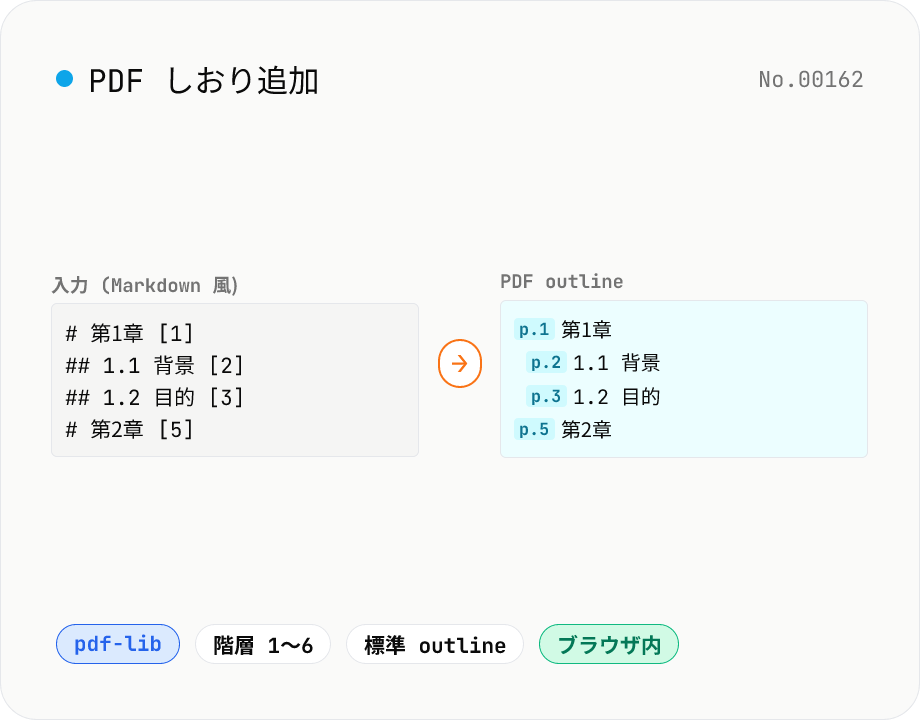
PDF しおり追加 — outline / bookmark を一括登録
PDF にしおり (outline / bookmark) を Markdown 風記法 (`# 第1章 [3]`) で一括登録します。pdf-lib の低レベル API で Catalog に Outlines オブジェクトを構築、`#` の数で階層を表現 (1〜6)、各行末にページ番号を `[3]` 形式で指定。スキャナで作った PDF や、章タイトルが無い長文 PDF を Acrobat / Preview / ブラウザの PDF ビューワで素早く目次から飛べるようにします。ブラウザ内で完結、PDF はサーバーに送信されません。
使い方
しおりを追加したい PDF を 1 つドロップまたは選択します。 しおり構造を Markdown 風の記法で書きます。`#` の数 (1〜6) で階層、各行末に飛び先ページを `[3]` 形式で指定します。 解釈結果プレビューで階層と件数を確認します。エラーがある行は赤で表示されます。 「しおりを追加して保存」を押すと、pdf-lib でしおり (outline) を組み立てて新しい PDF として書き出します。
よくある質問
- ページ番号はどう数える?
- PDF の物理ページ番号 (1 始まり) です。表紙が 1 ページ目の場合は `[1]`、本文が 2 ページ目から始まるなら `[2]` と書きます。元 PDF に表示されているページ番号 (i, ii, iii や前付け) ではなく、PDF ビューワ右下の「N / Total」の N を使ってください。
- 階層は何段階まで?
- 1〜6 段階 (`#` から `######`) です。PDF 仕様上はもっと深くも可能ですが、人間が追える範囲として 6 段階までに制限しています。階層を飛ばしてもエラーにはなりませんが、`#` → `###` のように直接 2 段下げると見た目がおかしくなることがあります。
- 既存のしおりはどうなりますか?
- 削除されます。本ツールは PDF の `/Outlines` をいったん消してから新しい構造を書き込むため、元の outline が残ることはありません。残したい場合は事前に PDF ビューワで書き出すなどしてバックアップしてください。
- Adobe Acrobat 以外のビューワで開けますか?
- 標準の PDF outline 仕様に準拠しているので、Acrobat / Preview / Chrome / Firefox / Edge / iBooks 等で同じように表示されます。Adobe 独自の拡張機能 (アクション付きしおりなど) は使っていません。
- 暗号化された PDF も処理できますか?
- できません。パスワード解除してから再度試してください。
- データはどこかに送信されますか?
- いいえ。pdf-lib はブラウザ内で動作し、PDF はアップロードされません。
類似のツール

PDF ページ番号 — テンプレ / 9 位置 / 範囲指定
PDF の各ページに番号を埋め込みます。フォーマット (`{n}` / `{n} / {total}` / `Page {n}` など) はテンプレート文字列で自由指定可能。位置 (9 グリッド)、フォントサイズ、色、開始番号、余白、適用ページ範囲を細かく調整できます。pdf-lib でブラウザ内処理するので、ファイルは外部に送信されません。複数 PDF の一括処理と ZIP 一括ダウンロードに対応。
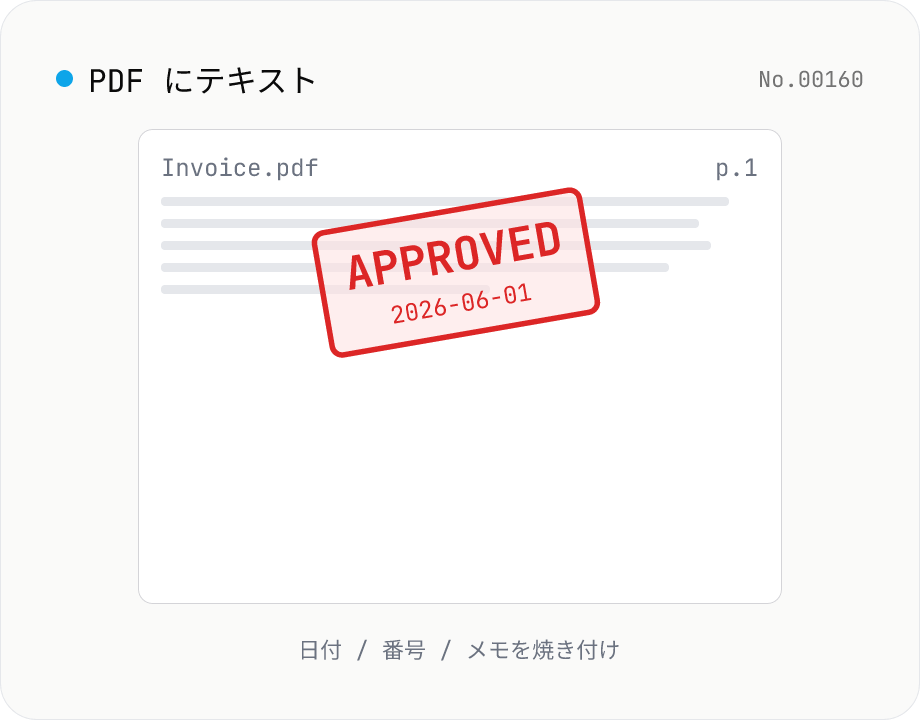
PDF にテキストを書き込む — 注釈 / 日付 / メモを焼き付け
PDF の指定ページにテキストを書き込みます。「日付」「メモ」「ファイル番号」など、見栄えだけ整えればよい英数字の注釈を後付けする用途に最適。位置は 9 グリッド + 余白、フォントサイズ・色・回転・不透明度を調整できます。フォントは pdf-lib 標準の Helvetica (Regular / Bold / Oblique) を使うため英数字専用。日本語テキストを書き込みたい場合は stamp-jp で印鑑風画像を作って pdf-add-image で貼る方法を推奨。複数の PDF をまとめて処理でき、結果は ZIP でダウンロード可能。アップロードした PDF はサーバーに送信されず、すべてブラウザ内で処理されます。

PDF テキスト抽出 — .txt 書き出し
PDF からプレーンテキストをブラウザ内だけで抽出します。pdfjs-dist の getTextContent でページごとに文字列を集め、1 ファイル = 1 つの .txt として書き出し。複数 PDF はまとめて ZIP でダウンロードできます。ページ区切りマーカーの有無は切り替え可能。
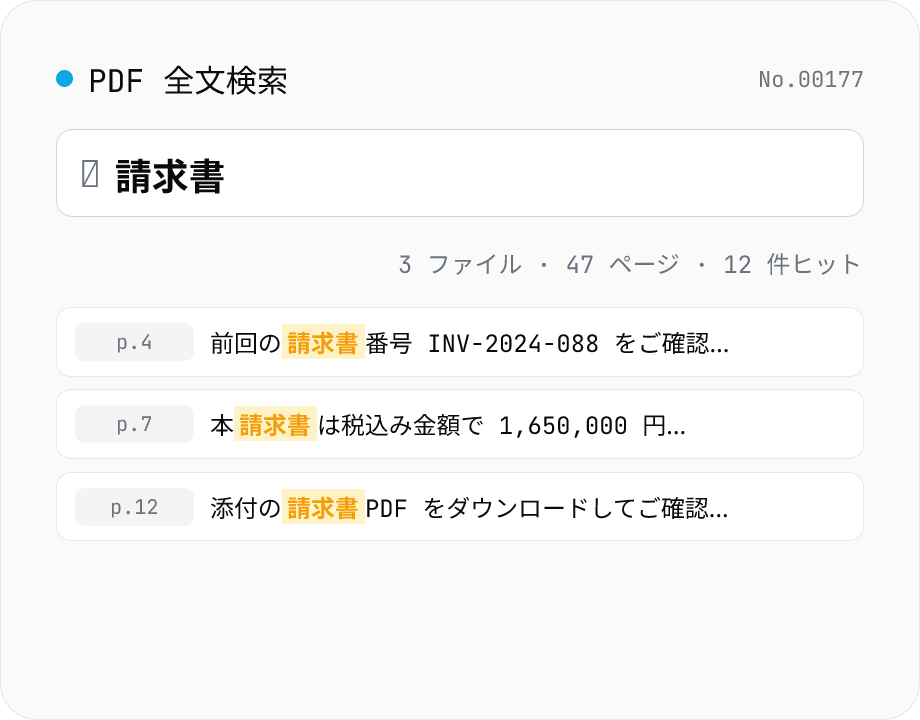
PDF 全文検索 — 複数 PDF を横断検索
複数の PDF をまとめて全文検索し、ヒットしたページ番号 + 行の前後を抜粋表示します。大文字小文字の区別、単語境界 (\b)、正規表現、複数行モードの 4 オプション。検索クエリと前後文字数 (10〜200 字) を変えるとリアルタイムで再抽出。ファイルごとのヒット件数を一覧でき、結果は CSV としてダウンロード可能。アップロードした PDF はサーバーに送信されず、すべてブラウザ内で完結します。