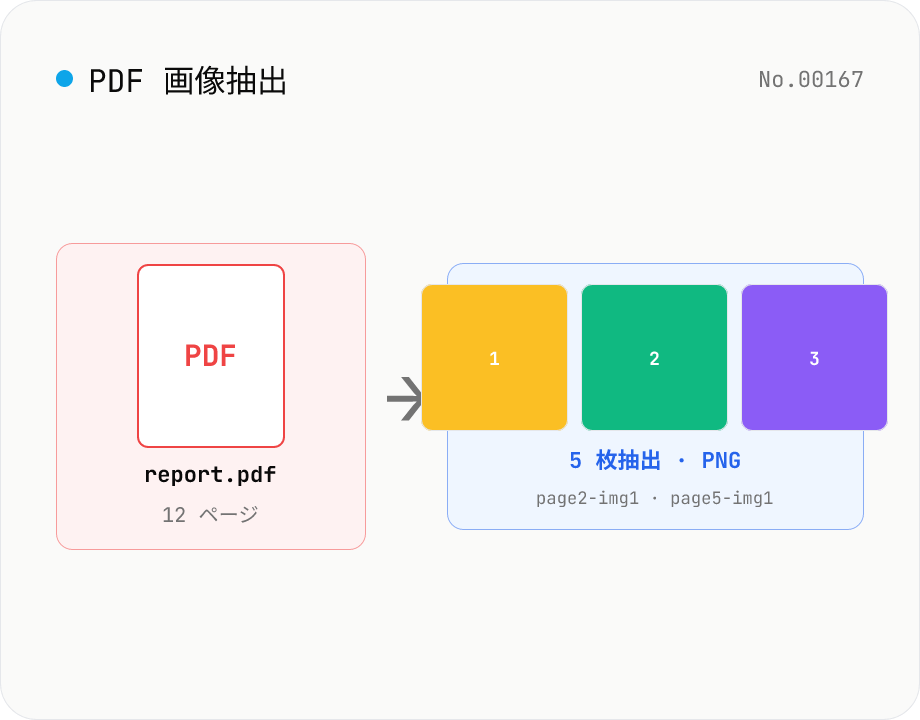
PDF 画像抽出 — 埋め込み画像を PNG として書き出し
PDF に埋め込まれた画像を pdfjs-dist で 1 枚ずつ取り出し、PNG として書き出します。`getOperatorList()` で各ページの `paintImageXObject` / `paintInlineImageXObject` / `paintImageXObjectRepeat` を走査し、`page.objs` から ImageBitmap または raw RGB(A)/Grayscale データを取得して Canvas 経由で PNG 化。同じ画像が複数ページで使い回されている場合は重複除去 (オプション)。複数 PDF はまとめて ZIP でダウンロードできます。各画像にはページ番号と元のサイズが付与され、ファイル名は `<元PDF名>-page<N>-img<M>.png` 形式。パスワード保護 PDF は事前検知して pdf-unlock への CTA を表示。画像処理はすべてブラウザ内で完結します。
使い方
1) PDF ファイルを 1 〜複数件ドロップエリアにドロップします。 2) オプションで『重複画像を 1 枚にまとめる』『小さい画像 (短辺 N px 未満) を除外』を設定。 3) 『画像を抽出』を押すと各 PDF を 1 ファイルずつ解析し、ページごとの埋め込み画像を PNG に変換します。 4) 抽出された画像はファイル単位のカードでサムネイル表示、個別にダウンロードするか『全件 ZIP』でまとめて取得できます。
よくある質問
- どんな画像が抽出できますか?
- PDF オペレータ `paintImageXObject` / `paintInlineImageXObject` / `paintImageXObjectRepeat` で描画される画像オブジェクト (XObject Image) です。ベクター描画 (パス・テキスト) は対象外。レンダリング後のページ全体を画像化したい場合は『PDF → PNG』『PDF → JPG』ツールを使ってください。
- 重複検出はどう動きますか?
- 各画像のピクセル RGBA バッファの先頭 / 末尾 / 中央サンプルから簡易ハッシュを取り、サイズが同じで同ハッシュなら重複と判定します。ロゴや背景画像など、複数ページで使い回される素材を 1 枚にまとめられます。完全に同一のバイト列であれば必ず検出されますが、視覚的に同じでもエンコードが違えば別画像として扱います。
- 出力は PNG だけですか? 元のエンコード形式 (JPEG など) は維持されないのですか?
- 出力は PNG のみです。pdf.js は描画用にデコード済みのピクセルデータを `page.objs` に格納するため、元 JPEG / JBIG2 / JPEG2000 のバイト列にはアクセスできません。元のエンコード形式が必要な場合は別ツール (mutool 等のネイティブツール) が必要になります。
- マスク画像 (paintImageMaskXObject) は抽出されますか?
- 意図的に対象外にしています。マスクはテキストの形状切り抜きなどに使われる 1bit 画像で、単独で意味のある画像になることが少ないため。本ツールは『写真』『ロゴ』のような描画リソースとしての画像のみを対象にしています。
- パスワード保護 PDF はどうなりますか?
- 事前検知して『パスワード保護されているため処理できません』エラーを表示します。リストに保護 PDF があるとバナーで『PDF パスワード解除』ツールへの導線が出るので、先に保護を解除してから再度ドロップしてください。
- 画像が見つからない PDF はどうなりますか?
- 『画像が検出されませんでした』と表示されます。スキャン PDF (1 ページ全体が 1 枚の画像) でも検出されるはずですが、独自エンコード等で抽出に失敗するケースもあります。その場合は『PDF → PNG』『PDF → JPG』でページ全体を画像化する方が確実です。
- ファイル名のルールは?
- `<元PDF名>-page<N>-img<M>.png` の形式です。N はページ番号 (1 始まり)、M は当該ページ内の画像インデックス (1 始まり)。元 PDF 名は拡張子を除き、特殊文字を `_` に置換します。
- 入力データはサーバーに送信されますか?
- いいえ。PDF の解析・画像のデコード・PNG への再エンコードはすべてブラウザ内 (Web Worker + Canvas) で完結し、ネットワークには送信しません。
類似のツール

PDF テキスト抽出 — .txt 書き出し
PDF からプレーンテキストをブラウザ内だけで抽出します。pdfjs-dist の getTextContent でページごとに文字列を集め、1 ファイル = 1 つの .txt として書き出し。複数 PDF はまとめて ZIP でダウンロードできます。ページ区切りマーカーの有無は切り替え可能。

PDF を PNG 画像に変換 — 透過対応
PDF をアップロードして各ページを PNG に変換。個別保存・ZIP 一括ダウンロードに対応。すべてブラウザ内で処理。

PDF を JPG 画像に変換 — ページ単位で出力
PDF をアップロードして各ページを JPEG (.jpg) に変換します。解像度と画質を選んで、個別ページの保存や ZIP 一括ダウンロードに対応。透過は白で埋まりますが、ファイルサイズが軽く SNS / ブログにそのまま貼りやすい形式です。すべてブラウザ内で処理し、PDF は外部に送信されません。
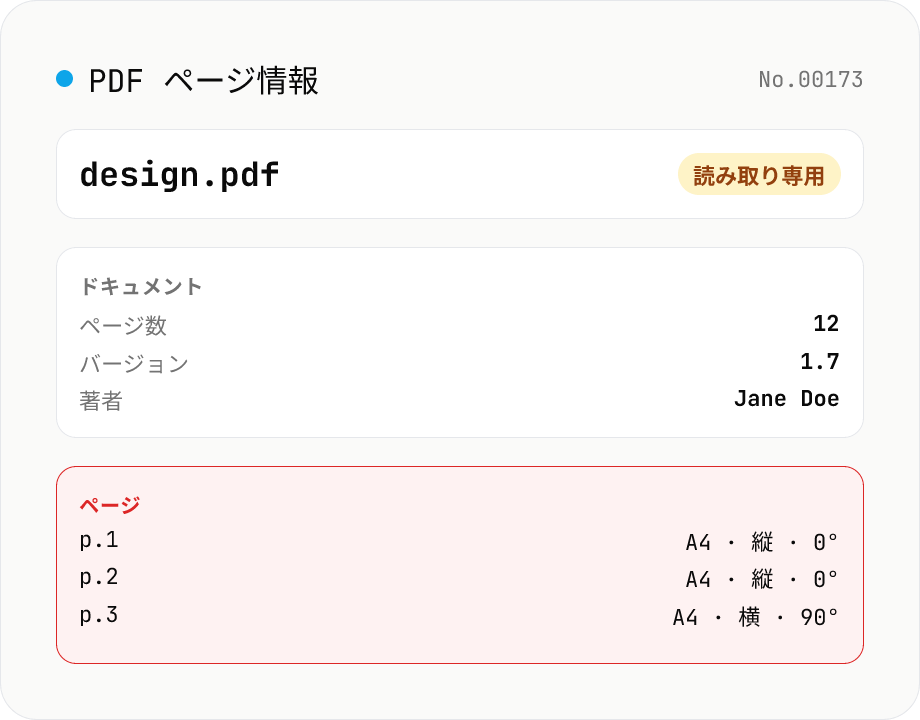
PDF ページ情報ビューア
PDF をドロップして、各ページのサイズ (A4 / Letter などの紙サイズ自動判定)・縦横比・向き・回転・注釈数・テキスト有無・画像有無・PDF バージョン・タイトルや作成者などのメタを一覧表示します。書き換えなしの読み取り専用、pdfjs-dist でブラウザ内のみ実行。