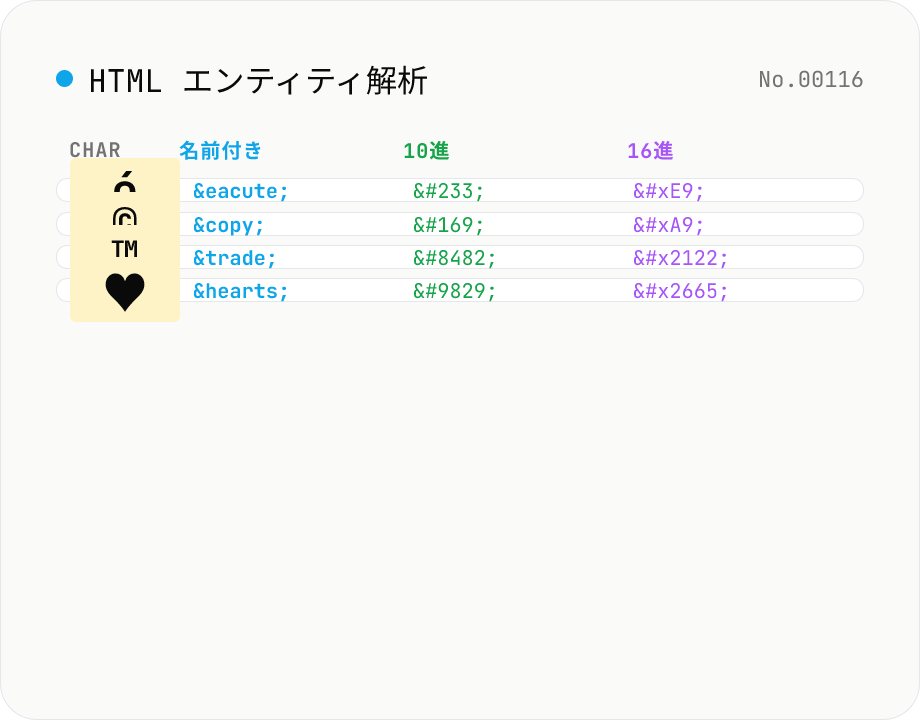
HTML エンティティ解析 — 名前付き / 10進 / 16進 / Unicode 名を並列表示
HTML エンティティを含む文字列を貼り付けると、含まれるすべてのエンティティ (`&` `é` `é` `é` ` ` `©` 等) を検出し、**実際の文字 / 名前付きエンティティ / 10 進数値参照 / 16 進数値参照 / Unicode コードポイント** を一覧表で並列表示します。逆方向の検索 (文字 → エンティティ表記) もサポート: たとえば `é` を入れると 名前付き `é` / 数値 `é` / 16 進 `é` を一気に取得できます。HTML5 仕様の **2125 個の名前付きエンティティ** すべてを内蔵 (`&`, `©`, `&heart;`, `∳` 等)。`html-encode` (文字列全体を encode/decode する) と `unicode-inspect` (Unicode コードポイント詳細) との中間ポジションで、「この絵文字を `♥` で書きたいけど名前あったっけ?」「`™` の数値表記って何?」を解決するためのリファレンスツール。すべてブラウザ内で処理、サーバー送信なし。
使い方
入力欄にエンティティを含む文字列 (例: `é © —`) または素の文字 (例: `é © —`) を貼り付け。 各エンティティ・特殊文字について、文字 / 名前付き / 10進 / 16進 / Unicode コードポイントが表形式で並列表示されます。 サマリで「検出数」「名前付きの数」「10進の数」「16進の数」「素の文字の数」を確認できます。 各セルの「コピー」ボタンで任意の表記をクリップボードへ。
詳細解説
エンティティが含まれるテキストが示すコンテキスト
「é の HTML エンティティを確認したい」という操作は、HTML テンプレートや CMS の本文、メールの HTML 化、ログに出力されたエスケープ済みテキストを扱っているときに生まれます。これらのテキストには、ユーザーの入力した内容、API レスポンスに含まれる個人情報、社内文書の断片が含まれることがあります。エンティティのインスペクターに「どんなエンティティが入っているか調べたい」テキストを貼り付ける行為は、そのテキストの内容ごと外部に渡すことになります。
特に「エスケープ済みのログ」を貼って解析するケースでは、本来サニタイズの対象だった機微情報 (メールアドレス、トークン文字列、内部 URL) がエンティティ化されたままテキストに残っていることが多いです。エンティティ部分だけを抜き出して見るつもりでも、構造として周囲のテキスト全体が一緒に外部へ流れる点に注意が必要です。
参照系ツールでも実際にはサーバー往復している実装が多い
辞書・リファレンス・チートシートの類のツールは「データを送っていない」感じを与えますが、実装の多くは入力された文字列をサーバーに POST して結果を返す構造を採っています。クライアントサイドのみで処理する実装と、サーバー側でログを残せる実装の見分けは、UI からはほぼ不可能です。
利用規約に「ユーザー入力データを統計目的で保持する」「サービス改善のために匿名化したログを生成する」といった条文が含まれているケースは珍しくなく、ユーザー側はそれを毎回読まずに使うのが現実です。インスペクタやリファレンスツールほど「軽い参照」のつもりで貼ってしまうため、構造的な情報流出の判断が後回しになりがちです。
WHATWG HTML5 仕様の 2125 エンティティをバンドルする仕組み
このツールは WHATWG HTML5 仕様で定義されている 2125 件の名前付きエンティティをビルド時のバンドルに含めています。入力テキストのパース・エンティティ検出・各形式への変換はすべてブラウザのメモリ内で実行され、外部 API への問い合わせは発生しません。名前付きエンティティの有無の判定は O(1) のハッシュマップ検索で行われます。
数値参照 (10 進 &#XXXX; / 16 進 &#xXXXX;) の変換は parseInt() でコードポイントを取得し String.fromCodePoint() で文字に戻す操作で、辞書引き不要です。DevTools の Network タブを開いてエンティティを入力しても、リクエストが発生しないことを確認できます。
HTML コードのエンティティ使い分けチェックリストとして
HTML ソースに特殊文字を書き込む際、「名前付き」「10 進数値参照」「16 進数値参照」のどれを使うかは、可読性・互換性・対応文字の有無で変わります。本ツールで確認してから使う形式を決めると、「™ の名前があるのに ™ を使っていた」「∳ は名前が長すぎるので数値参照の方が実用的」といった判断を素早く行えます。プロダクションコードには 16 進数値参照が安全 (あらゆるコードポイントに対応)、人間が編集するソースには名前付きが可読性が高い、という使い分けの基準として活用してください。
WHATWG パーサが許容するセミコロン省略
HTML5 仕様 (WHATWG) は 後方互換のため、特定の名前付きエンティティでセミコロンを省略できる という独特な挙動を定義しています。たとえば & (セミコロンなし) は & と同じく & にデコードされ、これは古い HTML 文書を壊さないための互換性条項です。許可されているのは 100 件強の歴史的に古い名前 (& / < / > / " / © / ® など) で、新しいエンティティ (&CounterClockwiseContourIntegral など) はセミコロン必須です。
このセミコロン省略は URL 内で意図しないデコードを起こす 罠でもあります。?param=foo©=bar という URL を HTML 属性に書くと、ブラウザは © を © と解釈して ?param=foo©=bar のように展開してしまいます。対策は属性値内では & を必ず & にエスケープすること。本ツールで「セミコロンなしでデコードされる名前」をチェックしておけば、URL を直に書く際の落とし穴に気付けます。
XML / SVG / MathML での扱いの違い
HTML が許容する 2125 件の名前付きエンティティのうち、XML が標準で認識するのはたった 5 件 だけです: & / < / > / " / '。SVG や XHTML を XML として処理する場合、© や ™ を書くとパーサが「未定義のエンティティ」としてエラーを返します。回避策は (a) DTD 宣言で必要なエンティティを定義する、(b) 数値参照に書き換える、のどちらかです。
XML 互換が必要なドキュメント (SVG ファイル、Atom フィード、XHTML 配信、EPUB 内部 XML) では、最初から数値参照 © で統一するのが安全です。MathML はさらに独自のエンティティ集合を持っており、⁢ のような MathML 専用名は HTML パーサにも認識されますが、これは WHATWG 仕様で MathML / SVG コンテキストを特別扱いしているからです。XML サブツリーをスクリプトで生成する際は、本ツールで対象文字の数値参照形式 (&#xXXXX;) を確認しておくと汎用性が高くなります。文字列全体を一括 encode / decode したいときは html-encode で双方向に切り替えられ、含まれる文字が NFC / NFD で揺れていないかを確認するときは unicode-normalize で 4 種類の正規化形式を見比べると、エンティティ名と Unicode 名の対応がきれいに揃います。
よくある質問
- 他の HTML 系ツールとの違いは?
- `html-encode` は文字列全体を encode / decode する変換ツール (テキスト → エンティティ化、または逆)。本ツールは **インスペクター** で、含まれる個々のエンティティ・文字について全 4 種類の表記を一覧表示します。「`™` を `™` で書きたいけど名前あったっけ?」「`♥` の数値表記は?」を瞬時に解決する用途。
- unicode-inspect との違いは?
- unicode-inspect は **任意の Unicode コードポイント** の詳細 (カテゴリ、スクリプト、UTF-8 バイト列、HTML 数値参照) を表示。本ツールは **HTML エンティティ表記** に特化していて、HTML5 標準の名前付きエンティティ (2125 個) すべてを内蔵 → 名前付き表記の有無を即判定できます。`U+2665 (♥)` に対し unicode-inspect は U+2665 詳細を、本ツールは `♥` (=名前付き) と `♥` (=10進) と `♥` (=16進) の 3 つの HTML 表記を返します。
- 対応する名前付きエンティティはどれくらい?
- WHATWG HTML5 仕様で定義されている **2125 個すべて** を内蔵しています (`&` `<` などの基本 5 個から `∳` のような数学記号まで)。同じ文字に複数の名前付き表記がある場合 (例: `<` と `<`) も両方表示。
- 何を入れるとどう変換される?
- (1) **名前付き** `é` → 文字 `é`、10進 `é`、16進 `é` を全部表示。(2) **数値** `é` → 文字 `é`、名前付き `é`、16進 `é` を表示。(3) **素の文字** `é` → 名前付き / 10進 / 16進 を表示。(4) どれも入力できる混在 OK。
- ASCII のみの文字も表示される?
- デフォルトでは表示されません (`a` `1` `space` は HTML エンティティの議論対象外)。ただし `&` `<` `>` `"` `'` のように **HTML 構造として意味を持つ ASCII** は名前付き表記がある (`&` 等) ので表示します。サロゲートペア絵文字や結合文字も検出。
- 10進と16進、どっちを使うべき?
- HTML5 仕様上はどちらも有効。**16 進** は U+ コードポイントとの対応が直感的 (例: U+2665 → `♥`)。**10 進** はカジュアル系のテキストで使われる傾向。**名前付き** は人間に最も読みやすいが、対応してない文字も多い。プロダクション用は数値 (16 進) が安全、人間が編集するソースは名前付きが好まれます。
- データはサーバーに送信されますか?
- いいえ。エンティティ辞書はクライアントに bundle されていて、外部 API は使いません。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール

HTML エンティティ変換 — &/</> を安全に
HTML の特殊文字 (< > & " ') を実体参照 (&lt; など) に encode したり、&amp; → & のように decode したりします。Mode 切替で双方向、すべて非 ASCII 文字を 10 進数値参照に変換するオプション付き。ブログのコードサンプル貼り付け、XSS 対策のエスケープ確認、メール本文の HTML 化準備などに使えます。
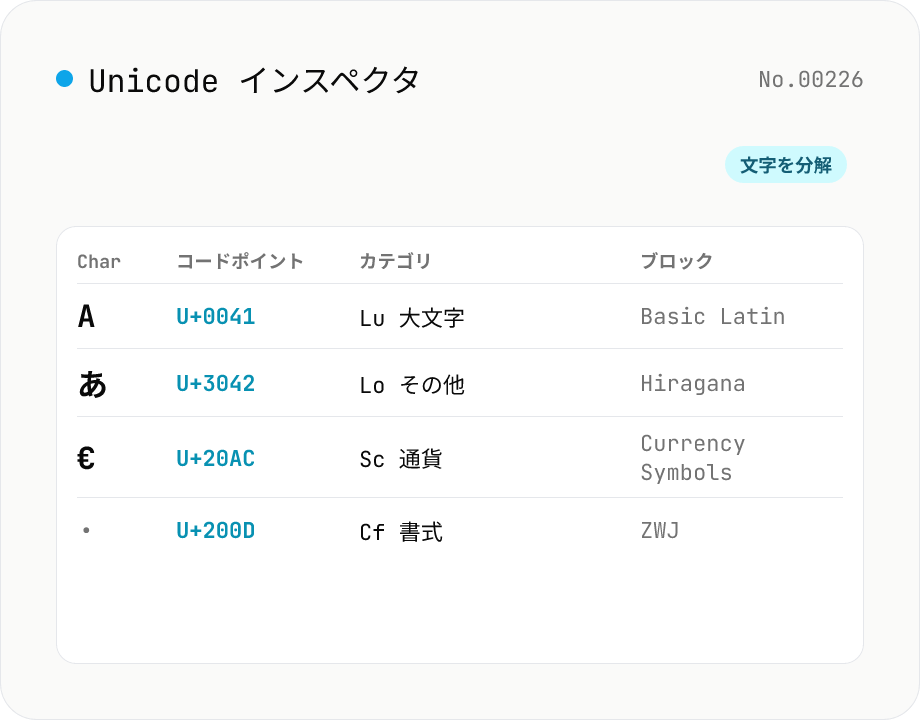
Unicode 文字インスペクタ
テキストを 1 文字ずつ分解し、コードポイント (U+XXXX)・10進数・一般カテゴリ (大文字 / 数字 / 記号など)・スクリプト (ラテン / 漢 / ひらがな等)・Unicode ブロック・UTF-8 / UTF-16 のバイト列・HTML 数値文字参照を表示します。サロゲートペア (絵文字) や結合文字、ゼロ幅接合子 (ZWJ)・制御文字・不可視文字も正しく検出してバッジ表示するので、文字化けや「見えない文字」のデバッグに便利。すべてブラウザ内で処理され、入力はサーバーに送信されません。
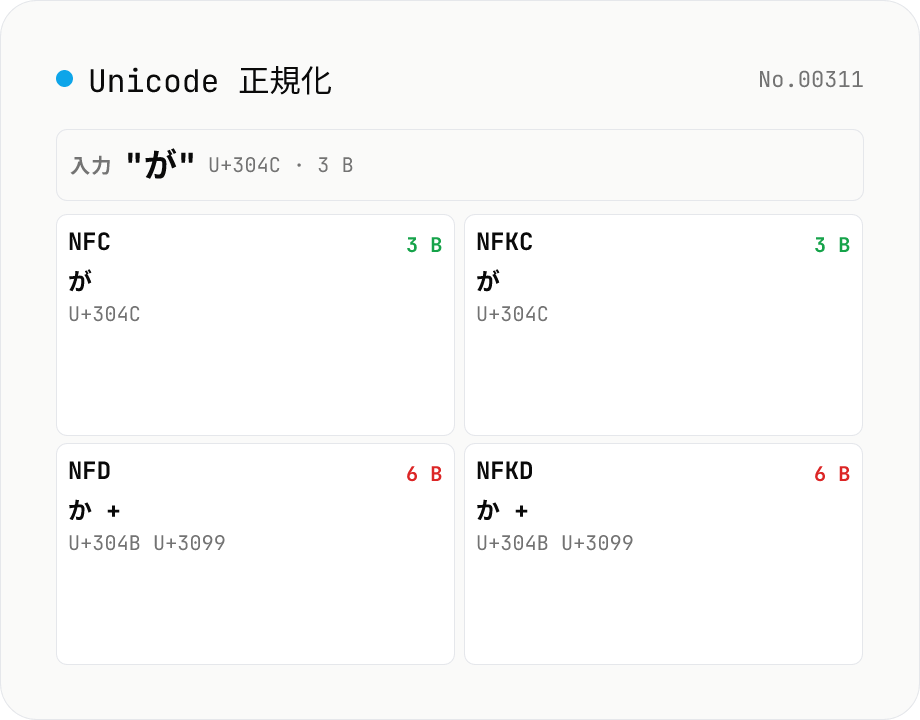
Unicode 正規化 — NFC / NFD / NFKC / NFKD を同時適用してコードポイント差分を可視化
入力テキストに対して Unicode の 4 つの正規化形式 (NFC / NFD / NFKC / NFKD) を **同時に** 適用し、結果文字列・コードポイント列 (U+XXXX)・UTF-8 バイト数を並列表示します。たとえば `が` (U+304C, NFC) は NFD に正規化すると `か + ゙` (U+304B + U+3099) の 2 コードポイントに分解され、UTF-8 で 3 → 6 バイトに増えます。`①` (NFC) は NFKC で `1` に正規化される、`㍻` (1 文字 NFC) は NFKC で `平成` (2 文字) に展開される、`㈱` は NFKC で `(株)` に変わる、といった視覚的に同じだが Unicode 表現が異なるテキストを **データベースの主キー突合** や **ファイル名比較** で扱うときの典型的な落とし穴をデバッグできます。ファイル名比較で macOS は NFD、Windows / Linux は NFC を使う、といった差異の確認にも。すべてブラウザ内で完結 (`String.prototype.normalize`)、サーバー送信なし。

HTML サニタイズ — XSS 防御 (script / on* / javascript:)
DOMPurify でユーザー投稿 HTML から XSS 攻撃ベクター (script 要素・on* イベントハンドラ・javascript: URL・data: URL の不正利用・iframe など) を取り除きます。厳格 / 標準 / 許容の 3 モードでプロファイルを切替可能。CMS や掲示板に渡す前のサニタイズ、Markdown→HTML 変換結果の安全化、ブログ移行時のレガシー HTML 清掃などに。すべてブラウザ内で完結し、HTML は外部に送信されません。