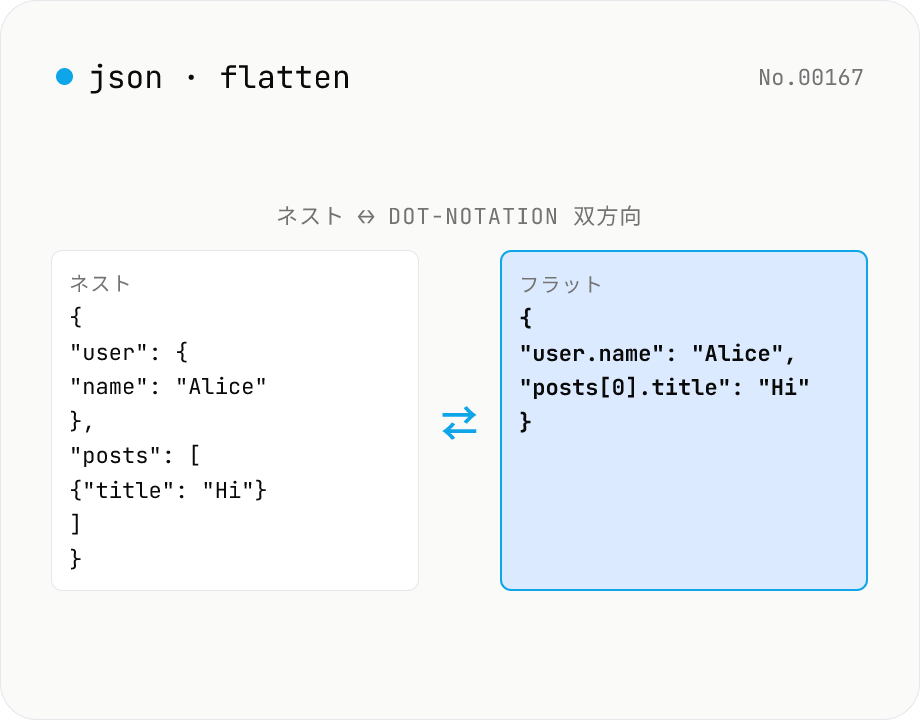
JSON Flatten / Unflatten — dot-notation キーで平坦化・復元
ネストされた JSON を **dot-notation キー** (`user.address.city`) や **bracket notation** (`posts[0].title`) で平坦化、または平坦キーから元のネスト構造に復元。Mode 切替で双方向。区切り文字 (`.` / `/` / `["key"]`) と配列スタイル (`[0]` / `.0`) を選択可能。**.env ファイル風 → JSON 復元**、**i18n キーの正規化**、**Excel/CSV エクスポート前の平坦化**、**Algolia/Elasticsearch のフィールド整形** などで重宝。
使い方
**Mode** で **平坦化 (flatten)** / **復元 (unflatten)** を切替: 平坦化は `{a: {b: 1}}` → `{"a.b": 1}`、復元はその逆。**配列** は `arr[0].x` (bracket) または `arr.0.x` (index) で表現選択可。**区切り文字** は `.` (dot) / `/` (slash) / `["key"]` (bracket) の 3 種。**空のオブジェクト / 配列** はトグルで保持選択可 (`{empty: {}}` → `{"empty": {}}` or 削除)。設定ファイル合体 (yaml ↔ env)、i18n キー正規化、Algolia attribute 化、Elasticsearch field flattening、Excel/CSV エクスポート前処理などで重宝。
詳細解説
JSON の構造変換が扱うデータの機微性
JSON の flatten・unflatten 操作が行われる典型的なシーンは、API レスポンスの変換・設定ファイルの環境変数化・i18n 翻訳データの整形・データベーススキーマの前処理です。これらのデータには顧客情報・API キー・データベース接続文字列・内部サービスのエンドポイントが含まれていることが多くあります。
特に flatten 操作はデータ構造の設計を露わにします。\{"user.billing.card.last4": "1234"} のようなフラットキーはデータモデルの内部構造をそのまま示しており、DB の設計・フィールド名・ネスト構造が外部のサービスに伝わることになります。スキーマ情報が漏洩することは、システム設計書の一部を共有するのと同義です。
オンラインの JSON ツールにネストした設定を送るリスク
設定ファイルの JSON (特に CI/CD パイプラインの環境設定、マイクロサービスのサービス設定、クラウドリソースの定義ファイル) には秘密情報が含まれていることがあります。これらを flatten・unflatten するためにオンラインツールに貼り付けると、その内容がサーバーに送信されます。
見た目に複雑なネスト JSON ほど、一度に多くの情報を含んでいます。JSON を展開してキーを確認してから「これは外部に出してはいけない」と気づく、という順序になりやすいのが、オンラインツールを使う場合の構造的な問題です。ローカルで処理するツールは、確認前に情報が外部に出るリスクを根本的に排除します。
JSON.parse と再帰アルゴリズムだけでブラウザ内完結
このツールの flatten・unflatten 処理は JSON.parse で入力をパースし、再帰的にオブジェクトツリーを走査してキーを結合・分解するだけです。外部ライブラリへの依存なしに実装されており、Dot (.)・Slash (/)・Bracket (["key"]) の 3 種類の区切り文字と、bracket/index 2 種類の配列記法をすべてブラウザ内で処理します。型 (number / string / boolean / null) はリーフ値として JSON.parse の結果をそのまま保持し、unflatten 時に配列インデックスを数値として認識して正しく再構築します。
入力した JSON はページメモリ内にのみ存在し、処理の間もネットワーク送信は一切発生しません。機密を含む設定ファイルや API レスポンスの変換処理をブラウザのタブ内で完結させることができます。
実務での安全な変換ワークフロー
i18n 翻訳データを Crowdin・Lokalise へインポートする前の flatten 変換、MongoDB の $set クエリ生成のための \{"user.address.city": "Tokyo"} 形式への変換、CSV エクスポート前のネスト解除など、データパイプラインの前処理として JSON 構造変換が必要な場面は多いです。このツールではその全工程をブラウザ内で完結させることができるため、処理対象のデータが顧客情報を含んでいても、外部への送信なしに変換・確認・コピーの一連の作業を実施できます。flatten した結果を整形して読みたい場合は json-format、特定パスだけ抽出したい場合は json-path-query も同様にローカルで動作します。
再帰アルゴリズムとキー衝突 / 区切り文字エスケープの罠
flatten の実装は深さ優先の再帰関数で、現在のキーパス (例: user.address) を引数として渡しながら子要素を辿ります。リーフ値 (number / string / boolean / null) に到達したらキーパスとペアで結果オブジェクトに登録します。配列は要素ごとに [0] / [1] 形式でキーパスを伸ばします。unflatten はその逆で、キーパスを区切り文字で分割し、数値セグメントは配列インデックス、文字列セグメントはオブジェクトキーとして再構築します。
最も踏みやすい罠はキー名に区切り文字が含まれるケースです。{"foo.bar": "value"} のように元キーに . が含まれていると、flatten 後に foo.bar だけ見て unflatten すると { foo: { bar: "value" } } になってしまい元構造を失います。標準的な対策はキー名のエスケープ (foo\.bar) ですが、実装によっては未サポートのことがあります。本ツールでこの問題に遭遇したら、区切り文字をデフォルトの . から / や bracket notation に切り替えることでキー衝突を避けられます。
MongoDB / Elasticsearch / Algolia / Crowdin での実用上の差
MongoDB の $set クエリは flatten 形式 ({ "user.address.city": "Tokyo" }) を直接受け付け、ネストフィールドへのピンポイント更新に使われます。配列要素は $ 演算子 ("posts.$.title": ...) で扱うため、本ツールの [0] / .0 形式とは別系統です。Elasticsearch の flatten field type (7.3+) は機械的にネストを潰しますが、検索クエリ側は field.subfield.subsubfield のドット記法でアクセスする必要があります。
i18n の Crowdin / Lokalise は階層キー (messages.button.submit) と flat キー (messages_button_submit) のどちらでもインポートできるサービスが多いですが、エクスポート時の形式は設定により異なります。Algolia は最大ネスト深さがプランで制限されるため、深いネストを flatten してから送信する用途で使われます。本ツールが 2 種類の配列記法と 3 種類の区切り文字をサポートするのは、これら下流サービスごとに期待する形式が違うためで、変換後の形式を目視で確認してから配布する運用が現実的です。
よくある質問
- 入力データはサーバーに送信されますか?
- いいえ。すべてブラウザ内で完結します。`JSON.parse` と純粋な再帰アルゴリズムのみで、外部 API は使いません。
- 平坦化 (flatten) はどう動きますか?
- 再帰的にオブジェクトのキーを区切り文字でつないで 1 段のキー/値ペアに変換します。例: `{user: {name: 'Alice', age: 30}}` → `{"user.name": "Alice", "user.age": 30}`。配列は要素ごとに index を付与: `{posts: [{title: 'Hi'}]}` → `{"posts[0].title": "Hi"}` (bracket) または `{"posts.0.title": "Hi"}` (index)。
- 復元 (unflatten) はどう動きますか?
- フラットキーを区切り文字で分割し、各セグメントが数値なら配列を、文字列ならオブジェクトを生成して再構築。`{"user.name": "Alice", "posts[0].title": "Hi"}` → `{user: {name: 'Alice'}, posts: [{title: 'Hi'}]}`。**flatten → unflatten** はラウンドトリップ可能 (空オブジェクト保持あり)。
- ドット (.) がキー名に含まれる場合は?
- **ドット区切りでは曖昧** になります。例: `{"a.b": 1}` を unflatten すると `{a: {b: 1}}` になりますが、元のキー名が `"a.b"` という 1 つのキーだった可能性もある。曖昧さを避けたい場合は **`/` 区切り** または **`["key"]` 区切り** をお使いください: `{"a/b": 1}` → `{a: {b: 1}}`、`{"[\"a.b\"]": 1}` → `{"a.b": 1}`。
- 配列スタイル `[0]` と `.0` の違いは?
- **`[0]` (bracket style)** は JavaScript の慣用表記で、`posts[0].title` のように **オブジェクトキーと配列インデックスを視覚的に区別** できる。**`.0` (index style)** はパス区切りに統一されるので **MongoDB の dot-notation や `lodash.set` の path** などのライブラリと互換性あり。プロジェクトの慣習に合わせて選択。
- 空のオブジェクト / 配列の扱いは?
- **「空のオブジェクト / 配列を保持」** ON (デフォルト): `{empty: {}, arr: []}` → `{"empty": {}, "arr": []}` (平坦化後も空コンテナを残す)。OFF: 完全に削除。OFF にすると往復で構造が変わる (元の空コンテナが失われる) ので、ラウンドトリップを保証したいときは ON のままに。
- ユースケースは?
- (1) **i18n キーの正規化**: ネストされた翻訳 JSON を flatten して翻訳エディタ (Crowdin/Lokalise) へインポート → 編集後 unflatten。(2) **設定ファイル合体**: `app.config.json` を flatten → `.env` 風に変換 → 環境変数化。(3) **Algolia attribute インデックス化**: ネストされたドキュメントを flatten してフィルタ可能フィールドに。(4) **Excel/CSV エクスポート**: ネストを 1 列ごとに平坦化してテーブル化。(5) **MongoDB の `$set` クエリ生成**: `{ "user.address.city": "Tokyo" }` 形式に。
- 型 (number / boolean / null) は保持されますか?
- **保持されます**。リーフ値の型は `JSON.parse` の結果そのまま (number / string / boolean / null) で、文字列に変換されません。配列インデックスや数値キーは内部的に数値として扱われ、unflatten 時に配列として再構築されます。
- 他に Mode 切替で扱えるツールは?
- **`yaml-json-convert`** (YAML ↔ JSON 双方向)、**`toml-json-convert`** (TOML ↔ JSON)、**`csv-json-convert`** (CSV ↔ JSON)、**`xml-json-convert`** (XML ↔ JSON) など、`-convert` 系の Mode 切替ツールが揃っています。これらは「データ形式の変換」、本ツールは「同じ JSON 内での構造変換」という棲み分け。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール
JSON 整形・検証 — インデント / 圧縮 / エラー表示
JSON をブラウザ内で整形 (インデント指定) ・最小化・バリデーションします。エラー行・列を表示。データは一切外部に送信されません。

JSON 比較 / 差分 — 構造的に違いを抽出
2 つの JSON を構造的に比較。オブジェクト/配列のネストを再帰的に解析し、追加・削除・変更・移動の各差分をハイライト表示します。すべてブラウザ内で処理。
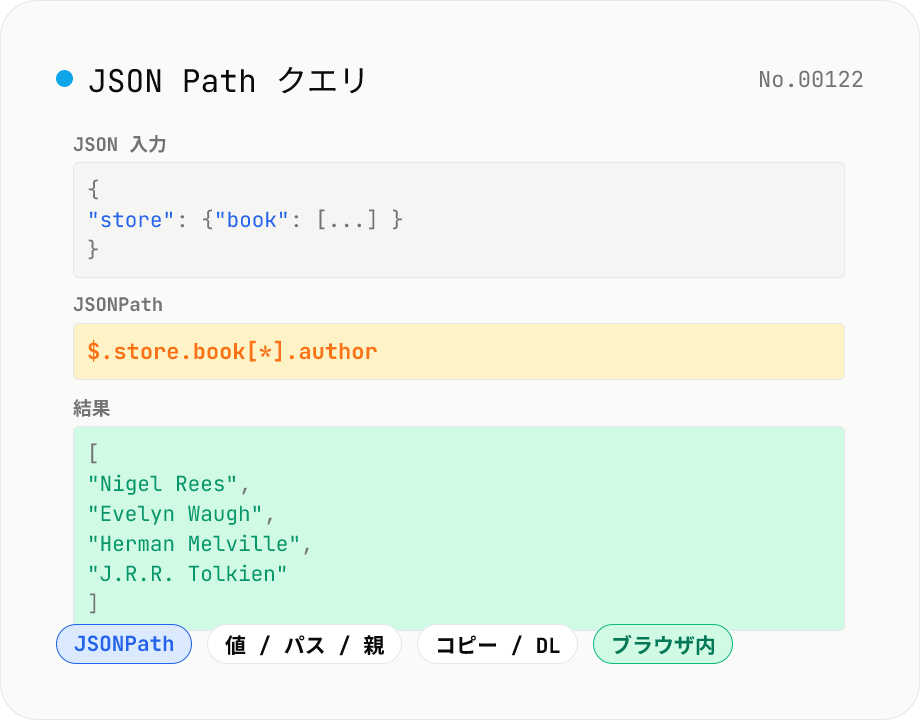
JSON Path クエリ — JSONPath で JSON ツリーを探索
JSON データに対して JSONPath クエリ (例: `$.store.book[*].author`) を実行して、必要な値だけを取り出します。jsonpath-plus (MIT) でブラウザ内処理、結果は値・パス・親ノードのいずれかで取得可能。API レスポンスの抽出、ログから特定フィールドだけ抜き出す、設定ファイルの値確認、DevTools での JSON 探索に便利。複雑な式 (`?(@.price < 10)` / `$..` / `[?(@.tag=='x')]`) も使えます。データはブラウザ内でのみ評価され、外部送信はありません。
YAML ⇄ JSON 変換 — インデント保持
YAML と JSON を相互変換します。インデント (2 / 4 / タブ) 切替・サンプル付き。eemeli/yaml ライブラリでブラウザ内処理。