使い方
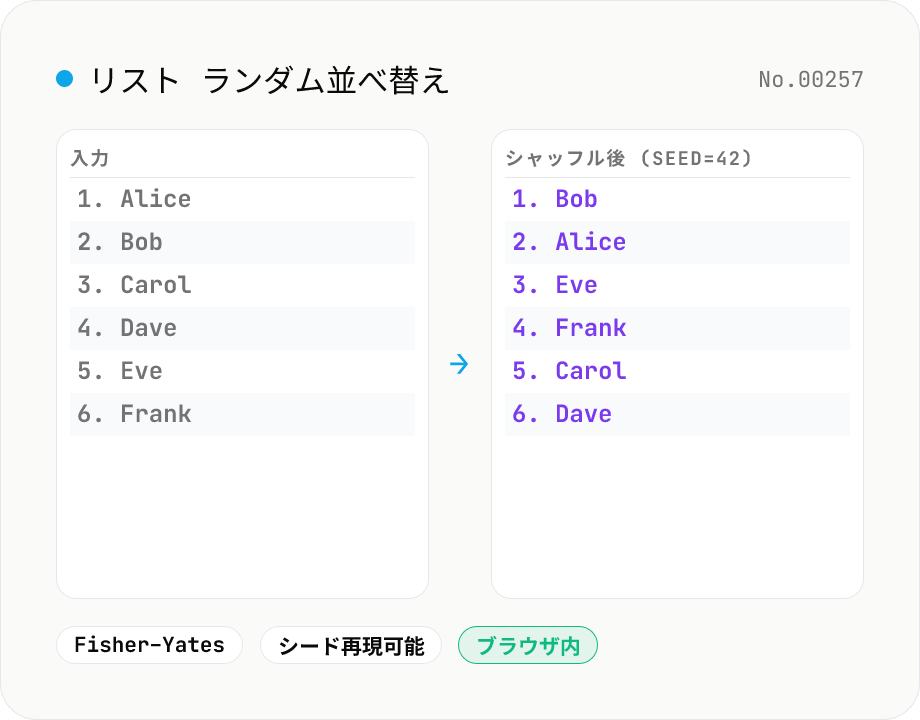
1 行 1 項目でリスト (名前・番号・選択肢など) を貼り付けて「シャッフル」を押すと、**Fisher–Yates アルゴリズム** でランダムに並べ替えます。**シード** を指定 (数値でも文字列でも OK) すれば、同じシード + 同じ入力で同じ結果を再現できます — 「あとでチーム分けをもう一度同じ結果で再現したい」「結果に第三者が疑義を持った時に検証できるようにしたい」に対応。**グループサイズ** に N (≥1) を入れると、結果を N 項目ごとに分割してチーム単位で表示します (例: 8 人で 2 → 4 チーム、3 → 3 チーム+1 余り)。**重複除去** を ON にすると同一行は最初の 1 個だけ残します。シードを空欄にすると毎回違うランダム結果が出ます。
詳細解説
シャッフル対象のリストが持つ情報の機微性
「リストをシャッフルする」という操作は単純に見えますが、シャッフル対象のリスト自体が機密情報を含むことがあります。社員名のリストからチーム分けする、顧客 ID のリストから抽選する、プロジェクト候補のリストから優先順位を決める — これらのリストはそれぞれ組織構造・顧客データ・内部戦略に紐づく情報です。
オンラインのシャッフルツールに貼り付けると、そのリストがサーバー側で受信されます。サービス側の実装がクライアントサイドのみで完結しているかどうかは、ユーザーが外部から確認する方法がありません。広告モデルのサービスでは行動データの収集が行われるケースがあり、入力内容がその対象になる可能性があります。
アップロード型シャッフルサービスのリスク
シャッフルの操作自体はアルゴリズムとしては単純で、ブラウザ内の JavaScript で完全に実現できます。にもかかわらず「シャッフル ランダム オンライン」で検索すると上位に出るサービスの多くはサーバーサイドの API を経由します。理由の一つは広告収入のためにページビューを稼ぐ設計があるからで、入力フォームにリストを貼り付けてサブミットする操作がサーバーへのリクエストになります。
「社員全員の名前でシャッフル抽選を行い、その結果が第三者のサーバーログに残る」という状況は、個人情報保護の観点から避けるべきです。特にシードを指定して再現可能な抽選を行う場合、シードとリストの組み合わせが外部に漏れると結果の操作有無を検証しにくくなります。
Fisher–Yates と Mulberry32 PRNG がブラウザ内で完結する
このツールは Fisher–Yates アルゴリズム (Durstenfeld 最適化版) をブラウザ内の JavaScript で実装しています。シードを指定した場合は Mulberry32 (32-bit シードベース PRNG、周期 2^32) を使い、シードが同じなら入力が同じであれば常に同じ結果を再現します。シードを空欄にした場合は crypto.getRandomValues をベースにした安全な乱数源を使用します。
入力リスト・シード・シャッフル結果のいずれもブラウザのページメモリにのみ存在し、ネットワーク通信は発生しません。社員リスト・顧客 ID・プロジェクト名などの機密情報を含むリストでも安全にシャッフルできます。
透明性のある抽選・チーム分けのための使い方
シードを公開しておくと、抽選後に「同じシードと同じリストで再実行すれば結果が一致する」ことを誰でも検証できます。くじ引きの公正性を後から示したい場面、チーム分けに不満が出た時に「同じシードで再現できる」と示したい場面で有効です。シード値をあらかじめ参加者全員に公開しておく、または公開情報 (その日の日付など) をシードにする設計にすると、より透明性が高まります。事前に重複行を除いておきたい場合は line-dedupe を、シャッフル後にアルファベット順で並べ替えたいときは line-sort を続けて使えます。
Fisher–Yates の偏りと Mulberry32 PRNG の特性
Fisher–Yates シャッフル (Knuth shuffle) は配列末尾から先頭に向かって走査し、各位置 i で [0, i] の整数を一様にサンプルして当該要素と入れ替える、O(n) 時間・O(1) 追加メモリのアルゴリズムです。重要なのは「[0, i] から一様にサンプルする」点で、ここを Math.floor(Math.random() * n) で近似すると n が 2 の冪でない場合に modulo bias (剰余偏り) が入り、特定の順列がわずかに多く出力されます。本ツールは Mulberry32 の場合は state / 2^32 を 32-bit 整数空間として扱い、crypto.getRandomValues の場合は rejection sampling (Uint32 を取り直す) で偏りを排除しています。
Mulberry32 は 32-bit のシードを入力に取り、state += 0x6D2B79F5; let t = state; t = Math.imul(t ^ (t >>> 15), t | 1); t ^= t + Math.imul(t ^ (t >>> 7), t | 61); という形の混合関数を回す軽量 PRNG です。周期は 2^32 ≈ 43 億で、暗号用途には使えませんが PractRand などの統計テストはパスします。リスト長が数百〜数万程度の抽選には十分な品質ですが、リスト長 N が大きく N! が 2^32 を超える (N ≥ 13) と、Mulberry32 で出せる順列は理論上の全順列の一部分でしかなくなります。シードなし (crypto) を使えばこの制約はありません。
抽選の公正性、コミットメントスキーム、よくある落とし穴
公正な抽選の運用上のベストプラクティスは、(1) シードを抽選前にコミットする (シード値の SHA-256 ハッシュを先に公開し、抽選後に元のシードを開示)、(2) 候補リスト (入力) も抽選前に確定・公開する、(3) シード自体は予測不能な公開情報 (将来のブロックチェーンブロックハッシュ、抽選当日終値、Drand など) から導出する、の 3 点です。これにより主催者が「結果を見てからシードを選ぶ」攻撃 (grinding attack) を排除できます。逆にやってはいけないのは、シードを主催者が任意に選んで結果だけ公開する運用で、これだと参加者は再現不能なため検証できません。
落とし穴として、(a) リストに見えない trailing whitespace や全角空白があると重複除去オプションでも同一視されず別項目になる (本ツールは LF / CRLF を内部正規化しますが空白は保持)、(b) 「N 人ずつ」のチーム分けで余り人数の扱いがツールによって異なる (本ツールは最後に小さなチームを作る方式で、人を捨てません)、(c) 「シードを再利用するとリストが少し変わっても全く違う結果が出る」ことに注意 (Fisher–Yates は最初の要素位置から消費するため、入力末尾を 1 つ追加しただけでも前半の swap 列が違う数列を消費し、結果が変わる)、があります。決定論的に「ある人だけ常に最初」のような結果を作るには、シャッフル後に固定位置への配置を別ステップで行う必要があります。
よくある質問
- 入力データはサーバーに送信されますか?
- いいえ。すべてブラウザ内で完結します。乱数生成・並べ替え・グループ分割すべて JS のローカル処理です。
- Fisher–Yates アルゴリズムって何ですか?
- 1938 年に R. A. Fisher と F. Yates が提案、1964 年に R. Durstenfeld が実装を最適化した「公平なシャッフル」のための古典アルゴリズム。配列の末尾から先頭に向かって、`[0, i]` の範囲でランダムに 1 つ選んで `i` 番目と交換することを繰り返します。`O(n)` で計算でき、**全ての順列が等確率で出る** ことが理論的に保証されています (純朴な `sort(() => random())` だとブラウザの sort 実装次第で偏りが出るので非推奨)。
- 「シード」は何のためにありますか?
- **結果を再現可能にする** ためです。`Math.random()` は実行ごとに違う結果を返しますが、シード値を渡してそれをもとに乱数を生成すれば、シードが同じなら結果も同じになります。これは「先生がくじを引いた → 後で生徒に見せる時に同じ結果を再現したい」「不正がないことを後日検証したい」のような場面で重要。本ツールは Mulberry32 という 32-bit シードベース PRNG を使用 (周期 2^32、高速かつ十分な品質)。
- シードに文字列を入れるとどうなりますか?
- FNV-1a ハッシュで 32-bit 整数に変換してから PRNG に渡します。`"hello"` と `"world"` で違うハッシュ → 違うシャッフル結果。同じ文字列なら毎回同じハッシュ → 同じ結果。整数を直接入れる場合と挙動は同じ (内部で正規化)。
- グループサイズが項目数を割り切らない時は?
- 末尾に余りグループが作られます。例: 10 項目を 3 でグループ分け → 3 / 3 / 3 / 1 (4 グループ目に 1 人残る)。チーム分けで人数が割り切れない時は、最後の小グループを既存のいずれかに合流させるか、補欠 / リザーブ扱いにしてください。
- なぜ純朴な `sort(() => Math.random() - 0.5)` ではダメ?
- JavaScript の `sort` は比較関数が **一貫している** ことを前提としていて、毎回ランダム値を返すと結果の確率分布が偏ります (V8 の TimSort では特定順列が出やすい)。要素数が増えるほど偏りが顕著に。Fisher–Yates なら理論的に各順列が等確率になる (`1/n!`)。本ツールは Fisher–Yates を採用。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール
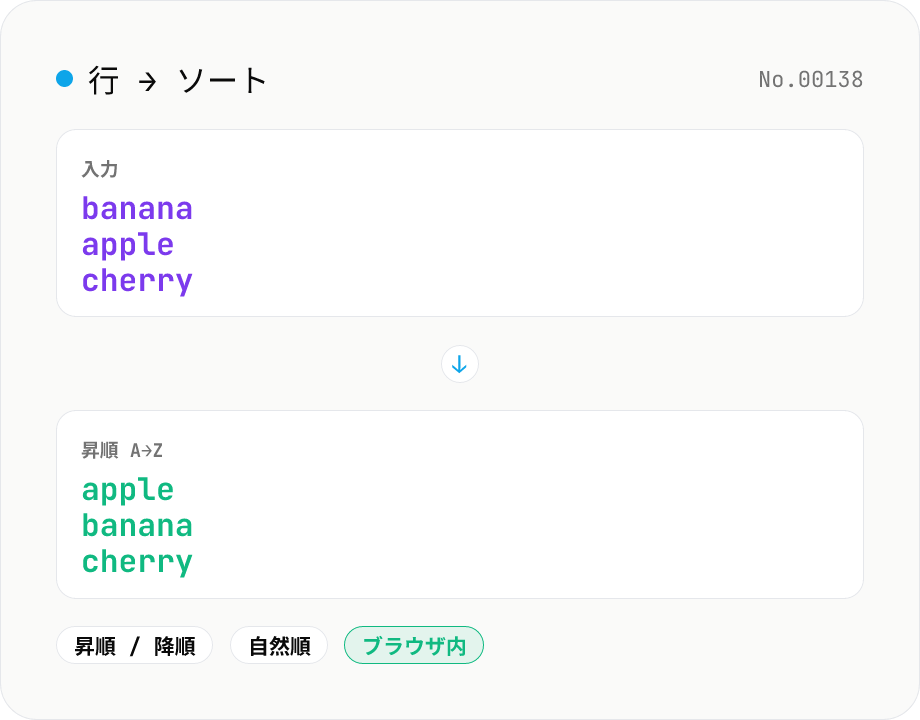
行ソート — 昇順 / 降順 / 数値 / ロケール
テキストを行 (\n) で分割し、Unicode のロケールに従って昇順 (A→Z) または降順 (Z→A) に並び替えます。数値混じり (file1, file2, file10) も自然順に。空行や末尾の改行はそのまま保持。日本語混在テキストにも対応。すべてブラウザ内で処理。
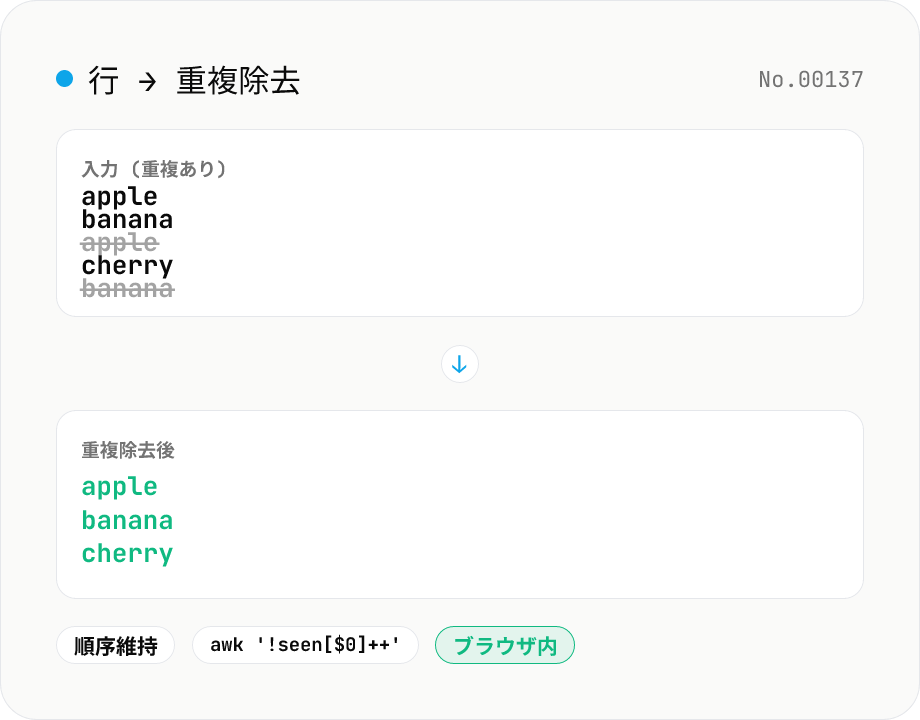
行重複削除 — 全部一意化 / 重複だけ抽出
テキストを行 (\n) で分割し、重複する行を除去します。初出の行だけを保持し、元の順序を維持。連続した重複だけでなく離れた位置の重複も対象 (Unix `awk '!seen[$0]++'` 相当)。すべてブラウザ内で処理。

ダイスローラー — 2d6+3 / 4d6kh3 表記対応 (Web Crypto)
2d6+3 や 1d20-2、4d6kh3 (上位 3 つ残し) のような TRPG / ボードゲームでよく使うダイス表記をパースして振る、ブラウザ完結のダイスローラー。乱数は Web Crypto API (crypto.getRandomValues + 拒否サンプリング) で完全に均等分布。プリセット (d4 / d6 / d8 / d10 / d12 / d20 / d100 / 3d6 / 4d6kh3 …) も用意。直近 20 回までのロール履歴をブラウザ内に保持します。サーバー送信なし。
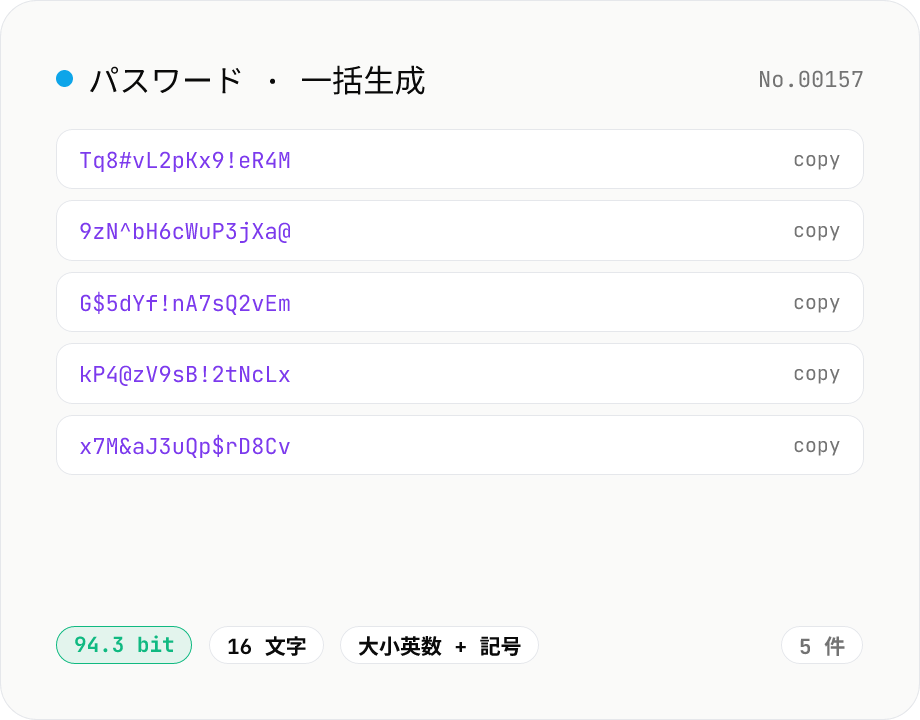
パスワード生成 — 強度 / 文字種 / 桁数指定
強いランダムパスワードを 1〜25 件まとめて生成できます。長さ・文字種・紛らわしい文字の除外を選択可。crypto.getRandomValues ベースでブラウザ内処理。