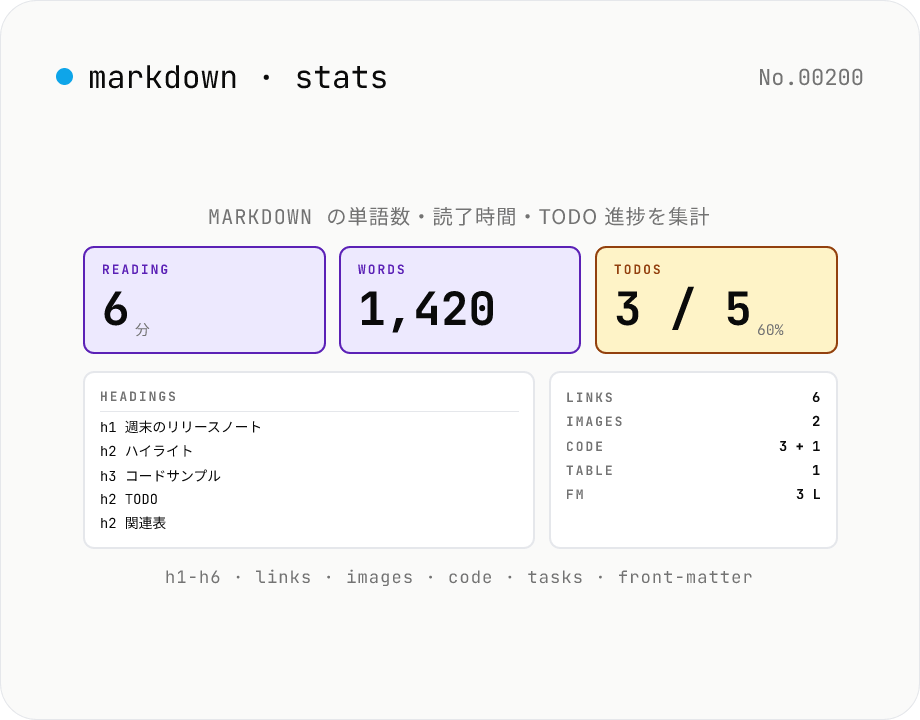
Markdown 統計 — 文字数・読了時間・見出し・TODO を集計
**Markdown テキスト** を貼り付けると、**文字数 (空白あり / 空白なし)**、**単語数 (日本語は CJK 1 文字 = 1 単語でカウント、英文は空白区切り)**、**読了時間** (235 wpm 想定)、**段落数**、**文の数**、**見出し** (h1〜h6 の内訳 + 階層リスト + アンカー slug)、**リンク** (inline / reference / autolink + URL 一覧)、**画像数**、**コードブロック** (fenced ``` / インデント 4 スペース + インラインコード `\`xxx`\``)、**引用 (blockquote)**、**リスト** (順序付き / 順序なし / タスク)、**TODO チェックボックス** (`- [ ]` 未完了 / `- [x]` 完了の進捗率)、**テーブル数**、**front-matter 検出** (`---` 〜 `---` の行数) をすべて自動集計します。**ブログ記事の SEO 用文字数チェック**、**Notion / Obsidian / Hugo / Astro Markdown のドキュメント分析**、**TODO 進捗の見える化** に最適。**完全にブラウザ内** で解析、入力 Markdown はサーバーに送信されません。自前パーサー (~430 行、新規依存ゼロ)。
使い方
**入力欄** に Markdown を貼り付けるか、**ファイルを選択** から `.md` / `.markdown` / `.mdx` を読み込むと、**実行ボタン不要で自動的に集計** が走り、以下のカードと一覧が表示されます: **読了時間 / 単語数 / 文字数 / 段落数 / 文の数 / 見出し内訳 (h1〜h6) / リンク内訳 / 画像数 / コードブロック / 引用 / リスト / TODO / テーブル / Front matter / インライン HTML**。**見出しは階層リスト** (level に応じて字下げ)、**TODO は完了率** (`- [ ]` / `- [x]` で集計)、**リンクは URL 一覧** で表示。**サンプル** ボタンで front-matter 付きブログ記事風 Markdown を流し込み可能。
詳細解説
Markdown 統計が必要になる文書の種類
読了時間・単語数・見出し構造を確認したい Markdown ファイルは、公開済みのものより執筆中・レビュー中のものが多いです。ブログ記事の投稿前チェック・技術文書の品質確認・社内ドキュメントの構成レビュー・OSS の README の長さ確認など、「公開前に確認する」という用途が中心です。
TODO の進捗確認 (- [ ] / - [x] の集計) という機能は、プロジェクト管理用の PROJECT.md や TODO.md に使われます。これらのファイルにはプロジェクトの進捗状況・未完了タスクのリスト・担当者情報が含まれていることがあり、内部情報を含む文書が対象になります。
ドキュメント分析ツールに原稿を送るリスク
オンラインの単語数カウンター・読了時間計算ツールは、入力したテキストをサーバーで処理することがあります。執筆中のブログ記事・レビュー中の設計書・社内プロジェクトの進捗ドキュメントがそのまま外部サーバーに届きます。統計を取るだけの操作で、コンテンツが外部に渡ることになります。
MDX ファイルのように React コンポーネントを含む文書では、インポートされるコンポーネント名・props の値・UI の構造情報が本文に含まれていることがあります。これらも分析ツールに渡った場合は、アプリケーションの実装情報が漏洩します。
自前スキャナーでブラウザ内完結する仕組み
このツールの Markdown 解析は約 430 行のゼロ依存自前スキャナーで実装されています。外部ライブラリ (marked・remark 等) は使っていません。ATX 見出し (# foo) と Setext 見出し (タイトル + === / ---) の検出、フェンスドコードブロック (```) と 4 スペースインデントコードブロックの除外、frontmatter ブロック (--- … ---) の本文からの分離、TODO チェックボックス (- [ ] / - [x]) の集計、GitHub 互換アンカー slug の生成はすべてブラウザ内で実行されます。
入力した Markdown はページメモリにのみ存在します。執筆中の原稿・社内のプロジェクト文書・未公開のドキュメントを安全に分析できます。
コンテンツ品質管理と執筆ワークフローに
技術ブログの投稿前チェック (読了時間が適切か・見出し構造が正しいか・外部リンクが含まれているか)、OSS の README が長くなりすぎていないかの確認、PROJECT.md の TODO 進捗率の把握など、公開前の品質チェックに使えます。見出し一覧 (Outline) は markdown-toc に渡す前の確認としても活用できます。生のテキスト文字数だけ手早く知りたい場合は case-counter も同じ流れで使えます。
単語数カウントの計算規則: 英語 / CJK 混在と Medium / 読了時間学術文献の対比
単語数のカウント方法は言語ごとに本質的に違います。英語は空白区切りで「単語境界」が明示的なので 'It is a test.' を 'It', 'is', 'a', 'test' と分割すれば 4 単語と単純に決まります。日本語・中国語・韓国語 (CJK) には単語境界がなく、形態素解析 (kuromoji / MeCab) で文を分かち書きしないと「単語」が定義できません。本ツールは妥協案として「CJK 文字 1 文字 = 1 単語」のヒューリスティクスを採用しています — 日本語の文章で MeCab 単語数とほぼ近い数字が出ることが知られており、文字数ベースよりも執筆経験者の直感に近い数字になります。
読了時間は Medium が広めた「平均的な英語読者は 1 分間に 235 単語を読む」という指標が広く使われており、本ツールも 235 wpm をデフォルトにしています。Carver, Coon, & Davis (1990) の音読研究では 250-300 wpm、Brysbaert (2019) の包括的レビューでは沈黙読書で 175-300 wpm の幅が報告されており、235 はその中央値付近です。日本語は漢字・かな・カタカナで読みやすさが変わるため、欧米の wpm をそのまま適用するのは厳密にはずれますが、ブログ記事の「目安」として広く受け入れられている数値です。技術書のような難易度の高い文章はこれより遅く、SNS の短文は速くなるため、ジャンルに応じて mental adjustment が必要です。
Markdown 統計の罠: フェンスドコードブロック / frontmatter / GFM テーブルが単語数に紛れ込む
ナイーブな単語カウントの最大の落とし穴は、フェンスドコードブロック内のコードを単語として数えてしまうことです。for (let i = 0; i < arr.length; i++) のような行は記号と単語が混じっていて統計を歪めます。本ツールは ``` フェンス内とコードブロック (4 スペースインデント) 内のテキストを word count から除外しますが、その他のオンラインカウンターはこの処理をしないことが多く、コードを多く含む技術記事で「単語数が異常に多い」と表示される原因になります。
frontmatter ブロック (--- で囲まれた YAML メタデータ) も同様で、title: My Article のような YAML を本文として数えると見出し数や単語数が誤集計されます。本ツールは frontmatter を検出して本文から分離する処理を入れています。さらに GFM テーブルの | col1 | col2 | のような区切り文字は単語と数えるべきか曖昧ですが、本ツールはセル内のテキストを単語として数え、| 自体は除外する方針です。「自分の Markdown ファイルの単語数を Hugo / Astro の SSR ビルド時にも表示したい」場合は、本ツールと同じ判定ロジックを使った自前スクリプトを書くのが正確で、wc -w のような Unix ツールは frontmatter とコードブロックを区別しないので過大評価になります。
よくある質問
- 入力データはサーバーに送信されますか?
- いいえ。**自前 Markdown スキャナ** (`~430 行、新規依存ゼロ`) で **完全にブラウザ内** で処理します。外部 API もありません。
- **読了時間** の計算式は?
- **235 単語/分** で割って **切り上げ** た値 (Nielsen Norman Group の英語 reading speed 中央値)。日本語の場合は **CJK 1 文字 = 1 単語** として扱うので、文章 4700 字なら ≒ 20 分。**目安として運用してください** — 専門用語が多い技術文書では遅め、雑誌系では速めになります。
- **日本語の単語数** はどうやって数えていますか?
- 日本語は単語境界が不明瞭なので、本ツールは **CJK 文字 (漢字 / ひらがな / カタカナ / 全角文字) を 1 文字 1 単語としてカウント** します。これは **note.com の文字数表示や、ブログプラットフォームの目安と合致** する単純な方法です。**形態素解析 (kuromoji 等) ベースの正確な単語数** は別ツール (wakati-tokenize) で取得できます。
- **Front matter** はどのように扱われますか?
- ファイル先頭の `---` から次の `---` までを **Front matter として検出**、**本文の集計からは除外** します。これにより `title:` / `date:` / `tags:` の文字数が本文ワードカウントに混ざりません。Hugo / Astro / Jekyll / Eleventy など主要 SSG の典型フォーマットに対応。
- **コードブロック** の中身は集計に含まれますか?
- **含まれません**。**fenced code block (```)** と **インデント 4 スペース / タブ** の両方をスキャンして本文から除外、`````例` ` のインラインコードも word/character count では除外されます。**ただし block 自体の数 (fenced / indented / inline)** はカウントされて Stats カードに出ます。
- **TODO の進捗率** はどう計算していますか?
- `- [ ]` / `- [x]` のチェックボックス行を全部数えて、**完了 (`x`) / 総数** をパーセント化。**ネスト (字下げ) されたタスクも対象**、**ノーマルなリスト項目 (チェックボックスなし)** は除外。`PROJECT.md` や `TODO.md` ファイルの進捗確認に。
- **見出し階層 (Outline)** はどう表示されますか?
- **ATX 見出し** (`# Heading`) と **Setext 見出し** (タイトル + `===` / `---`) の両方を検出、**level に応じた字下げ** で階層リスト表示。各見出しには **GitHub Anchor 風の slug** (例: `# 週末のリリースノート` → `#週末のリリースノート`) を生成 — そのまま `markdown-toc` ツールに渡せばリンク付き目次が作れます。
- **他の markdown-* ツール** との関係は?
- **markdown-stats** = 集計 (本ツール)、**markdown-preview** = 描画プレビュー、**markdown-toc** = 目次生成、**markdown-link-extract** = リンク抽出、**markdown-frontmatter** = YAML front-matter パース、**markdown-table-format** = テーブル整形、**markdown-html-convert** = ↔ HTML 変換。役割が明確に分離してあり、必要なツールを選んで使えます。
- **case-counter** との違いは?
- **case-counter** は **プレーンテキスト用** で「大文字 / 小文字 / アルファベット / 数字 / 記号」など文字種別のカウントが中心。**markdown-stats は Markdown 構文を理解した上で集計** するので、見出し / リンク / TODO / コードブロックの数まで取り出せます。
- **MDX** (React 埋め込み Markdown) も解析できますか?
- **できますが React コンポーネント部分は無視されます**。`<MyComponent prop="value" />` のような JSX は **インライン HTML として 1 件カウント**、children はテキストとして集計。**props の値や import 文** は Markdown ではないので分析対象外です (それらを抽出したい場合は別ツール)。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール
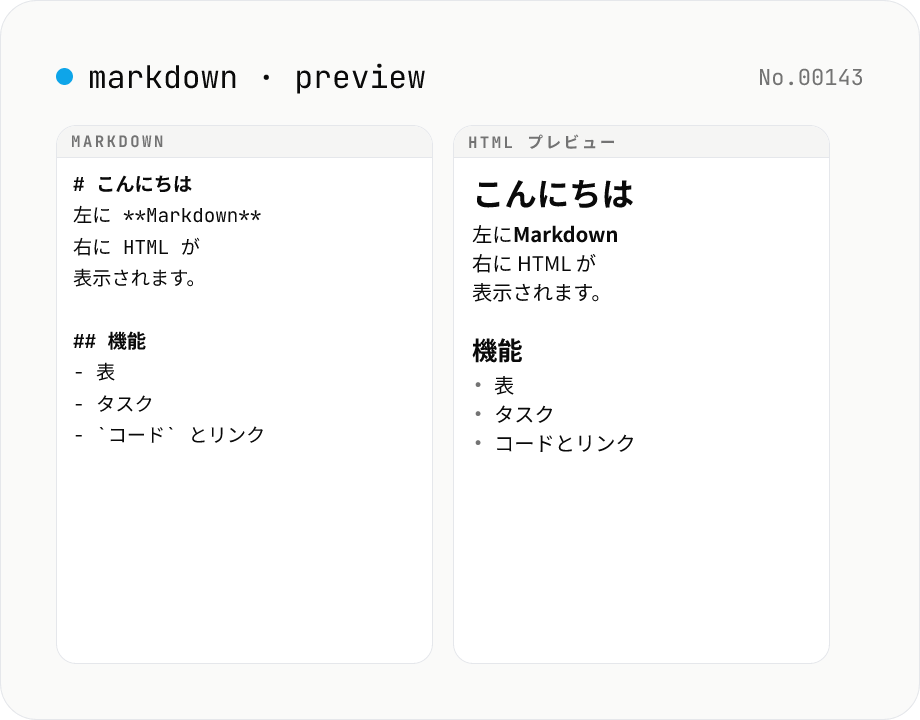
Markdown プレビュー — リアルタイムレンダリング
Markdown を入力すると、横並びでリアルタイムに HTML プレビューが表示されます。GFM (テーブル / タスクリスト / 自動リンク) と改行→<br> の変換に対応。レンダリングした HTML をコピー / ダウンロードできます。すべての処理はブラウザ内で完結します。
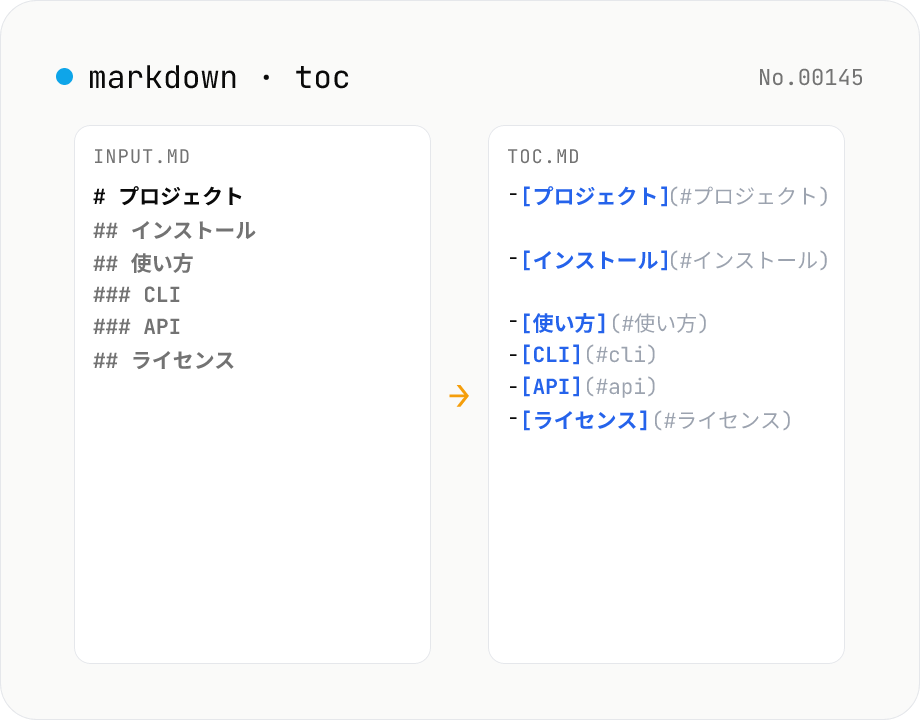
Markdown 目次生成 — 見出しから TOC を抽出
Markdown 文書の見出し (#, ##, …) を拾い上げ、GitHub 互換のアンカー付きリンクで目次 (TOC) を生成します。階層リスト / 平坦リスト、含める見出しの最大レベル、H1 の除外などを切替可能。コードフェンス内の `#` は自動で無視。結果は Markdown のコピーや .md ダウンロードで他のエディタにそのまま貼れます。すべてブラウザ内処理。
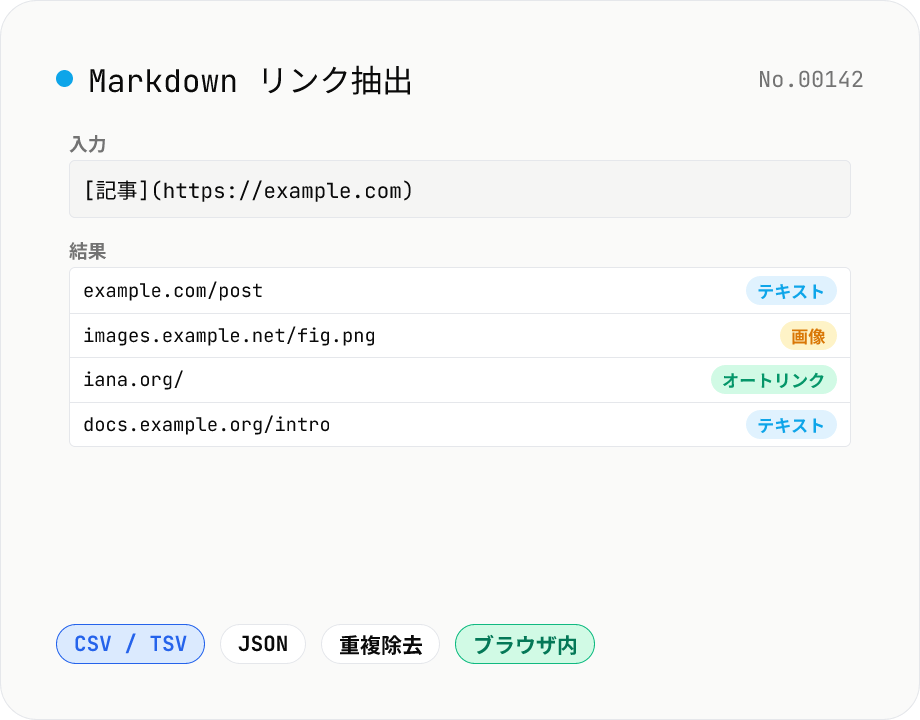
Markdown リンク抽出 — Markdown / HTML / テキストから URL を一括取得
Markdown / HTML / プレーンテキストから URL と Markdown / HTML リンクをまとめて抽出。`[label](url)` / `` / `<a href>` / `<img src>` / 生 URL の 5 種類を自動検出し、種類別 (テキスト / 画像 / オートリンク) に分類して一覧化します。重複除去・種類フィルター・ホスト別グルーピング・CSV / TSV / JSON エクスポートに対応。記事内のリンク監査、転載元の洗い出し、SEO 内部リンクの可視化、SNS 投稿時の参考リンク収集に便利。すべてブラウザ内で処理されます。

文字数カウント — 文字 / バイト / 行 / 単語
テキストの文字数・単語数・行数・段落数・UTF-8 バイト数をリアルタイムで集計。空白・改行を含めるか除くかを切り替え可能で、Twitter・原稿用紙 (400 字)・LINE などの文字数上限の進捗バーも同時表示。すべてブラウザ内で動くので、原稿や下書きを安全にカウントできます。