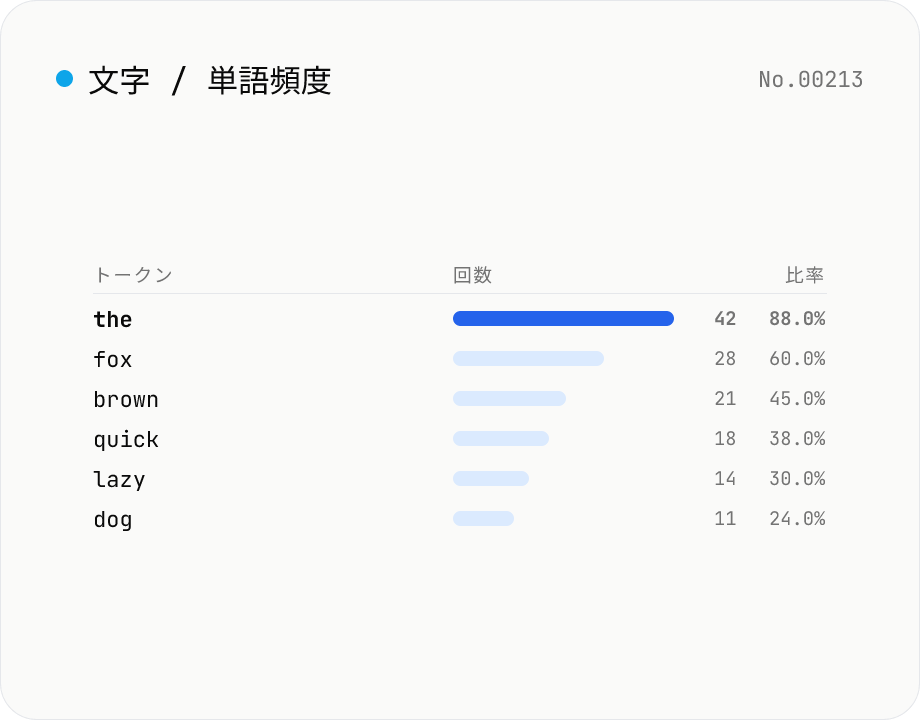
文字頻度カウント — 文字 / 単語 / 行を集計
テキスト中の文字・単語・行の出現回数を集計して降順に表示。大文字小文字の正規化や空白の除外を切り替え可能で、結果は CSV として書き出せます。すべてブラウザ内で処理するため、原稿・ログ・チャット履歴をそのまま貼り付けても外部に送信されません。
使い方
集計単位 (文字 / 単語 / 行) を選び、テキストを貼り付けて「頻度を集計」を押すと、出現回数の多い順にトークンが表示されます。「大文字小文字を区別しない」のチェックで A と a をまとめて数えたり、文字モードのみ「空白文字を除外する」で空白・改行を集計から外したりできます。結果は TSV のコピーまたは CSV のダウンロードで Excel / スプレッドシートに渡せます。すべてブラウザ内で完結し、入力テキストはサーバーに送信されません。
よくある質問
- 入力テキストはサーバーに送信されますか?
- いいえ。集計はすべてブラウザ内の JavaScript で行います。ログや原稿、チャット履歴をそのまま貼り付けても安全です。
- 文字モードと単語モードの違いは?
- 文字モードはコードポイント単位 (Hello → H, e, l, l, o)、単語モードは空白で区切ったかたまり (Hello world → Hello, world) の集計です。日本語のように単語が空白で区切られない言語では文字モードか、専用の形態素解析ツール (例: kuromoji ベースの furigana-html) を別途使ってください。
- 行モードはログ分析に使えますか?
- はい。同じ行が何度繰り返されているか即座にわかるので、エラーログのパターン抽出や、よくある問い合わせ文の集計に向いています。空行は自動で除外されます。
- 「大文字小文字を区別しない」は具体的に何をしますか?
- 集計時に各トークンを `toLowerCase()` で正規化してから数えます。表示も正規化後の小文字で出ます。元の大文字を保ちたい場合はオフにしてください。
- 上位 N 件だけ見るには?
- 現バージョンではすべて表示します。CSV をダウンロードして Excel / スプレッドシートでフィルタするか、結果テーブルをスクロールしてください。多数の固有トークンがある場合 (数万件以上) はブラウザが重くなることがあるので、サンプルを縮めてから試すのがおすすめです。
- 比率 (%) はどう計算されますか?
- そのトークンの出現回数 ÷ 全トークン数 × 100、小数第 2 位までです。文字モードで空白を除外している場合は、除外後の総文字数で割っています。
類似のツール

文字数カウント — 文字 / バイト / 行 / 単語
テキストの文字数・単語数・行数・段落数・UTF-8 バイト数をリアルタイムで集計。空白・改行を含めるか除くかを切り替え可能で、Twitter・原稿用紙 (400 字)・LINE などの文字数上限の進捗バーも同時表示。すべてブラウザ内で動くので、原稿や下書きを安全にカウントできます。
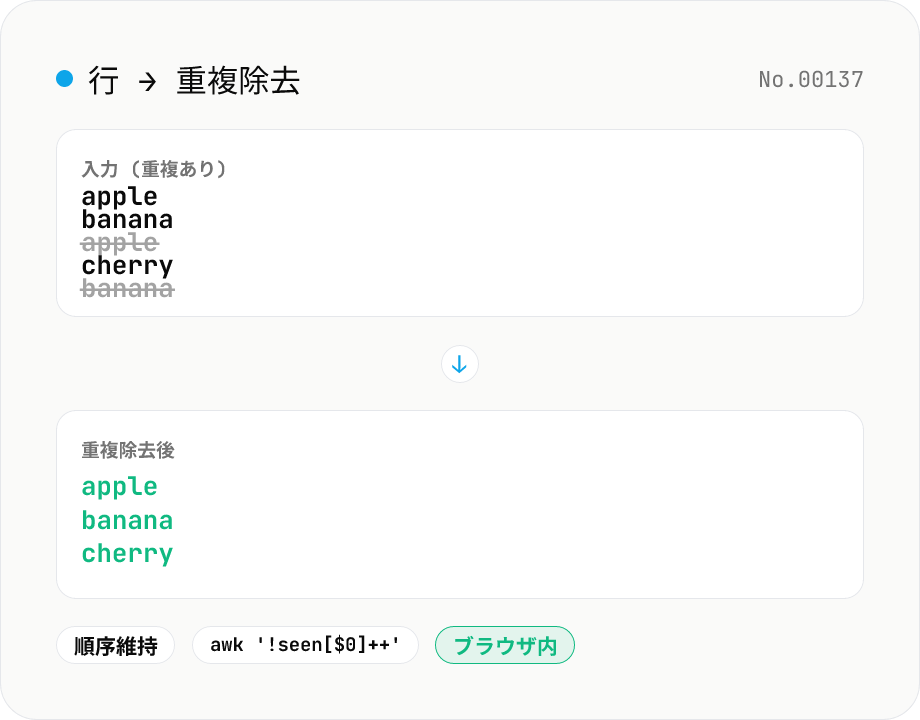
行重複削除 — 全部一意化 / 重複だけ抽出
テキストを行 (\n) で分割し、重複する行を除去します。初出の行だけを保持し、元の順序を維持。連続した重複だけでなく離れた位置の重複も対象 (Unix `awk '!seen[$0]++'` 相当)。すべてブラウザ内で処理。

CSV / テキスト文字コード変換 — Shift_JIS ⇄ UTF-8 / BOM / 改行
Shift_JIS (CP932) と UTF-8、UTF-16LE、EUC-JP の間で CSV / テキストファイルを変換します。Excel が出す Shift_JIS の文字化け、UTF-8 のテキストを古いシステムに渡せない問題、Excel が BOM 無し UTF-8 を文字化けさせる問題などに対応。BOM 付与/除去、改行コード (CRLF / LF / CR) の差し替え、入力エンコーディング自動判定をサポート。複数ファイルを一括変換して ZIP で受け取れます。アップロードしたファイルは外部に送信されず、すべての処理はブラウザ内で完結します。
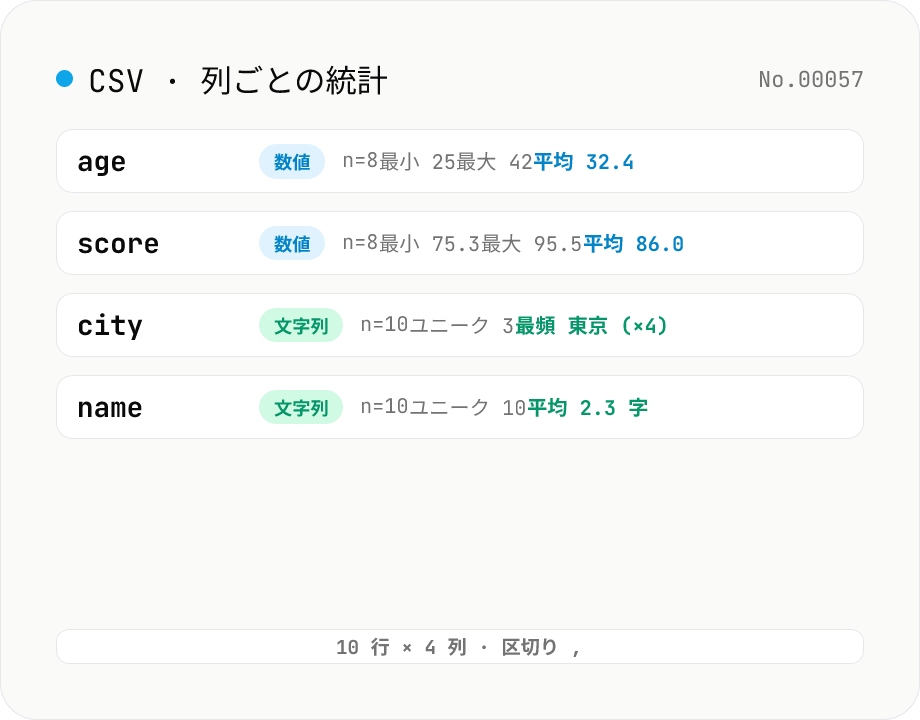
CSV 統計 — 列ごとの件数 / ユニーク / 平均 / 中央値 / 標準偏差
CSV を貼り付けるかドロップするだけで、列ごとの行数・ユニーク値数・欠損数・推定型を自動集計します。数値列は最小 / 最大 / 平均 / 中央値 / 標準偏差 / 合計、文字列列は最頻値 (top 1) と平均文字数を表示。RFC 4180 準拠 (ダブルクォート・エスケープ対応)、区切りはカンマ / セミコロン / タブ / パイプを自動判定。ヘッダー行の有無トグルあり、欠損は空欄と NULL/NA を欠損扱い。生データは一切外部送信されず、すべてブラウザ内で完結します。