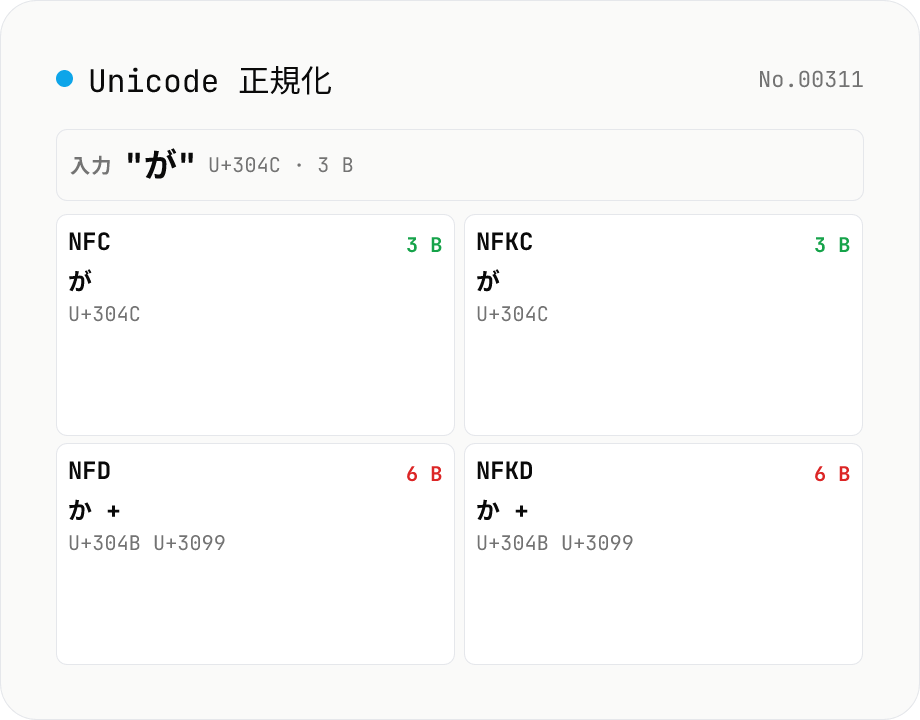
Unicode 正規化 — NFC / NFD / NFKC / NFKD を同時適用してコードポイント差分を可視化
入力テキストに対して Unicode の 4 つの正規化形式 (NFC / NFD / NFKC / NFKD) を **同時に** 適用し、結果文字列・コードポイント列 (U+XXXX)・UTF-8 バイト数を並列表示します。たとえば `が` (U+304C, NFC) は NFD に正規化すると `か + ゙` (U+304B + U+3099) の 2 コードポイントに分解され、UTF-8 で 3 → 6 バイトに増えます。`①` (NFC) は NFKC で `1` に正規化される、`㍻` (1 文字 NFC) は NFKC で `平成` (2 文字) に展開される、`㈱` は NFKC で `(株)` に変わる、といった視覚的に同じだが Unicode 表現が異なるテキストを **データベースの主キー突合** や **ファイル名比較** で扱うときの典型的な落とし穴をデバッグできます。ファイル名比較で macOS は NFD、Windows / Linux は NFC を使う、といった差異の確認にも。すべてブラウザ内で完結 (`String.prototype.normalize`)、サーバー送信なし。
使い方
入力欄にテキストを貼り付けるか、サンプルボタンを押す。 4 つの正規化結果 (NFC / NFD / NFKC / NFKD) が同時に表示され、各カードでコードポイント列 (U+XXXX)・コード単位数 (`string.length`)・UTF-8 バイト数が確認できます。 原文と同じ結果には `原文と同一` バッジが付き、差分が出ているフォームが一目で分かります。 各カードの「コピー」で正規化済みテキストをクリップボードへ。
詳細解説
Unicode 正規化が必要になるデータの機密性
Unicode 正規化の問題が現れるのは、複数のシステム・プラットフォームにまたがってデータが流れる場面です。macOS が NFD でファイル名を保存するため、Git リポジトリの日本語ファイル名が Linux/Windows で文字化けする問題。データベースへの保存前に NFC に統一しないと、同じ文字列が「等しくない」と判定される検索の誤動作。Web API がアクセント文字の異なる正規化形式を混在させてクライアント側で比較が失敗するケース。これらの場面で入力するテキストは、ファイル名・顧客名・製品名・ユーザー入力値などの実業務データです。
文字種の正規化を確認するだけのツールであっても、入力するテキストが機密性を持つ場合はオンラインツールへの送信に注意が必要です。ユーザー認証に使う文字列・顧客のメールアドレス・個人の氏名は、正規化確認の目的でも外部送信を避けるべきです。
正規化の不一致がもたらすシステム上の問題と調査の複雑性
NFC と NFD の違いは人間の目では見えません。が (NFC: U+304C, 1 コードポイント) と か゛ (NFD: U+304B + U+3099, 2 コードポイント) は同じ字に見えますが、文字列比較では異なる値として扱われます。この種のバグは単純なログ調査では発見しにくく、問題のある文字列を直接解析しないと原因が特定できません。解析対象の文字列が本番データの一部である場合、それをオンラインツールに送ることになります。
ブラウザ内完結の正規化ツールであれば、本番データの文字列を直接貼り付けて4フォームの違いを即座に確認できます。
String.prototype.normalize がブラウザ組み込みで完結する
このツールは ECMAScript 標準の String.prototype.normalize() を使います。str.normalize('NFC') / str.normalize('NFD') / str.normalize('NFKC') / str.normalize('NFKD') の 4 フォームをすべて並行して計算し、各結果のコードポイント列を [...str] で取得、UTF-8 バイト数は TextEncoder でエンコードして測定します。Unicode の正規化アルゴリズムはブラウザの JavaScript エンジンに組み込まれており、外部のデータファイルも外部 API も必要ありません。
すべての計算がページのメモリ内で完結します。macOS のファイル名・データベースの文字列フィールド・API レスポンスの文字列を安全に正規化確認できます。
macOS ファイル名の NFD 問題と Web 開発での NFC 統一
macOS の HFS+ / APFS はファイル名を NFD で保存するため、日本語ファイル名を含む Git リポジトリを macOS で作成して Linux で clone すると「存在しないファイル」になる問題が起きます。git config core.precomposeunicode true はこの問題の workaround ですが、根本的な解決には保存前に NFC に統一する処理が必要です。本ツールで問題のあるファイル名を貼り付けて NFC / NFD の違いを確認することが、原因特定の最初のステップになります。Web API に保存する文字列は、入力段階で normalize('NFC') を通す習慣が WHATWG 仕様でも推奨されています。
4 つの正規化形式が何をするか — Canonical vs Compatibility 分解
Unicode 正規化は Unicode Standard Annex #15 (UAX #15) で定義され、4 形式が存在します。NFD (Normalization Form Canonical Decomposition) は合成済み文字 (が U+304C など) を基底文字 + 結合文字 (か U+304B + ゛ U+3099) に 正規分解 し、UAX #15 が定める結合順序に並び替えます。NFC (Canonical Composition) は NFD で分解した上で、可能なら合成形式に 再合成 します。
NFKD / NFKC の “K” は Compatibility (互換) を意味します。これは「視覚的に同じ意味を持つが文字としては別」の文字を統一する強い変換です。① (U+2460, NFC) は NFKC で 1 (U+0031) に置換され、fi (U+FB01, ラテンリガチャ) は fi (U+0066 U+0069) に展開され、㍻ (U+337B, NFC) は 平成 (U+5E73 U+6210) に展開され、全角英数 A (U+FF21) は A (U+0041) になります。これは情報量を保つ NFC/NFD と違って意味的な情報も変える (“compatibility” decomposition map に基づく) ため、検索インデックスや認証文字列の照合で使うときは「① と 1 を同一と扱ってよいか」を要件として明示する必要があります。
検索インデックス・パスワード比較・国際化ドメイン名での適用
実務で正規化形式を選ぶ場面は大きく分けて 3 つあります。検索インデックス (Elasticsearch / OpenSearch / Solr) では、トークン化の前段で NFKC を適用するのが定番です。ICU の Normalizer2 や Lucene の ICUNormalizer2Filter がこの役割を担い、① と 1、fi と fi、全角英数と半角英数を同一トークンとして扱えるため、ユーザーの入力ゆれに対するヒット率が上がります。一方で、本来別単語のものが結合してしまうリスクもあるため、検索対象ドメインによっては NFC + lowercase の組み合わせに留める設計もあります。
パスワード比較は UTS #46 と RFC 8265 (PRECIS) が指定する正規化を使います。PRECIS の OpaqueString プロファイルは NFC 正規化と特定の制御文字禁止を組み合わせ、Apple のキーチェーンや一部の SSO 実装で採用されています。国際化ドメイン名 (IDN) は別系統で、UTS #46 が NFC + Punycode (RFC 3492) 変換を定義します。本ツールの 4 形式同時表示は、これらの仕様が要求する正規化形式と実装が一致しているかを目視で確認する用途で特に便利です。が の NFC バイト数 (3 バイト) と NFD バイト数 (6 バイト) の差は、DB の VARCHAR(N) の “N” が文字数かバイト数かで挙動が変わる落とし穴の発見にも使えます。各コードポイントごとのカテゴリ・スクリプト・UTF-8 バイト列まで掘り下げたい場合は unicode-inspect、半角カナ ↔ 全角カナや全角英数 ↔ 半角英数の併用が必要なシステムでは zenkaku-hankaku が同じくブラウザ内で動きます。
よくある質問
- NFC / NFD / NFKC / NFKD の違いは?
- C / D は Canonical (標準正規化)、K は Compatibility (互換正規化)。C は分解した後に合成、D は分解のみ。例: `が` (NFC = U+304C, 1 文字) → NFD = `か + ゙` (U+304B + U+3099, 2 文字) → NFKC は NFC と同じ → NFKD は NFD と同じ。`①` (NFC = U+2460) → NFKC は `1` (U+0031) に変換、NFC では変わらない。
- どの形式を使うべき?
- Web / API / DB に保存するなら NFC が無難 (Web プラットフォームの推奨)。検索インデックスや「見た目が同じなら同一視」したい場合は NFKC。フォントレンダリングや結合文字を逐次描画したい場合は NFD。NFKD はインデックス用途以外ではほぼ使われません。
- macOS のファイル名が NFD という話は?
- macOS の HFS+ は NFD でファイル名を保存します (APFS も互換性のため NFD 中心)。`が` (NFC) で保存したつもりが `か + ゙` (NFD) になり、Windows / Linux 側で「存在しないファイル」になる事故が起こります。Git で `core.precomposeunicode = true` を立てる必要があるのもこれが理由。
- JavaScript / TypeScript ではどう正規化する?
- `'が'.normalize('NFC')` のように `String.prototype.normalize` を呼びます。本ツールもこれを使っています。引数を省略すると NFC。
- サロゲートペア (絵文字) はどうなる?
- UTF-16 のサロゲートペアは `string.length` で 2 にカウントされますが、コードポイントは 1 (`[...str]` で 1 要素)。本ツールは「コード単位数 (length)」と「コードポイント列」の両方を出します。絵文字の正規化はほとんどの場合 no-op ですが、結合絵文字 (ZWJ 連結) は NFC/NFD で変化することがあります。
- データはサーバーに送信されますか?
- いいえ。`String.prototype.normalize` はブラウザ組み込みなので、外部送信は一切ありません。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール
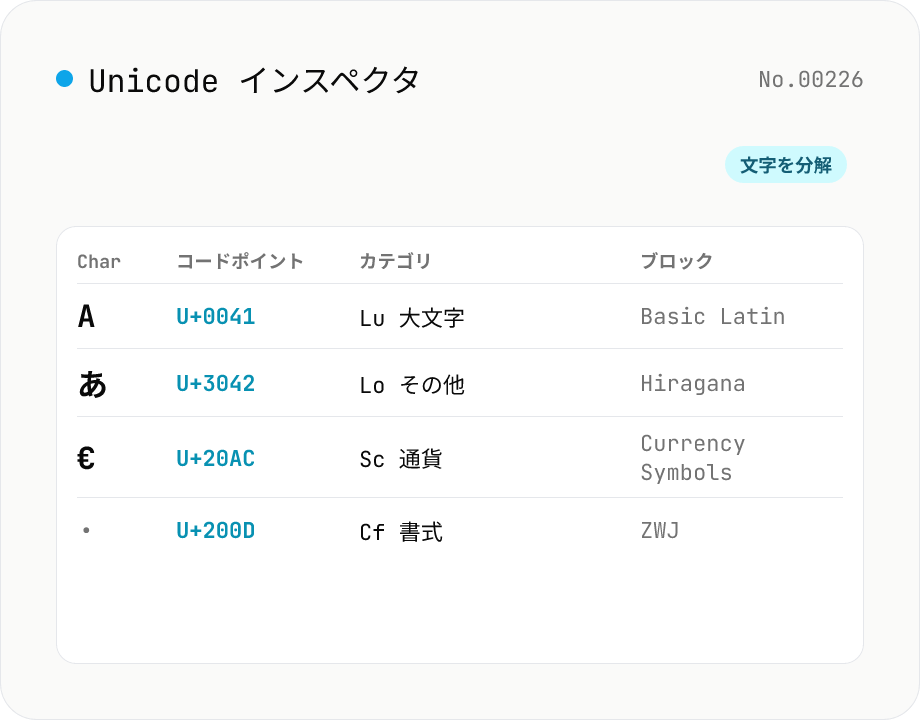
Unicode 文字インスペクタ
テキストを 1 文字ずつ分解し、コードポイント (U+XXXX)・10進数・一般カテゴリ (大文字 / 数字 / 記号など)・スクリプト (ラテン / 漢 / ひらがな等)・Unicode ブロック・UTF-8 / UTF-16 のバイト列・HTML 数値文字参照を表示します。サロゲートペア (絵文字) や結合文字、ゼロ幅接合子 (ZWJ)・制御文字・不可視文字も正しく検出してバッジ表示するので、文字化けや「見えない文字」のデバッグに便利。すべてブラウザ内で処理され、入力はサーバーに送信されません。
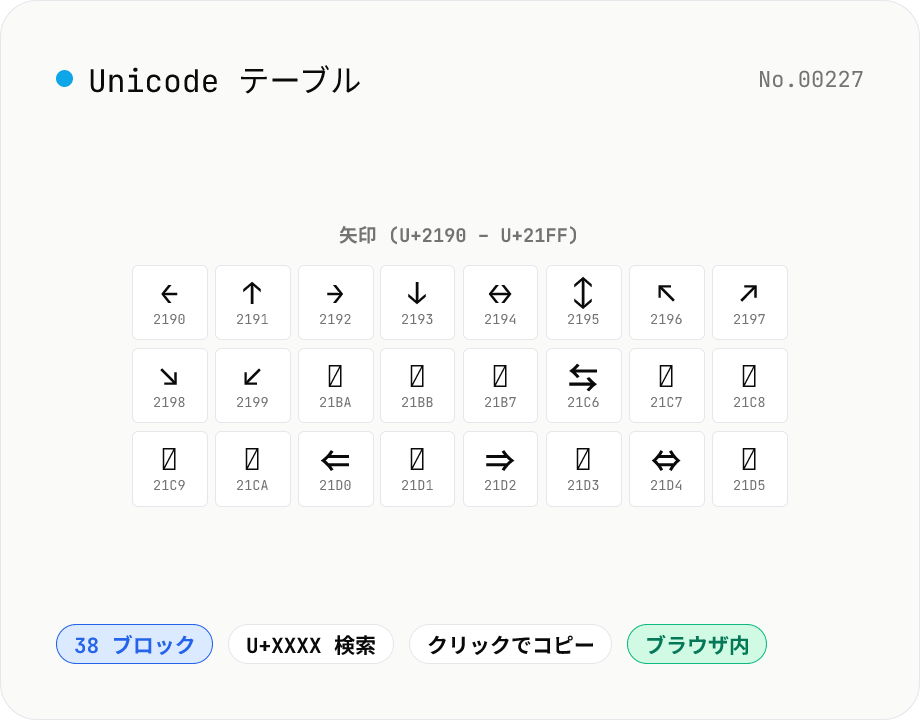
Unicode テーブル — 主要 38 ブロックの文字を一覧
Unicode の主要ブロック (基本ラテン / ひらがな / カタカナ / ギリシャ / キリル / 矢印 / 罫線素片 / 絵文字 など 38 種) を選んでグリッド表示します。各セルにグリフとコードポイント (U+XXXX) を併記、クリックで文字 または HEX をコピー。クエリでブロック横断検索 (例: `arrow`、`矢印`、`U+2190`)、CJK / ハングルなど巨大ブロックは先頭 256 文字を表示。デザインや開発で「ちょうど良い記号」を探すときに。データはすべて組み込みでブラウザ内処理。
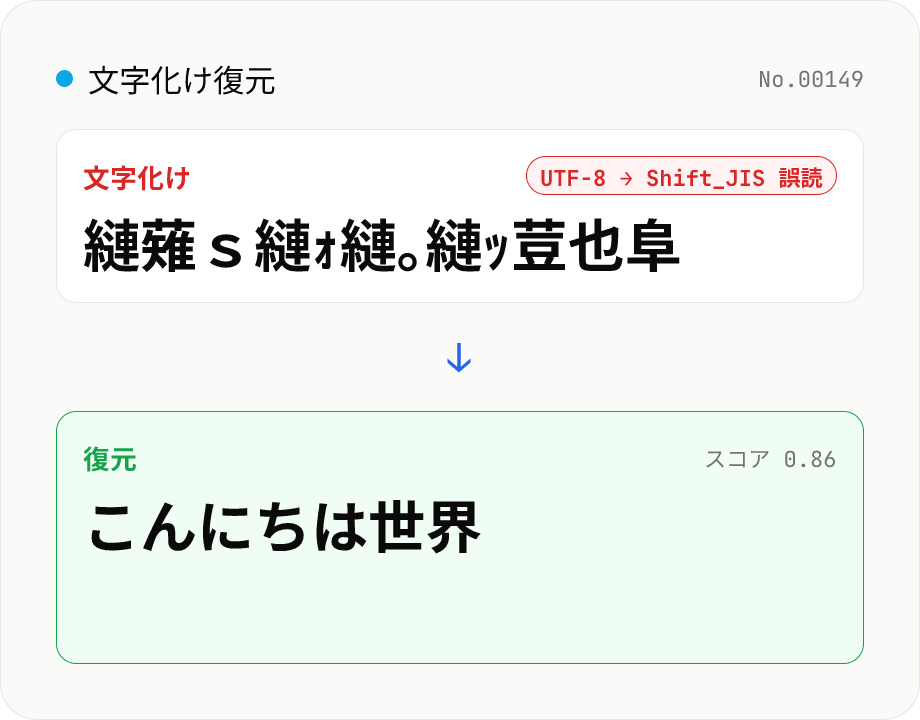
文字化け 解読・変換ツール — Shift_JIS / EUC-JP / UTF-8 自動判定
文字化けしたテキストを貼り付けるだけで日本語に戻す無料オンラインツール。Shift_JIS / EUC-JP / UTF-8 / ISO-2022-JP / Latin-1 の誤読パターンを総当たりで試し、日本語らしさスコアが高い順に復元候補を並べます。メール・CSV・ログの文字化け直しに。すべてブラウザ内で完結し、入力テキストは送信されません。

全角 ⇄ 半角 変換 — 英数字・カナ・記号を一括変換
全角 ASCII (英数字・記号・スペース) と半角 ASCII をモード切替で双方向に変換します。U+FF01〜U+FF5E ⇄ U+0021〜U+007E のシフト、全角スペース U+3000 ⇄ 半角スペース U+0020 にも対応。カタカナ・ひらがな・漢字はそのまま保持。すべてブラウザ内で処理。