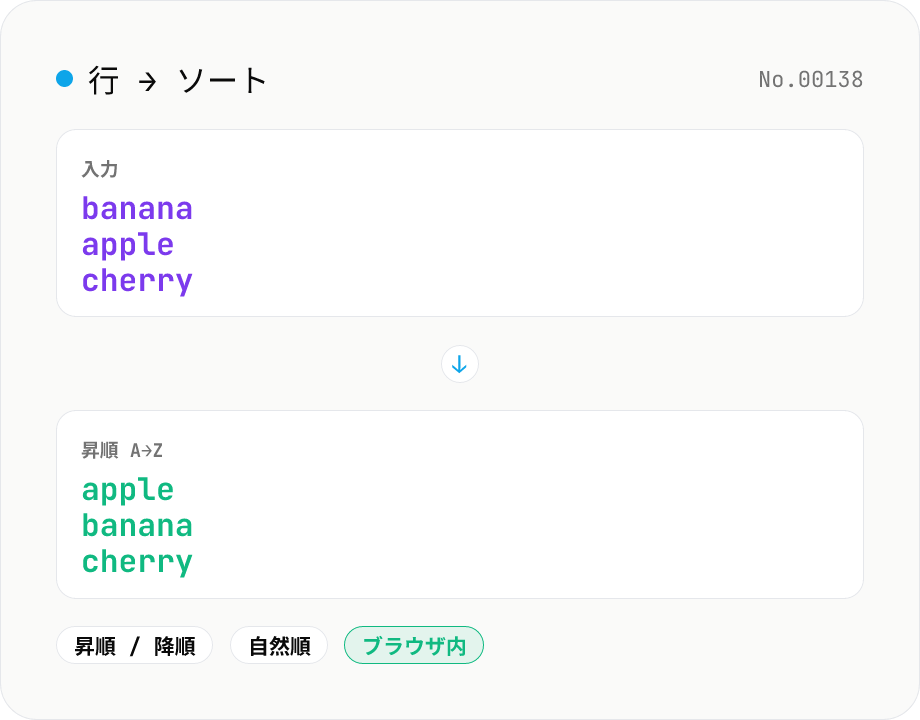
行ソート — 昇順 / 降順 / 数値 / ロケール
テキストを行 (\n) で分割し、Unicode のロケールに従って昇順 (A→Z) または降順 (Z→A) に並び替えます。数値混じり (file1, file2, file10) も自然順に。空行や末尾の改行はそのまま保持。日本語混在テキストにも対応。すべてブラウザ内で処理。
使い方
1 行 1 要素の形でテキストを入力欄に貼り付け、並び順 (昇順 / 降順) を選び、「ソート実行」を押すだけ。改行コード (\n / \r\n) で分割し、`Intl.Collator` を使った locale-aware な比較で並び替えます。数値混じり (例: file1, file2, file10) も numeric オプションで自然順に並びます。末尾の改行はそのまま保持。結果はワンクリックでコピー、または .txt としてダウンロード可能。
よくある質問
- テキストはサーバーに送信されますか?
- いいえ。ソートはブラウザ内で完結し、入力も結果も端末外には出ません。
- 大文字と小文字は区別されますか?
- 区別されません。`Intl.Collator({ sensitivity: 'base' })` を使い、'Apple' と 'apple' は同じものとして並び替えられます (ただし重複除去はしません)。
- 数字混じりの行 (file1, file2, file10) はどう並びますか?
- numeric: true オプションで自然順 (file1, file2, file10) に並びます。文字列ソートの file1, file10, file2 とは異なります。降順を選んだ場合は file10, file2, file1 になります。
- 空行や末尾の改行はどうなりますか?
- 空行は値が空の行として並び替え結果に含まれます (昇順なら通常先頭、降順なら通常末尾)。元の末尾改行 (trailing newline) はそのまま保持されます。
- 降順 (Z→A) はどう動きますか?
- 昇順と同じ collator で比較し、結果を逆順にします。安定ソートではないので同値要素の入力順は保証しませんが、明確に異なる値同士の並びは昇順を逆向きにした結果になります。
類似のツール
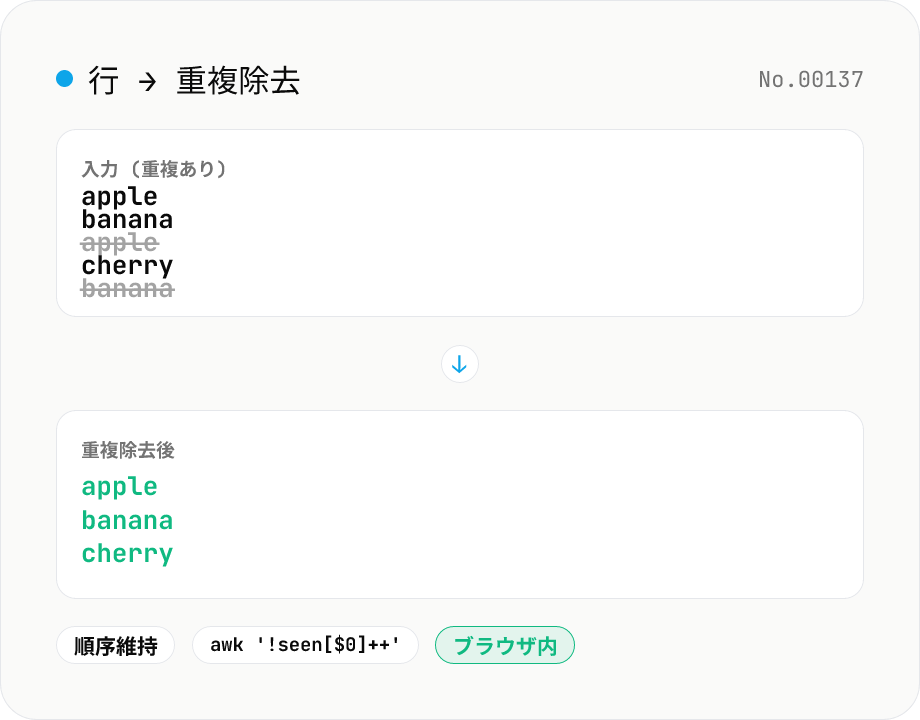
行重複削除 — 全部一意化 / 重複だけ抽出
テキストを行 (\n) で分割し、重複する行を除去します。初出の行だけを保持し、元の順序を維持。連続した重複だけでなく離れた位置の重複も対象 (Unix `awk '!seen[$0]++'` 相当)。すべてブラウザ内で処理。

文字数カウント — 文字 / バイト / 行 / 単語
テキストの文字数・単語数・行数・段落数・UTF-8 バイト数をリアルタイムで集計。空白・改行を含めるか除くかを切り替え可能で、Twitter・原稿用紙 (400 字)・LINE などの文字数上限の進捗バーも同時表示。すべてブラウザ内で動くので、原稿や下書きを安全にカウントできます。

CSV / テキスト文字コード変換 — Shift_JIS ⇄ UTF-8 / BOM / 改行
Shift_JIS (CP932) と UTF-8、UTF-16LE、EUC-JP の間で CSV / テキストファイルを変換します。Excel が出す Shift_JIS の文字化け、UTF-8 のテキストを古いシステムに渡せない問題、Excel が BOM 無し UTF-8 を文字化けさせる問題などに対応。BOM 付与/除去、改行コード (CRLF / LF / CR) の差し替え、入力エンコーディング自動判定をサポート。複数ファイルを一括変換して ZIP で受け取れます。アップロードしたファイルは外部に送信されず、すべての処理はブラウザ内で完結します。
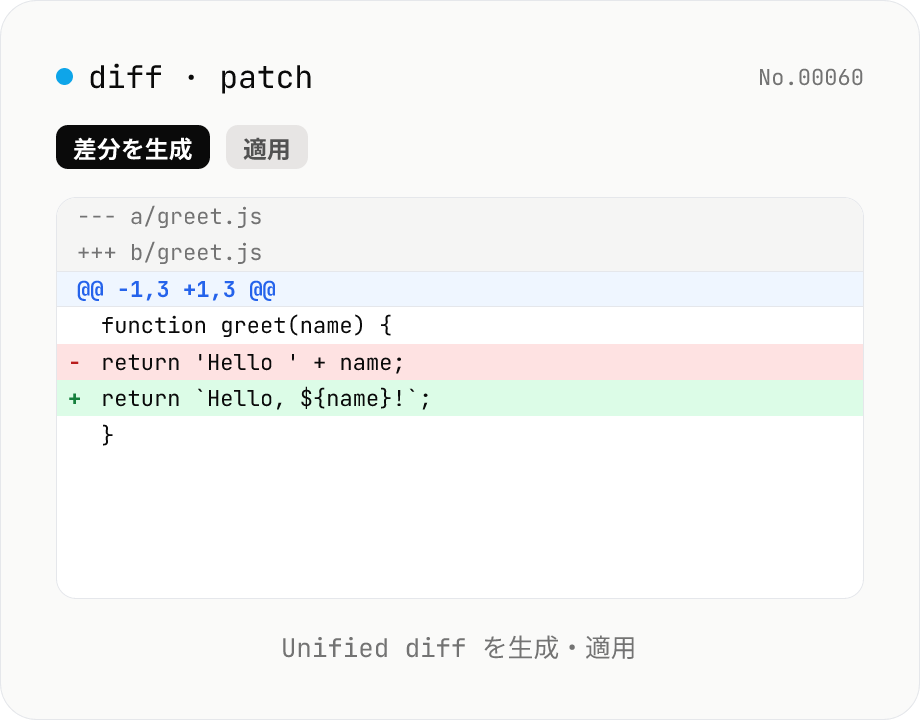
diff / patch — Unified diff の生成・適用
2 つのテキストから Unified diff (.patch / .diff) を生成し、Unified diff を元テキストに適用 (apply) できる。Git や GNU patch と同形式 (--- / +++ / @@ ハンク)、コンテキスト行数とファイル名を指定可。すべてブラウザ内で処理。