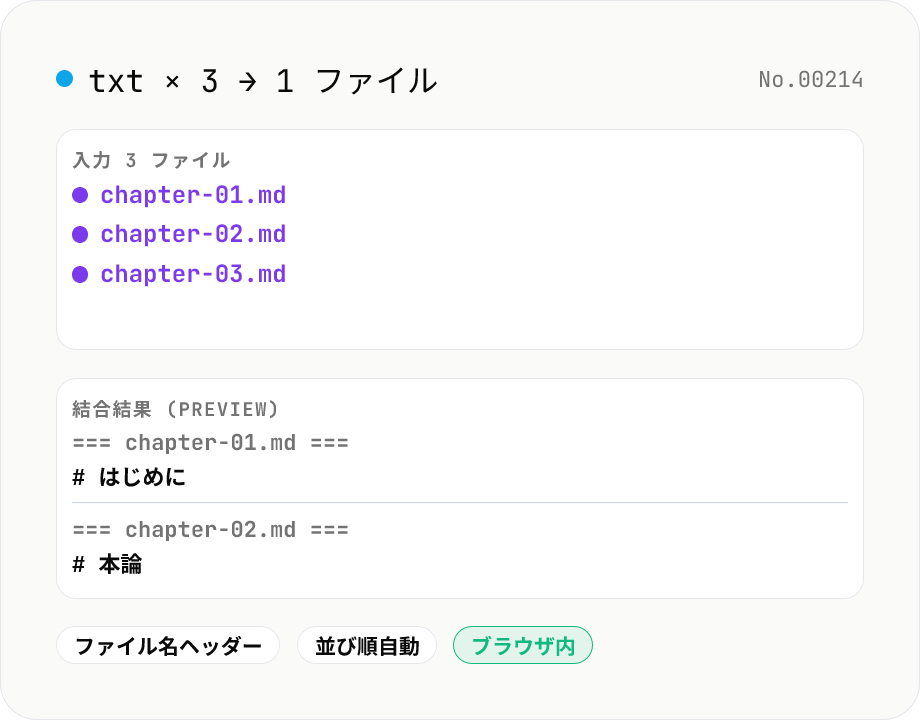
テキストファイル結合 — 複数 .txt / .md / .csv を 1 つに
複数のテキストファイル (.txt / .md / .csv / .tsv / .json / .log / .srt / .vtt 等) を 1 つのファイルに結合します。各ファイルの先頭にファイル名ヘッダーを入れる / ファイル名昇順に自動ソートする / ドラッグで順番を入れ替える / 区切り線を入れる オプションに対応。文字起こし結果のまとめ、ログの統合、議事録の連結に最適。すべてブラウザ内で処理。
使い方
結合したいテキストファイル (.txt / .md / .csv / .tsv / .json / .log / .srt / .vtt など) を 2 つ以上ドロップ。リストでドラッグ / 上下ボタンで順番を調整するか、「並び順」セレクタで「ファイル名昇順」を選んで自動ソートさせます。「ファイル名ヘッダーを入れる」「区切り (改行 / 空行 / 区切り線)」「末尾改行」を必要に応じて切り替えて「結合」ボタン。出力ファイル名は自由に変更できます。文字起こし結果の統合、議事録の連結、ログのまとめ、章ごとの原稿合成などに。すべてブラウザ内で動作し、ファイルはサーバーに送信されません。
よくある質問
- 対応しているファイル形式は?
- 拡張子 .txt / .text / .md / .markdown / .csv / .tsv / .json / .json5 / .yaml / .yml / .ini / .cfg / .conf / .log / .html / .htm / .xml / .svg / .srt / .vtt と、MIME タイプ text/* を持つファイルを受け付けます。バイナリ (画像 / 動画 / PDF) はドロップしてもスキップされます。
- 文字コードは何で読み込まれますか?
- ブラウザの File.text() で UTF-8 として読み込みます。Shift_JIS / EUC-JP の CSV を扱う場合は事前に「csv-encoding-convert」ツールで UTF-8 化してから結合してください。
- ファイル名ヘッダーの形式は?
- `=== ファイル名 ===` 形式の 1 行を各ファイルの先頭に挿入します。Markdown 風の `# ファイル名` ではなく区切り線兼ヘッダーとして読みやすい形式を選択しました。後で sed や置換でカスタムヘッダー形式に変えるのも容易です。
- 「並び順」を変えるとドラッグした順は失われますか?
- 「ファイル名昇順 / 降順」を選んだ瞬間、表示順が自動ソートで上書きされます。「手動」に戻すと最初にドラッグした順序が復元されます (リスト内のドラッグ操作は手動の順序にも反映されます)。
- 結合後のファイル名・拡張子は?
- デフォルトは `merged.txt`。出力ファイル名欄に入力した文字列に `.txt` を補完してダウンロードします。拡張子を `.md` / `.csv` / `.log` などにしたい場合は、入力欄に明示的に書き換えてください (例: `transcripts.md`)。
- 区切りはどれを選ぶべき?
- Markdown を結合するなら「空行 1 行 (改行 2 つ)」が標準。CSV / TSV を結合するなら「改行 1 つ」(各ファイルがヘッダー行を持つ場合は重複ヘッダーに注意)。一般文書なら「区切り線 (---)」が視認性が高くおすすめです。
- ZIP で複数の merged を作れますか?
- 現状は 1 度に 1 つの結合結果のみ。複数グループに分けて結合したい場合は、ファイルセットを差し替えてもう一度実行してください。
類似のツール
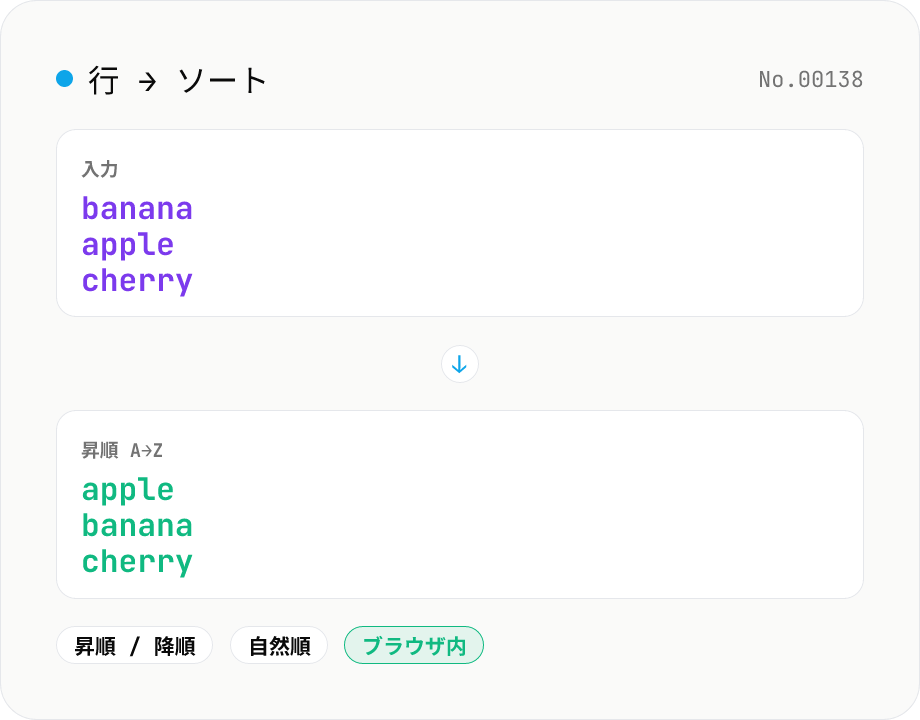
行ソート — 昇順 / 降順 / 数値 / ロケール
テキストを行 (\n) で分割し、Unicode のロケールに従って昇順 (A→Z) または降順 (Z→A) に並び替えます。数値混じり (file1, file2, file10) も自然順に。空行や末尾の改行はそのまま保持。日本語混在テキストにも対応。すべてブラウザ内で処理。
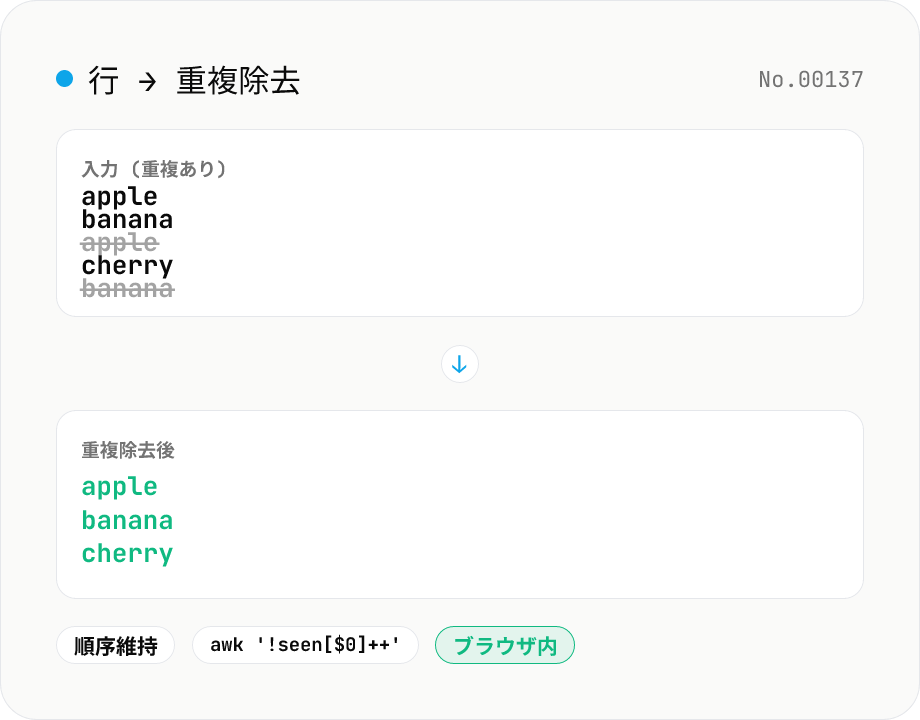
行重複削除 — 全部一意化 / 重複だけ抽出
テキストを行 (\n) で分割し、重複する行を除去します。初出の行だけを保持し、元の順序を維持。連続した重複だけでなく離れた位置の重複も対象 (Unix `awk '!seen[$0]++'` 相当)。すべてブラウザ内で処理。

音声文字起こし — Whisper で多言語対応
MP3 / WAV / M4A などの音声ファイルをアップロードして、ブラウザ内で動く Whisper で文字起こし。長尺ファイルは自動でチャンク分割します。音声・モデルともに外部送信なし。動作速度・対応モデルの大きさはお使いの端末スペック (CPU / GPU / メモリ) に依存します。

PDF テキスト抽出 — .txt 書き出し
PDF からプレーンテキストをブラウザ内だけで抽出します。pdfjs-dist の getTextContent でページごとに文字列を集め、1 ファイル = 1 つの .txt として書き出し。複数 PDF はまとめて ZIP でダウンロードできます。ページ区切りマーカーの有無は切り替え可能。