PDF ページ情報ビューア
PDF をドロップして、各ページのサイズ (A4 / Letter などの紙サイズ自動判定)・縦横比・向き・回転・注釈数・テキスト有無・画像有無・PDF バージョン・タイトルや作成者などのメタを一覧表示します。書き換えなしの読み取り専用、pdfjs-dist でブラウザ内のみ実行。
使い方
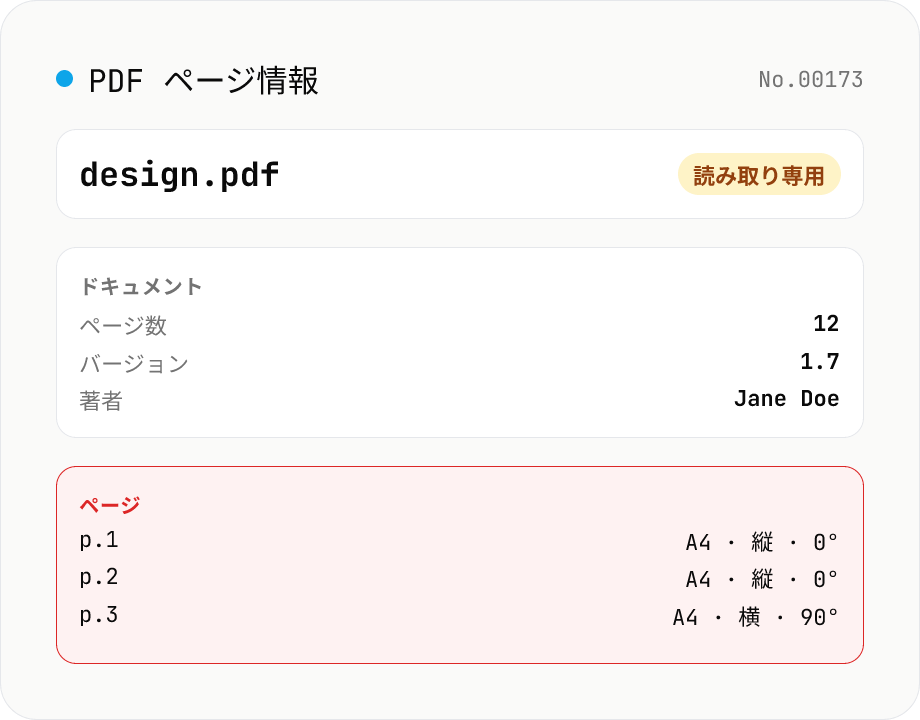
PDF をドロップすると、ブラウザ内に読み込んだ pdfjs-dist が解析し、ドキュメント全体のメタ情報 (PDF バージョン、タイトル、著者、サブジェクト、キーワード、作成・更新日時、AcroForm / XFA / 署名の有無) と、ページごとの情報 (ページ番号、サイズ pt 表示・mm 表示・紙サイズ判定 (A4 / Letter / B5 など)、向き、回転、注釈数、テキスト有無、画像有無) を一覧表示します。書き換えは行わない読み取り専用ツール、複数 PDF を同時にドロップ可能。
よくある質問
- PDF はサーバーに送信されますか?
- いいえ。pdfjs-dist はブラウザ内で wasm + JavaScript として動作し、PDF は外部に送信されません。社内文書や未公開原稿も安心して解析できます。
- 紙サイズはどのように判定していますか?
- ページの矩形 (pt 単位) を ISO A 系 (A0〜A6)、ISO B 系 (B4 / B5)、US (Letter / Legal / Tabloid / Executive)、JIS (B4 / B5 / はがき) と照合します。±2pt の誤差を許容しているので、PDF 由来の僅かな丸めズレも吸収します。マッチしない場合は「カスタム」として pt / mm の生値のみ表示します。
- テキスト有無・画像有無はどう判定していますか?
- テキストはページの `getTextContent()` を呼んで結果が空でないかをチェック。画像はオペレータリストを走査して画像描画系のオペレータ (`paintImageXObject` / `paintInlineImageXObject` など) が含まれているかを確認しています。
- 暗号化された PDF は解析できますか?
- 本ツールでは パスワード入力 UI を持たないため、暗号化 PDF はエラーとしてスキップします。先に `pdf-unlock` で保護解除してから再度ドロップしてください。
- 回転 (Rotation) と向き (Orientation) は何が違いますか?
- 向きはページの **寸法そのもの** (横幅 > 高さなら横、逆なら縦) を見て判定。回転は PDF の `/Rotate` 値 (0 / 90 / 180 / 270) を表示。両方を見ることで「ページ自体は縦長だが回転メタが 90° で横向きに表示される」ようなケースが分かります。
類似のツール

PDF テキスト抽出 — .txt 書き出し
PDF からプレーンテキストをブラウザ内だけで抽出します。pdfjs-dist の getTextContent でページごとに文字列を集め、1 ファイル = 1 つの .txt として書き出し。複数 PDF はまとめて ZIP でダウンロードできます。ページ区切りマーカーの有無は切り替え可能。

PDF メタデータ削除 — Title / Author / XMP 一括
PDF の Info 辞書 (Title / Author / Subject / Keywords / Creator / Producer / CreationDate / ModDate) と XMP メタストリームを pdf-lib でブラウザ内だけで削除します。本文・ページ構造には触らないので画質や中身は変わりません。複数ファイル一括処理 + ZIP ダウンロード対応。

PDF 回転 — 90 / 180 / 270 度で一括
PDF のすべてのページを 90° / 180° / 270° (時計回り) で一括回転し、新しい PDF として出力します。複数の PDF をまとめて処理でき、結果は 1 件ずつ、または ZIP でまとめてダウンロードできます。アップロードした PDF はサーバーに送信されず、すべてブラウザ内で完結します。

PDF 分割 — ページ範囲指定 / N ページごと
1 つの PDF をページ範囲指定 / N ページごと / 全ページ個別の 3 モードで分割し、ZIP でまとめてダウンロードします。すべてブラウザ内で処理。