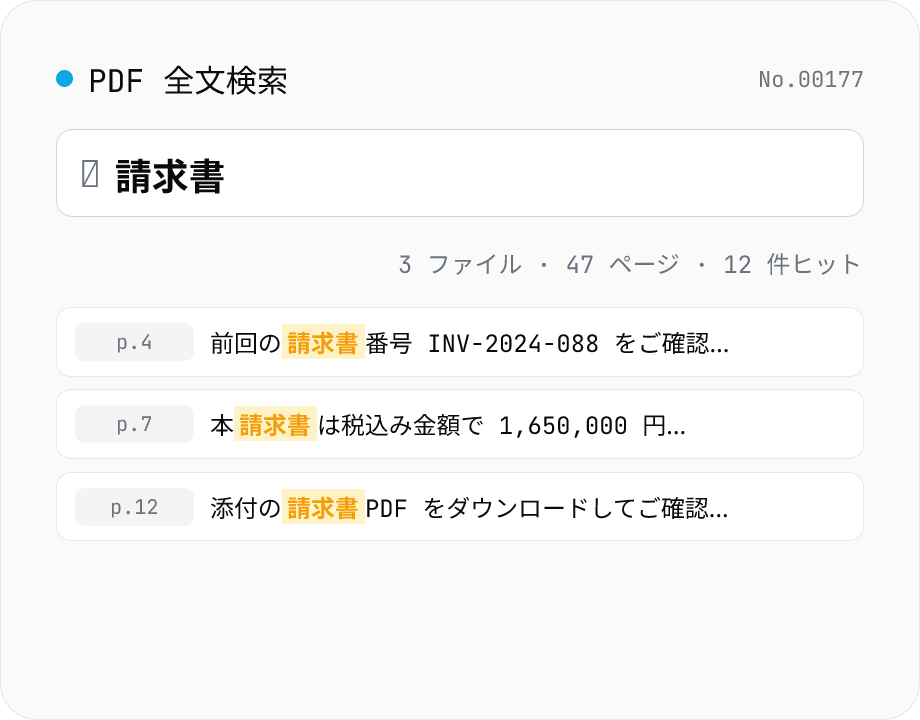
PDF 全文検索 — 複数 PDF を横断検索
複数の PDF をまとめて全文検索し、ヒットしたページ番号 + 行の前後を抜粋表示します。大文字小文字の区別、単語境界 (\b)、正規表現、複数行モードの 4 オプション。検索クエリと前後文字数 (10〜200 字) を変えるとリアルタイムで再抽出。ファイルごとのヒット件数を一覧でき、結果は CSV としてダウンロード可能。アップロードした PDF はサーバーに送信されず、すべてブラウザ内で完結します。
使い方
PDF を 1 件以上ドロップしてから検索クエリを入力すると、ページ番号 + 行の前後文字を抜粋して表示します。検索オプションは「大文字小文字の区別」「単語単位 (\b 境界)」「正規表現」「複数行モード (s フラグ)」の 4 種類で、いずれもチェックを変えると即座に再検索が走ります。前後文字数 (10〜200 字) は出力の文脈幅を調整するスライダ。各 PDF カードには「{n} 件ヒット · {m} ページ」が出るので、まずファイル単位の存在判定を素早く済ませてから具体的なヒット行を確認するワークフローに向きます。結果一覧は CSV (file, page, line, context, match) としてダウンロードできます。
よくある質問
- アップロードした PDF はサーバーに送信されますか?
- いいえ。pdfjs-dist でブラウザ内でテキスト抽出し、そのまま検索もブラウザの JavaScript エンジンで実行します。アップロード先のサーバーは存在しません。
- スキャン PDF (画像のみ) は検索できますか?
- テキストレイヤを持つ PDF (印刷可能なテキスト) のみ検索可能です。OCR 済みのスキャン PDF なら検索できますが、純粋な画像 PDF はヒット 0 件になります。
- 正規表現はどこまで対応していますか?
- ブラウザの JavaScript RegExp をそのまま使うので、ECMAScript 仕様の文法 (キャプチャ・後方参照・先読み等) はすべて利用可能です。Unicode property escape (`\p{Letter}` 等) や名前付きキャプチャも有効です。スラッシュ区切り (`/foo/i`) は不要。フラグはチェックボックスで指定してください。
- 「複数行モード」は何を変えますか?
- デフォルトは PDF 内のテキストを行ごとに切ってマッチを取ります。複数行モードを ON にすると全文を 1 つの文字列として連結し、改行を跨ぐマッチや `.` で改行も含めたマッチを検出します (s フラグ相当)。1 つのヒットが複数行に及ぶときの文脈幅も広めに表示されます。
- パスワード保護された PDF は処理できますか?
- いいえ。pdf-unlock ツールで先に保護を解除してから再度読み込んでください。エラー時には専用バナーから自動で誘導します。
- 結果が多いとブラウザが固まりませんか?
- 1 ファイルあたりのヒット数を上限なくレンダリングするため、極端に大量のマッチ (例: 1 万件) があると遅くなります。クエリを絞るか、CSV ダウンロードで全件取得してから分析することを推奨します。
類似のツール

PDF テキスト抽出 — .txt 書き出し
PDF からプレーンテキストをブラウザ内だけで抽出します。pdfjs-dist の getTextContent でページごとに文字列を集め、1 ファイル = 1 つの .txt として書き出し。複数 PDF はまとめて ZIP でダウンロードできます。ページ区切りマーカーの有無は切り替え可能。
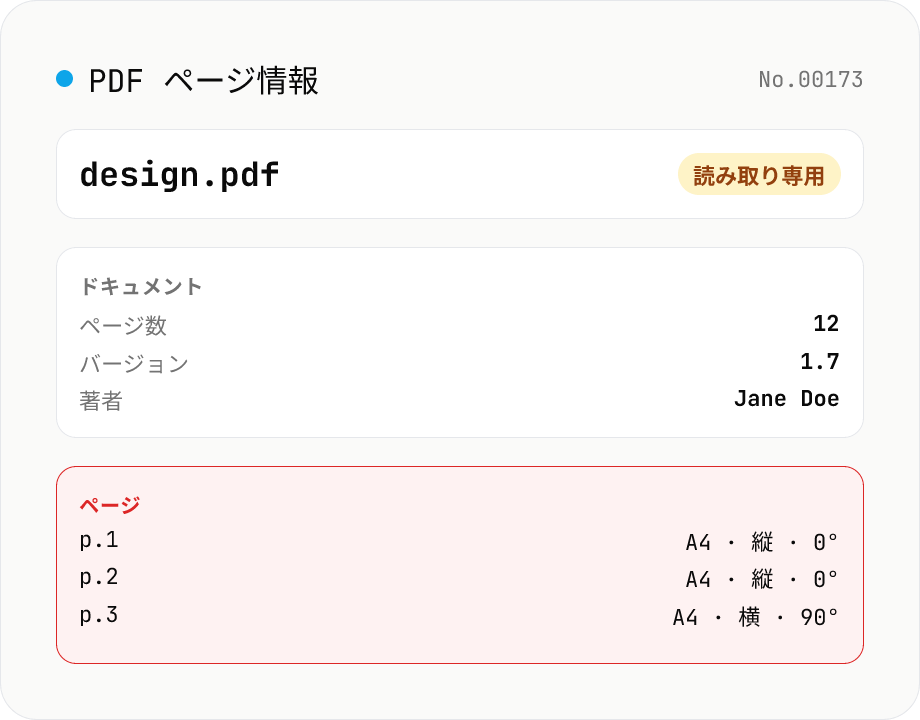
PDF ページ情報ビューア
PDF をドロップして、各ページのサイズ (A4 / Letter などの紙サイズ自動判定)・縦横比・向き・回転・注釈数・テキスト有無・画像有無・PDF バージョン・タイトルや作成者などのメタを一覧表示します。書き換えなしの読み取り専用、pdfjs-dist でブラウザ内のみ実行。

PDF 結合 — 複数 PDF を 1 つにまとめる
複数の PDF をドラッグ&ドロップで並び替えて 1 つの PDF に結合します。すべてブラウザ内で処理。
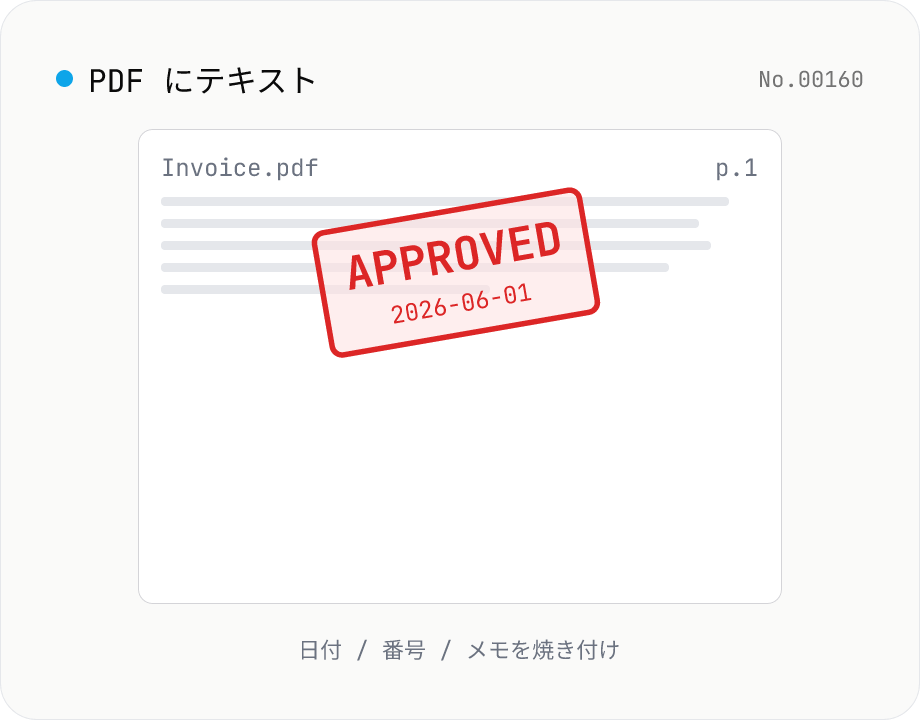
PDF にテキストを書き込む — 注釈 / 日付 / メモを焼き付け
PDF の指定ページにテキストを書き込みます。「日付」「メモ」「ファイル番号」など、見栄えだけ整えればよい英数字の注釈を後付けする用途に最適。位置は 9 グリッド + 余白、フォントサイズ・色・回転・不透明度を調整できます。フォントは pdf-lib 標準の Helvetica (Regular / Bold / Oblique) を使うため英数字専用。日本語テキストを書き込みたい場合は stamp-jp で印鑑風画像を作って pdf-add-image で貼る方法を推奨。複数の PDF をまとめて処理でき、結果は ZIP でダウンロード可能。アップロードした PDF はサーバーに送信されず、すべてブラウザ内で処理されます。