bulk character mapping
Convert between hiragana and katakana with a single mode toggle. A purely mechanical per-character mapping — no dictionary download, instant conversion. Long-vowel mark, punctuation, kanji, and alphanumerics are preserved as-is. Runs entirely in your browser.