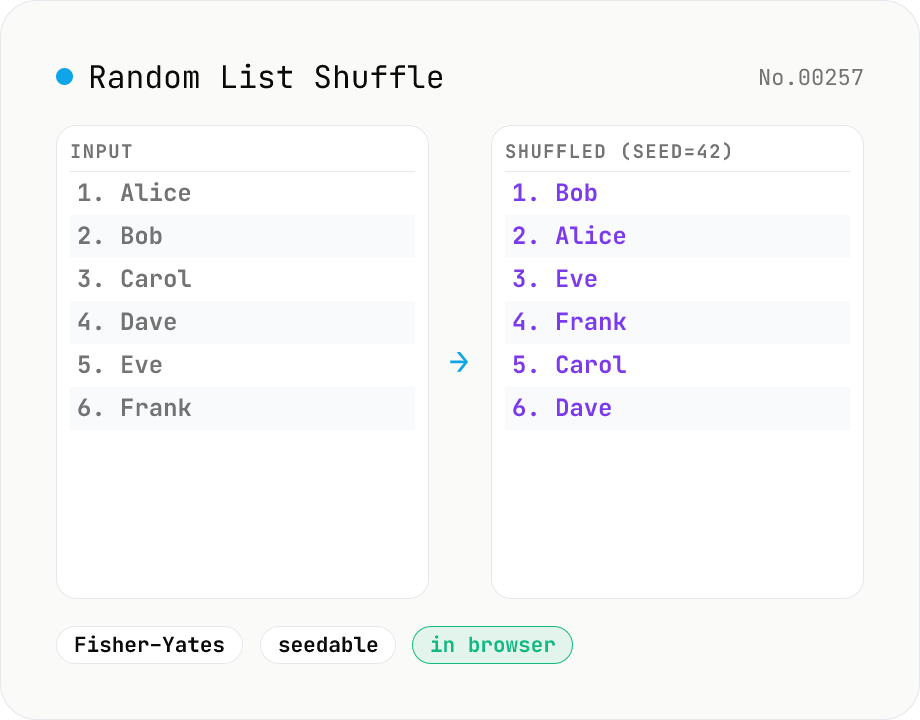
Random List Shuffle (with team-split)
Paste a list (one item per line) and the Fisher–Yates algorithm shuffles it randomly. Provide a seed and the same input → same output (useful when you want to share or reproduce a team draw later). Optional N-per-team grouping and dedupe. Perfect for lotteries, seating, team formation, and random sorts.
How to use
Paste a list (names, numbers, choices — one per line) and hit Shuffle. The **Fisher–Yates** algorithm produces an unbiased random permutation. Pass a **seed** (number or string) to make the result reproducible — same seed + same input = same shuffle, ideal when you want to verify a draw later or share a deterministic team split. **Group size** N (≥1) splits the result into N-per-team groups (8 people, size 2 → 4 teams; size 3 → 3 teams + 1 remainder). **Remove duplicates** keeps only the first occurrence of each item. Leave the seed blank for a fresh shuffle on every click.
In depth
The list you shuffle may be more sensitive than the shuffle itself
Shuffling looks like a neutral operation, but the list being shuffled can carry significant sensitivity. Employee names for a team-formation draw, customer IDs for a raffle, project candidates for a prioritisation round — each list reflects internal organisational structure, customer data, or strategic direction. These are not inputs that should routinely transit a third-party server.
The shuffle algorithm itself is trivially implementable in browser JavaScript, yet many online shuffle tools are structured as server-side form submissions — partly because their advertising model requires server-side page loads and requests. Pasting a staff list into such a form sends that list to an operator you have not vetted for data handling.
Why server-side shuffle services are architecturally unnecessary
No mathematical requirement forces a shuffle to happen server-side. Fisher–Yates runs in linear time in the browser on any modern device with no perceptible delay, even on lists of tens of thousands of items. The only reason to involve a server is to track the user or to support reproducibility features that the operator manages. Neither of those is a reason to hand over the list contents.
When the shuffle includes a seed for reproducibility — common for draws where participants need to verify fairness after the fact — the combination of seed and list leaving the browser means a third party can reproduce the result themselves. If the seed was chosen to match a known quantity (today’s date, a stock price, a public hash), there is no marginal privacy gain from using an online service instead of a local tool.
Fisher–Yates and Mulberry32 PRNG run entirely in the browser
This tool implements the Durstenfeld-optimised Fisher–Yates shuffle in browser JavaScript. When a seed is provided, Mulberry32 (a 32-bit seeded PRNG, period 2^32) derives a deterministic sequence — same seed, same list, same output every time. Without a seed, the tool draws from crypto.getRandomValues, the browser’s cryptographically secure random source.
Input list, seed, and shuffle result all stay in page memory. No network requests are made. Employee names, customer IDs, and project rosters can be shuffled without any data leaving the device.
Making draws verifiable without sacrificing privacy
Publishing the seed before the draw and then running the shuffle publicly lets any participant verify the result independently — same seed plus same list reproduces the same permutation. If the seed is derived from a public, unpredictable value (a future block hash, a sports score, an exchange rate at a fixed time), it is also provably unmanipulable. All of this is achievable with a local tool. The group-size feature handles the common case where n participants cannot be evenly divided, creating a small remainder group rather than silently dropping members. To prepare the input — for instance, removing duplicate names with line-dedupe or alphabetising the result with line-sort — both companion tools stay browser-local as well.
Fisher–Yates bias avoidance and Mulberry32 period
The Fisher–Yates / Knuth shuffle iterates from the array’s tail to its head, drawing a uniformly random integer in [0, i] at each position i and swapping the current element with the one at that index. The algorithm is O(n) in time and O(1) in extra memory — but the uniformity requirement on the index draw is easy to violate. Implementing the draw as Math.floor(Math.random() * n) introduces modulo bias whenever n is not a power of two: certain output permutations are produced slightly more often than others. This tool uses Mulberry32 output divided directly across the 32-bit integer space when seeded, and rejection sampling on crypto.getRandomValues(Uint32Array) when unseeded, removing the bias in both paths.
Mulberry32 itself is a compact 32-bit-seeded PRNG: state += 0x6D2B79F5; let t = state; t = Math.imul(t ^ (t >>> 15), t | 1); t ^= t + Math.imul(t ^ (t >>> 7), t | 61); and the high bits of t ^ (t >>> 14) form the output. Period is 2^32 ≈ 4.3 billion. It passes PractRand within its period and is fine for raffle-class workloads but is not a cryptographically secure RNG. For lists where N! > 2^32 (roughly N ≥ 13), a 32-bit seed cannot reach every possible permutation; if that property matters for your draw, use the unseeded (crypto) mode instead.
Verifiable draws, commit-reveal patterns, and shuffle pitfalls
For a draw to be auditable, a useful pattern is commit-reveal: publish a hash of the seed (SHA-256 is fine) before the draw, publish the candidate list, and then reveal the seed afterwards. This prevents the organiser from grinding through seeds until a favourable result appears. Even better: derive the seed from a public unpredictable source — a future blockchain block hash, the closing price of a public index, or a Drand beacon — so no party has the option to choose it adversarially. Selecting the seed privately after the draw defeats the whole verification mechanism, because no one else can reproduce the result.
Watch out for: (a) trailing whitespace or full-width spaces hiding in list items, which the dedupe option will not collapse (this tool normalises LF/CRLF but preserves whitespace inside each line); (b) inconsistent handling of the remainder when “N per team” does not divide evenly — this tool creates a smaller final team rather than discarding people; (c) the fact that reusing the same seed across slightly different input lists yields very different output orderings, because Fisher–Yates consumes random values in order from the end of the array. Adding even one extra item to the input changes which random draws apply where. If you want a stable position for a specific item (e.g. “this person always goes first”), do the shuffle and then place that item in a separate post-processing step.
FAQ
- Is my input uploaded?
- No. Everything happens in your browser — RNG, shuffle, grouping all run locally in JS.
- What is the Fisher–Yates algorithm?
- The classic unbiased shuffle, proposed by R. A. Fisher and F. Yates in 1938 and optimised by R. Durstenfeld in 1964. Walk the array from end to start, and at each index `i`, pick a random index in `[0, i]` and swap with `i`. Runs in `O(n)` and provably produces every permutation with equal probability (`1/n!`). Skip the naive `sort(() => Math.random())` — its distribution is biased.
- What's the seed for?
- **Reproducibility**. `Math.random()` gives a fresh answer every call, but if you derive randomness from a seed, the same seed yields the same shuffle. Useful when 'the teacher drew lots → I want to show the kids the same draw later' or 'auditors want to verify the result wasn't cheated'. We use Mulberry32 (32-bit seeded PRNG, period 2^32, fast and good enough for non-cryptographic use).
- What if I type a string seed?
- It's hashed via FNV-1a into a 32-bit integer before feeding the PRNG. `"hello"` and `"world"` map to different hashes → different shuffles; the same string always maps to the same hash → reproducible. Same effect as typing a number directly (we normalise internally).
- What if group size doesn't divide evenly?
- A remainder group is created at the end. 10 items at size 3 → 3 / 3 / 3 / 1. For team formation, either fold the last small group into an existing one or label them as substitutes / reserves.
- Why not just `sort(() => Math.random() - 0.5)`?
- JavaScript `sort` assumes the comparator is **consistent**, so a function that returns randomness produces a biased distribution (V8's TimSort favours certain permutations). The bias grows with array size. Fisher–Yates is the unbiased classic, which is why this tool uses it.
How to verify nothing is uploaded
This tool never sends your input outside your browser. The pages below explain how it works, how to audit it, and how the site is run.
Related tools
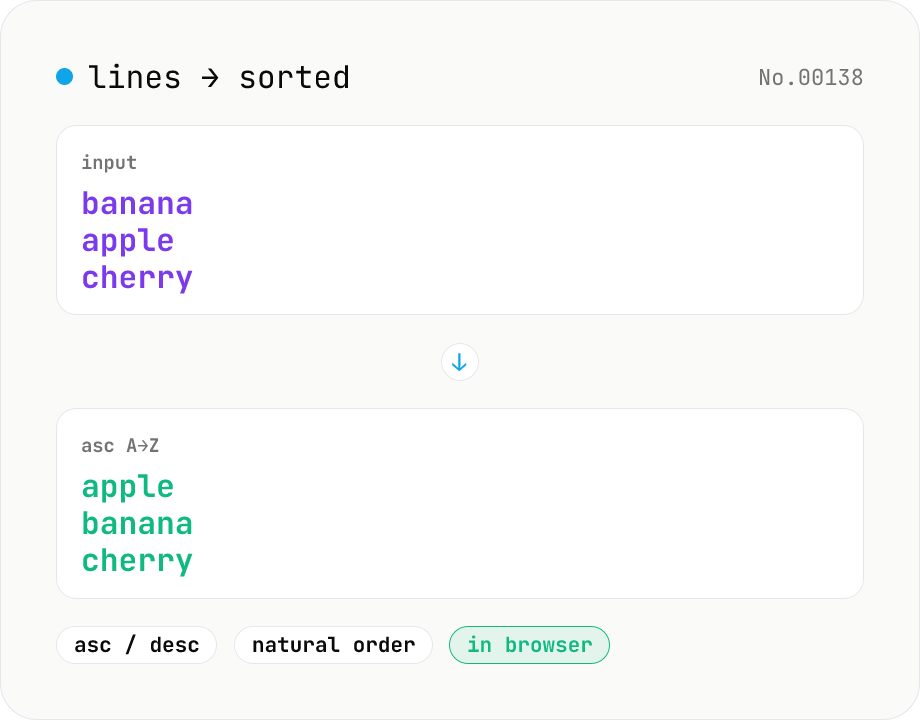
Line sort — asc / desc / numeric / locale
Split the input by newline and sort the lines either ascending (A→Z) or descending (Z→A) using locale-aware Unicode comparison. Numeric runs (file1, file2, file10) sort naturally. Empty lines and the trailing newline are preserved. Works with mixed Japanese/ASCII text. Runs entirely in your browser.
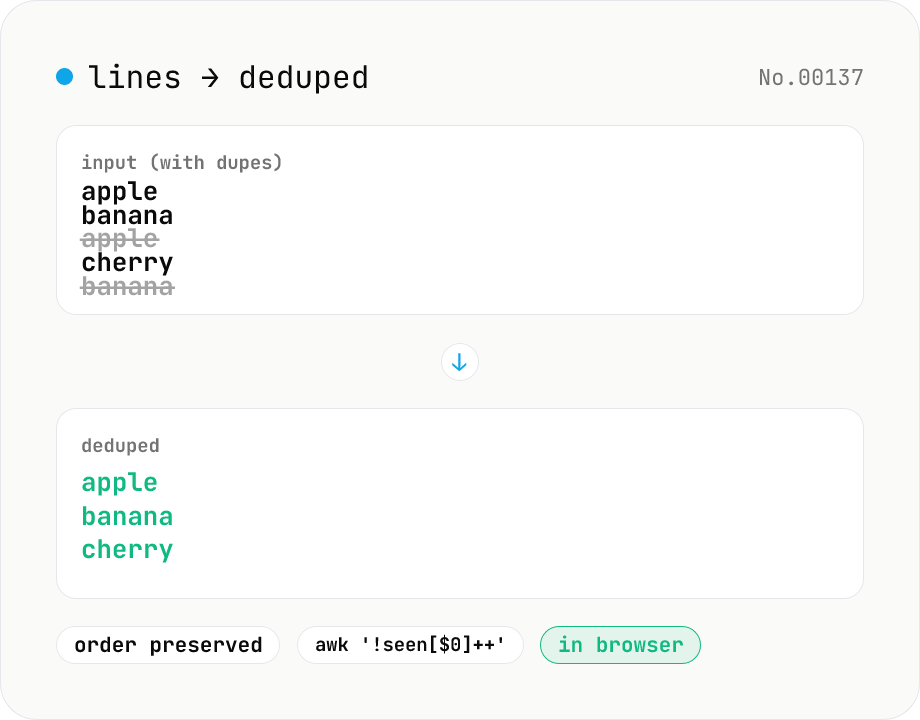
Line dedupe — keep unique or extract duplicates
Split the input by newline and remove duplicate lines, keeping only the first occurrence of each line in original order. Catches non-adjacent duplicates as well (equivalent to `awk '!seen[$0]++'`). Runs entirely in your browser.
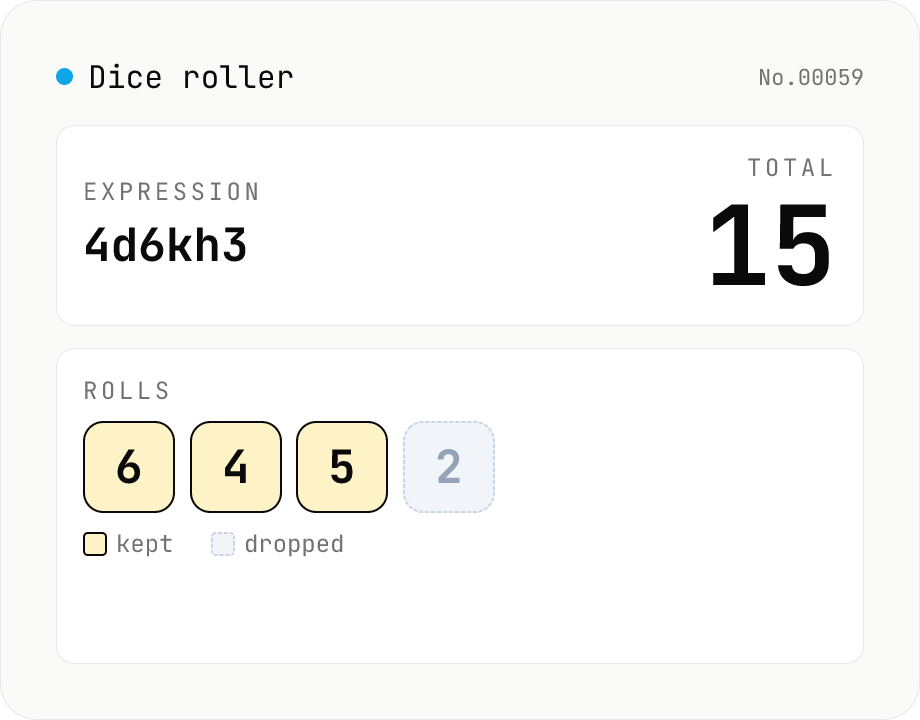
Dice roller — 2d6+3 / 4d6kh3 notation (Web Crypto, no server)
Roll TTRPG / board-game dice using familiar notation: 2d6+3, 1d20-2, 4d6kh3 (keep highest 3), 3d6+1d4-1, and more. Randomness uses the Web Crypto API (crypto.getRandomValues with rejection sampling) for an exactly uniform distribution. Comes with one-click presets (d4 / d6 / d8 / d10 / d12 / d20 / d100 / 3d6 / 4d6kh3, …) and an in-browser history of the last 20 rolls. Nothing is uploaded.
Password generator — strength, char sets, length
Generate strong random passwords in batches of 1–25. Pick length, character sets, and toggle look-alike exclusion. Backed by crypto.getRandomValues and runs entirely in your browser.