
PDF テキスト抽出 — .txt 書き出し
PDF からプレーンテキストをブラウザ内だけで抽出します。pdfjs-dist の getTextContent でページごとに文字列を集め、1 ファイル = 1 つの .txt として書き出し。複数 PDF はまとめて ZIP でダウンロードできます。ページ区切りマーカーの有無は切り替え可能。
使い方
PDF をドロップ (複数可)。「テキストを抽出」を押すと、pdfjs-dist が各ページの文字オブジェクトを順番に読み出し、ファイルごとに 1 つの .txt にまとめます。各ファイルを個別に Copy / Download するか、全件を ZIP で一括ダウンロードできます。「ページ区切りを挿入」オプションで `---- Page N ----` の区切りを入れるかどうかを選べます。
よくある質問
- PDF はサーバーに送信されますか?
- いいえ。pdfjs-dist をブラウザ内で動かしているので、PDF は端末外には出ません。
- スキャン画像の PDF からテキストは取れますか?
- 取れません。文字レイヤを持たない (画像だけの) PDF は OCR が必要で、このツールでは対象外です。
- 段組みや表のレイアウトは保たれますか?
- PDF の文字配置を逐次読み出すだけなので、複雑な段組みや表構造は壊れます。プレーンテキストとして書き出される、と理解してください。
- パスワード付き PDF は処理できますか?
- 暗号化されていると読み込みに失敗します。先に PDF 保護解除ツールで暗号化を外してください。
類似のツール
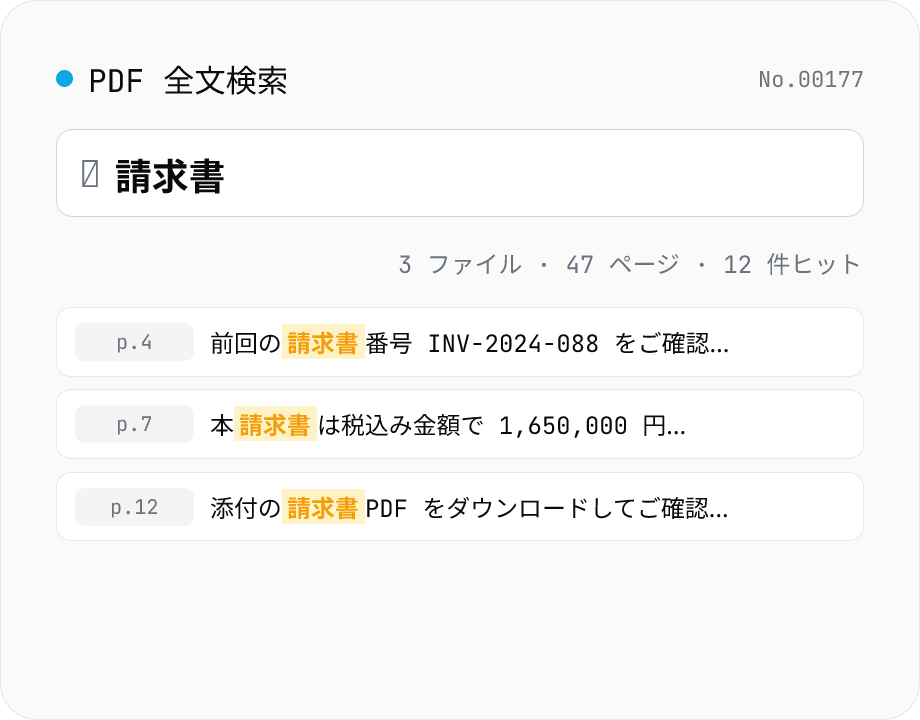
PDF 全文検索 — 複数 PDF を横断検索
複数の PDF をまとめて全文検索し、ヒットしたページ番号 + 行の前後を抜粋表示します。大文字小文字の区別、単語境界 (\b)、正規表現、複数行モードの 4 オプション。検索クエリと前後文字数 (10〜200 字) を変えるとリアルタイムで再抽出。ファイルごとのヒット件数を一覧でき、結果は CSV としてダウンロード可能。アップロードした PDF はサーバーに送信されず、すべてブラウザ内で完結します。

PDF を JPG 画像に変換 — ページ単位で出力
PDF をアップロードして各ページを JPEG (.jpg) に変換します。解像度と画質を選んで、個別ページの保存や ZIP 一括ダウンロードに対応。透過は白で埋まりますが、ファイルサイズが軽く SNS / ブログにそのまま貼りやすい形式です。すべてブラウザ内で処理し、PDF は外部に送信されません。
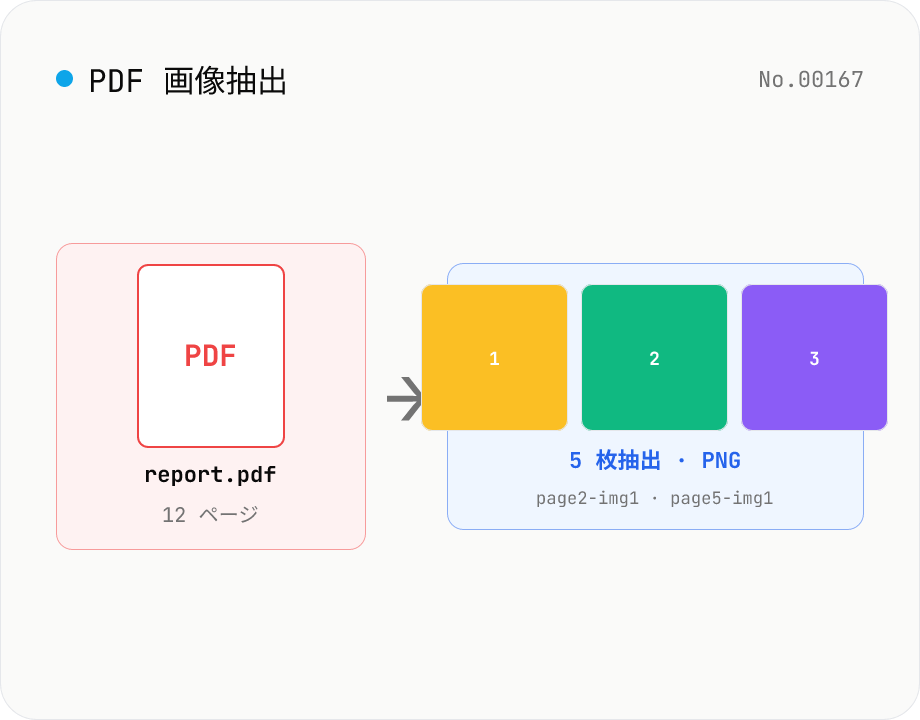
PDF 画像抽出 — 埋め込み画像を PNG として書き出し
PDF に埋め込まれた画像を pdfjs-dist で 1 枚ずつ取り出し、PNG として書き出します。`getOperatorList()` で各ページの `paintImageXObject` / `paintInlineImageXObject` / `paintImageXObjectRepeat` を走査し、`page.objs` から ImageBitmap または raw RGB(A)/Grayscale データを取得して Canvas 経由で PNG 化。同じ画像が複数ページで使い回されている場合は重複除去 (オプション)。複数 PDF はまとめて ZIP でダウンロードできます。各画像にはページ番号と元のサイズが付与され、ファイル名は `<元PDF名>-page<N>-img<M>.png` 形式。パスワード保護 PDF は事前検知して pdf-unlock への CTA を表示。画像処理はすべてブラウザ内で完結します。

PDF メタデータ削除 — Title / Author / XMP 一括
PDF の Info 辞書 (Title / Author / Subject / Keywords / Creator / Producer / CreationDate / ModDate) と XMP メタストリームを pdf-lib でブラウザ内だけで削除します。本文・ページ構造には触らないので画質や中身は変わりません。複数ファイル一括処理 + ZIP ダウンロード対応。