
日本語 分かち書き / 形態素解析 — kuromoji で品詞タグ付きトークン化
日本語テキストを kuromoji (MIT) で形態素解析し、**スペース区切りの分かち書き** に変換します。NLP 前処理、検索インデックス (Elasticsearch / Algolia / Meilisearch) のトークン化、Word2Vec / fastText の学習データ準備などに使用。出力には、各トークンの **表層形 / 品詞 (名詞・動詞・助詞 等 13 種類) / 品詞細分類 / 活用形 / 基本形 / 読み / 発音** を併記した詳細テーブルも表示。フィルタで「名詞だけ抽出」「助詞・記号を除外」「重複を集約」も可能。GiNZA / MeCab / Sudachi の挙動確認、検索キーワード抽出、形態素解析の Tips 確認に。辞書は初回のみブラウザにダウンロード (~12MB) され、以降はオフライン動作。すべてブラウザ内で処理、テキストはサーバーに送信されません。
使い方
テキスト欄に日本語を貼り付け、サンプルボタンで早口言葉や新聞風の例も試せます。 kuromoji の辞書がブラウザに自動ロード (初回 ~12 MB)。完了すると即座にトークン化が走ります。 上段に分かち書き (スペース区切り)、下段にトークン一覧テーブル (品詞・活用形・基本形・読みを併記) が表示されます。 フィルタで「名詞のみ」「内容語のみ」「記号除外」「重複集約」「基本形 (lemma) に正規化」を切替。CSV エクスポートも可能。
詳細解説
分かち書き・形態素解析に入力する文章の機微性
分かち書きや形態素解析は、NLP パイプラインの前処理として使われます。Elasticsearch の kuromoji analyzer でインデックスを構築する前のテキスト確認、BERT / Word2Vec の学習データとして使う文書の前処理、社内文書検索システムの品質確認など、業務上の重要なテキストが処理対象になります。未公開の製品マニュアル、機密の法務文書、未発表のニュース記事が形態素解析の対象として入力されることがあります。
特に「内容語だけ抽出」「名詞のみ」「基本形に正規化」といったフィルタ操作は、文書から意味的に重要な語を取り出す処理です。文書の「要約」に相当する情報が出力として生成されるため、機密性の高い文書の核心部分が抽出されて外部に出るリスクを意識する必要があります。
クラウド型 NLP API への文書送信リスク
形態素解析を提供するクラウド API (Yahoo! テキスト解析 API・AWS Comprehend・Google Natural Language API など) では、解析対象のテキストがリクエスト本文としてサーバーに送られます。API 利用規約に「入力データのログ保持」や「サービス改善のための活用」が含まれている場合、送信した文書がサービス提供者のシステムに残ります。
機密文書・未公開原稿・顧客情報を含む文章を外部 NLP API に送ることは、情報セキュリティポリシーとして禁止しているOrganization が多いです。しかし、前処理確認という軽いタスクのためにうっかり外部 API を使ってしまうケースは少なくありません。
kuromoji の IPADIC (約 39 万語) がブラウザ内で完結する仕組み
このツールは kuromoji.js (Apache 2.0) と IPADIC 辞書 (約 39 万語、約 12MB) をブラウザ内で動作させます。テキストの形態素解析・品詞タグ付け・読み取得・活用形の取得のすべてがブラウザの JavaScript エンジン内で完結します。フィルタ処理 (名詞のみ・内容語・重複集約・基本形正規化) も、形態素解析の結果配列をブラウザ内でフィルタするだけです。CSV エクスポートも Blob + URL.createObjectURL のブラウザ API でローカルに生成されます。
外部 NLP API は一切使いません。解析対象のテキストはサーバーに送信されません。DevTools の Network タブを開いた状態で文章を解析しても、辞書の初回ダウンロード後はテキストを含む通信は発生しません。機密文書を安心して前処理の動作確認に使えます。
NLP 前処理のワークフローへの組み込み方
本番の NLP パイプライン (Elasticsearch・Word2Vec・BERT Fine-tuning など) の前に、このツールで代表的なサンプル文書の分かち書き結果を確認することを推奨します。kuromoji の IPADIC は Elasticsearch の公式 kuromoji analyzer と同じ辞書であるため、このツールの出力と Elasticsearch のインデックス結果が一致します。サンプル文書を外部に送らずに事前確認できます。
「基本形に正規化」オプションの動作 (走っ → 走る / 美しかっ → 美しい) や、「内容語のみ」で助詞・助動詞が除去される様子を確認してから、本番データの前処理に適用することで、想定外の出力を防げます。確認作業で入力した文書が外部に残らないため、機密プロジェクトの NLP 開発でも使えます。
IPADIC・UniDic・NEologd・Sudachi 辞書の比較と選択基準
日本語形態素解析の辞書は複数あり、それぞれ設計思想と語彙範囲が異なります。IPADIC (本ツール採用、約 39 万語) は IPA 品詞体系 (約 70 種類の細分類) ベースで、Elasticsearch の標準 kuromoji analyzer もこれを採用しているため、検索インデックス用途で広く使われています。UniDic (国立国語研究所開発、約 87 万語) は 短単位 という単位で文を細かく分割する設計で、東京都 を 東京 + 都 に分けるなど学術研究・コーパス分析向きです。mecab-ipadic-NEologd (約 320 万語) は IPADIC に SNS・ニュース由来の新語・固有名詞を継続的に追加した辞書で、スマホ・鬼滅の刃・ChatGPT のような新語の対応に強みがあります。
Sudachi (ワークスアプリケーションズ 開発、Apache 2.0) は A / B / C の 3 種類の分割粒度を切り替えられる現代的な辞書で、東京都 を A 粒度 = 東京 + 都、B 粒度 = 東京都、C 粒度 = 東京都 (固有表現) のように使い分けられます。新語辞書 (SudachiDict-full で約 280 万語)、複数粒度、Java / Python / Rust など多言語対応が特徴で、近年は BERT トークナイザ の前処理にも採用されています。本ツールは IPADIC を選択していますが、これは (1) Elasticsearch との出力一致が NLP パイプライン構築で価値が高い、(2) ブラウザ内 12MB サイズで動作する現実性、(3) 検索インデックス用途が最も普及している前処理パターンであるため、の 3 点が理由です。mecab-ipadic-NEologd を組み込めば新語対応は向上しますが、辞書サイズが 100MB を超えてしまうトレードオフがあります。トークン化した本文の読みをまとめて確認したい場合は kanji-to-hiragana が、ふりがな付き HTML を出力したい場合は furigana-html が同じ kuromoji 基盤で動作します。
Viterbi アルゴリズムと品詞細分類の精度限界
形態素解析エンジン (MeCab・kuromoji・Sudachi) は内部で Viterbi アルゴリズム を使い、文を構成しうるすべての切り方の中から「辞書コスト + 連接コストの合計が最小」になるパスを動的計画法で探索します。東京都内 という入力に対して 東京 + 都 + 内・東京都 + 内・東京 + 都内 の 3 候補が考えられる場合、辞書登録された各単語のコスト (emission cost) と前後品詞の連接コスト (transition cost) を加算した最小値で最も妥当な分割を選びます。IPADIC の連接コスト表は約 70 × 70 = 4900 通り の品詞遷移を持っており、これが日本語の文法的制約 (「助詞の後に動詞が来る」「助動詞は活用語の後ろ」など) を統計的に表現しています。
ただし Viterbi の精度には限界があります。未知語 (辞書に無い単語) は文字種ベース (カタカナ連続・漢字連続・記号連続) でヒューリスティックに切り出されますが、固有名詞・専門用語・新語は誤分割しやすくなります。同形異音語 (東風 = こち / とうふう、生家 = せいか / しょうか) は Viterbi では選択できず、文脈ベースの曖昧性解消 (BERT や RoBERTa のような pretrained model) が必要になります。長距離依存 (主語と動詞が離れている文) も Viterbi の局所最適化では捉えきれず、京都に住んでいる友人が東京に来た のような文では 京都 と 住む の関係を Viterbi 単独で正しく解析するのは困難です。NLP の本番ピペラインでは形態素解析の出力をベースに Universal Dependencies 構文解析 (GiNZA、spaCy 日本語モデル) や Transformer ベースのモデル (東北大 BERT・早稲田 RoBERTa) を組み合わせて精度を上げるのが現代的な実装です。本ツールの分かち書き出力はこれらの上位解析の入力としても活用できる、汎用的な前処理基盤です。
よくある質問
- kanji-to-hiragana / furigana-html との違いは?
- kanji-to-hiragana は **読みの一括ひらがな化** (本文 → ひらがな)、furigana-html は **`<ruby>` HTML 生成** (Web コンテンツ用)。本ツールは **分かち書き + 形態素詳細** で、NLP / 検索インデックス / Word2Vec の学習データ前処理など機械処理用途に特化。同じ kuromoji を使うが、出力形式と目的が異なる。
- 分かち書きって何に使う?
- (1) 検索エンジンのトークン化 (Elasticsearch の kuromoji analyzer や Algolia / Meilisearch の日本語対応)、(2) Word2Vec / fastText / BERT の学習データ前処理、(3) tf-idf / BM25 のドキュメントベクトル化、(4) GiNZA / spaCy で日本語 NLP するときの sanity check、など。
- 品詞 (POS) は何種類?
- kuromoji の IPADIC では大分類 13 種類 (名詞 / 動詞 / 形容詞 / 副詞 / 連体詞 / 接続詞 / 感動詞 / 助詞 / 助動詞 / 接頭詞 / 記号 / フィラー / その他)。さらに細分類 (1〜4 段階) が付与され、たとえば名詞は「サ変接続」「形容動詞語幹」「数」「副詞可能」など。表ではすべて表示されます。
- 「基本形に正規化」って?
- 活用語 (動詞・形容詞・助動詞) の表層形を **辞書形** (見出し語) に置き換えるオプション。例: 「走っ」→「走る」、「美しかっ」→「美しい」。検索インデックスや tf-idf でクエリ表記揺れに強くしたいとき有効。英語の lemmatization と同じ概念。
- 「内容語のみ」フィルタは何を残す?
- 名詞・動詞・形容詞を保持し、助詞 (が / は / を など)・助動詞 (です / ます / られる)・記号・接続詞・フィラー (えー / あー) を除外します。検索キーワード抽出や Word2Vec の学習データ作成で **意味的に重要な語** だけ欲しいときに。
- 辞書サイズ (12 MB) が大きいけど大丈夫?
- 初回ロード時のみブラウザにキャッシュされ (Service Worker / HTTP Cache)、以降はオフライン動作します。kuromoji の IPADIC は標準的な日本語形態素辞書 (約 39 万語) で、より軽量な辞書 (例: NAIST-JDic) もありますが kuromoji.js の標準を使用。
- 辞書はサーバーに送信される?
- いいえ。kuromoji 辞書はクライアントに bundle されてブラウザだけで動きます。入力テキストも外部に送信されません。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール
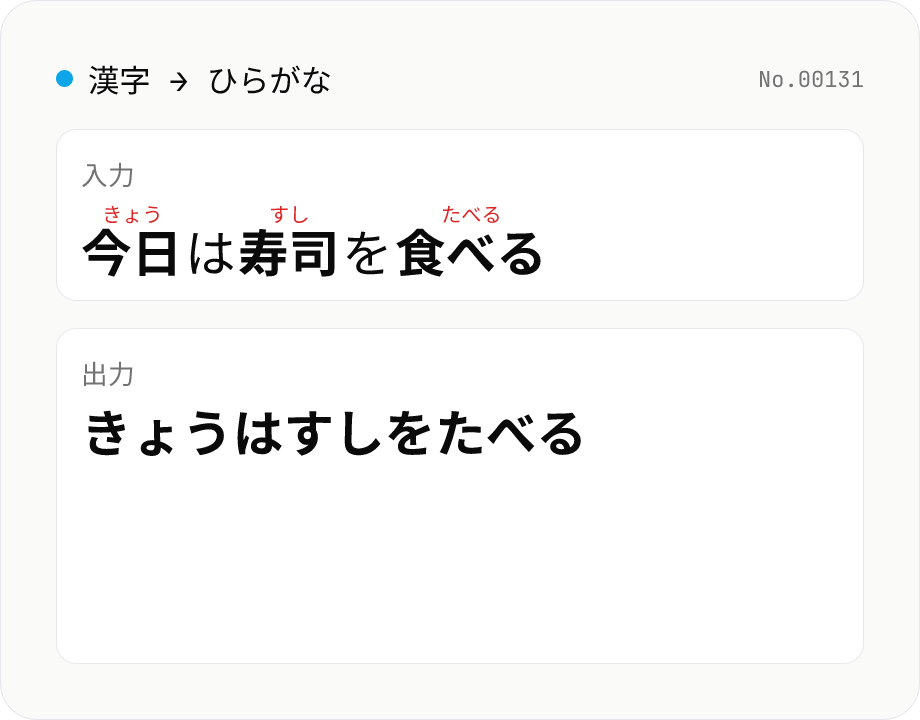
漢字 → ひらがな 変換 — kuromoji 形態素解析で読み付与
日本語テキストを kuromoji の形態素解析で読み (ひらがな) に変換します。全文ひらがな化と、漢字の上にルビを振る「ふりがな」モードに対応。辞書は初回のみブラウザにダウンロードされ、以降はオフライン動作。すべてブラウザ内で処理。
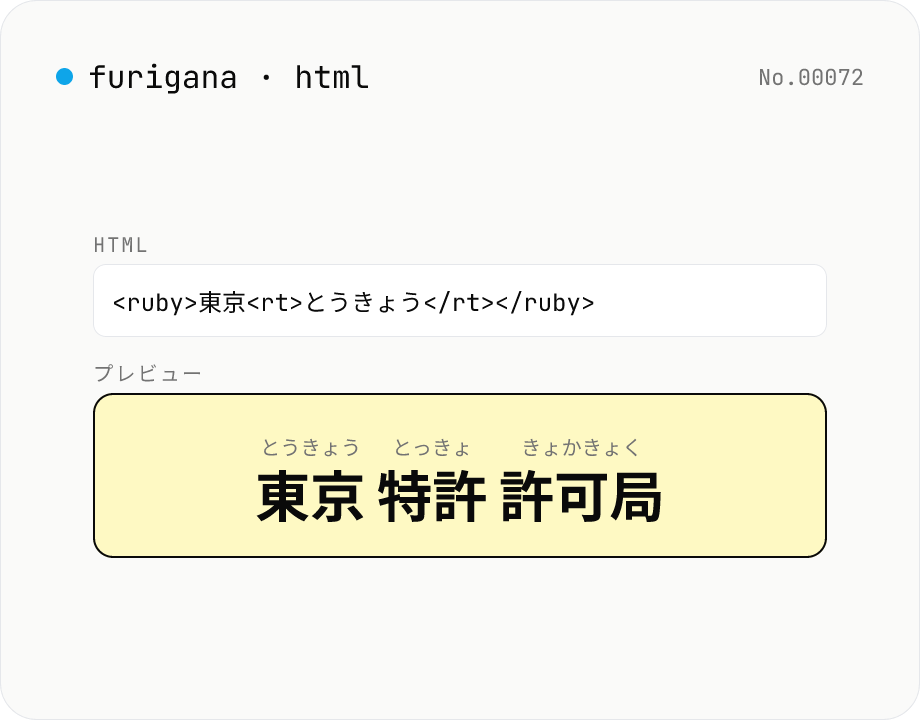
ふりがな HTML 生成 — <ruby> タグで漢字に振る
日本語テキストを kuromoji で形態素解析し、漢字部分に `<ruby>漢字<rt>かんじ</rt></ruby>` のふりがな HTML を付与したソースコードを出力します。WordPress / 各種 CMS / Markdown 記事に貼り付けて使えます。フリガナはひらがな・カタカナを選択可能。`<rp>` フォールバックも追加可能。すべてブラウザ内で処理します。
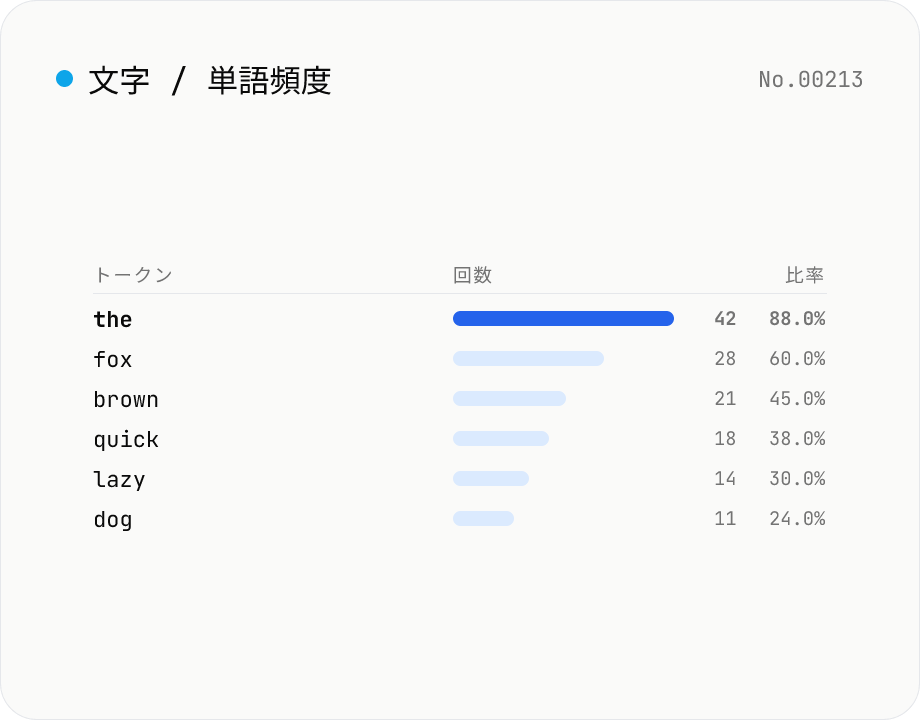
文字頻度カウント — 文字 / 単語 / 行を集計
テキスト中の文字・単語・行の出現回数を集計して降順に表示。大文字小文字の正規化や空白の除外を切り替え可能で、結果は CSV として書き出せます。すべてブラウザ内で処理するため、原稿・ログ・チャット履歴をそのまま貼り付けても外部に送信されません。

文字数カウント — 文字 / バイト / 行 / 単語
テキストの文字数・単語数・行数・段落数・UTF-8 バイト数をリアルタイムで集計。空白・改行を含めるか除くかを切り替え可能で、Twitter・原稿用紙 (400 字)・LINE などの文字数上限の進捗バーも同時表示。すべてブラウザ内で動くので、原稿や下書きを安全にカウントできます。