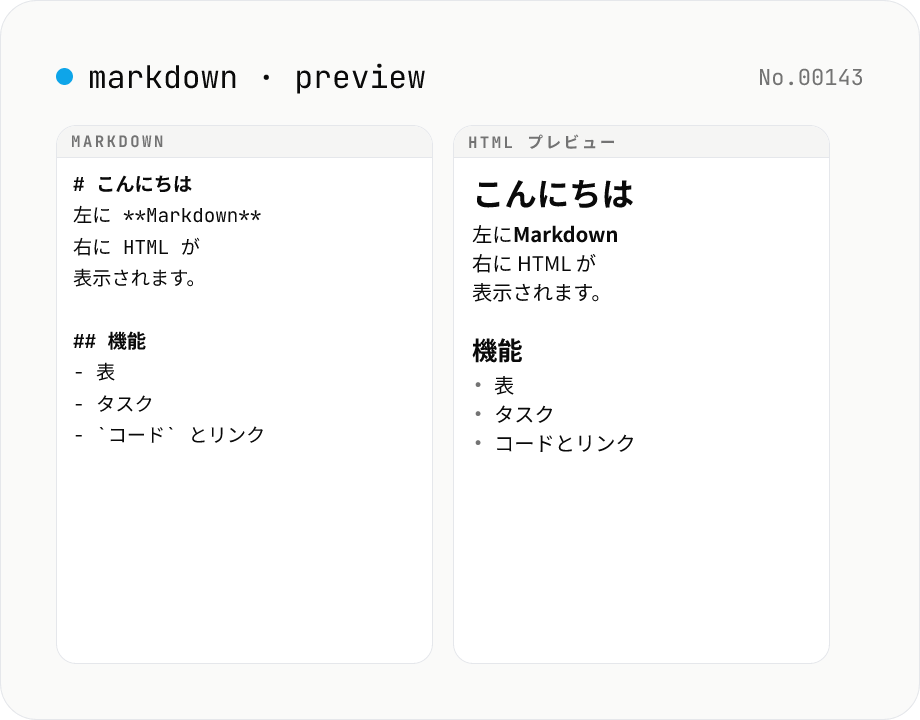
Markdown プレビュー — リアルタイムレンダリング
Markdown を入力すると、横並びでリアルタイムに HTML プレビューが表示されます。GFM (テーブル / タスクリスト / 自動リンク) と改行→<br> の変換に対応。レンダリングした HTML をコピー / ダウンロードできます。すべての処理はブラウザ内で完結します。
使い方
左の入力欄に Markdown を貼り付け、または入力します。右側のプレビュー欄にリアルタイムで HTML レンダリング結果が表示されます。デフォルトで GitHub Flavored Markdown (GFM) のテーブル / タスクリスト / 取り消し線 / 自動リンクが有効です。「改行を <br> に変換」を有効にすると、空行を挟まない単一の改行も <br> として描画されます (普通の Markdown は単一改行を空白として扱います)。レンダリングした HTML は「HTML をコピー」でクリップボードへ、「HTML をダウンロード」で .html ファイルとして保存できます。サンプルボタンで動作を試せます。
よくある質問
- 入力した Markdown はサーバーに送信されますか?
- いいえ。Markdown の解析と HTML レンダリングは marked ライブラリをブラウザ内で実行するだけで、入力データが外部に送信されることはありません。
- GFM (GitHub Flavored Markdown) の何に対応していますか?
- テーブル、タスクリスト ([x] / [ ])、取り消し線 (~~text~~)、自動リンク、フェンスドコードブロックに対応しています。チェックボックスを外すと標準の CommonMark 寄りの解釈に切り替わります。
- シンタクスハイライトは効きますか?
- コードブロックは <pre><code> としてプレーンに描画されます。サーバー / 外部 CDN へのアクセスを避けるため、ブラウザ内でのハイライト処理は組み込んでいません (このサイトのプライバシー方針です)。
- 画像やリンクは外部に送信されますか?
- Markdown 中の URL は HTML の <img src> / <a href> 属性として書き出されるだけで、レンダリング時にこのツールが取得することはありません。プレビュー欄で画像を実際に表示すると、お使いのブラウザがその URL にアクセスします (通常の Web ページと同じ挙動です)。
- Markdown 内の HTML / スクリプトはどう扱われますか?
- marked は Markdown を HTML に変換するだけで、JavaScript の実行は行いません。プレビュー欄は入力者本人のための表示なので raw HTML はそのまま描画されますが、外部に送信されるわけではないので安全です。第三者から受け取った Markdown を確認する用途では、ダウンロードした HTML を信頼できない環境で開かないでください。
- ダウンロードした HTML はそのまま使えますか?
- <body> 相当の本文だけが書き出されます。スタイルを付けて配布したい場合は、ご自分の HTML テンプレートの <body> 内に貼り付けてください。
類似のツール

Markdown ⇄ HTML 変換 — 双方向で往復
Markdown を HTML に、HTML を Markdown に双方向変換します。ブログから WordPress、静的サイトジェネレータへの移行、Web ページから README 化など、フォーマット間の橋渡しに最適。marked と turndown をブラウザ内で実行するので、原稿を外部に送信せずに変換できます。
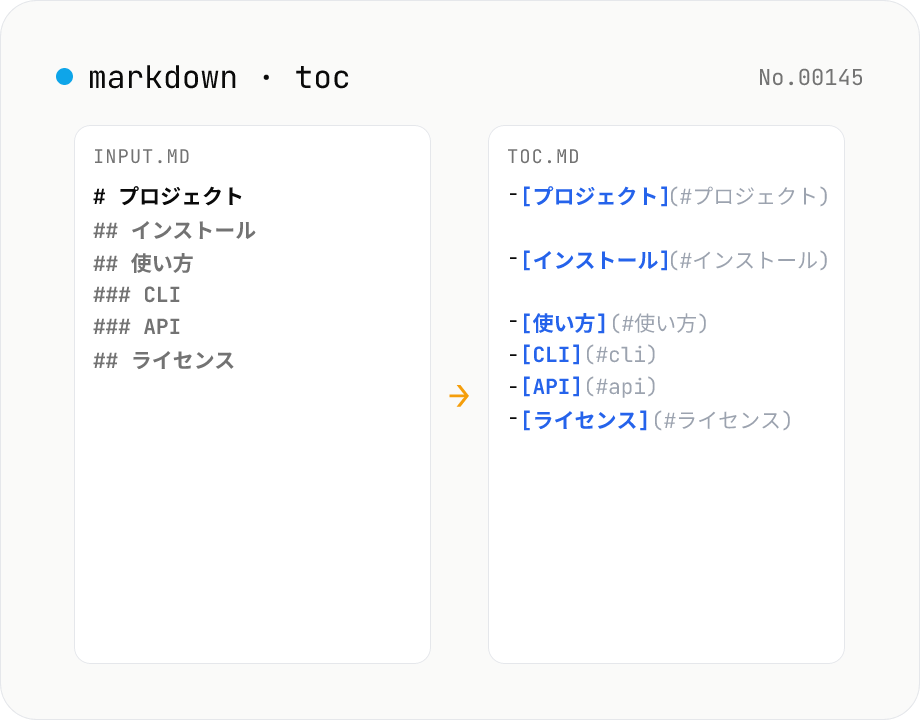
Markdown 目次生成 — 見出しから TOC を抽出
Markdown 文書の見出し (#, ##, …) を拾い上げ、GitHub 互換のアンカー付きリンクで目次 (TOC) を生成します。階層リスト / 平坦リスト、含める見出しの最大レベル、H1 の除外などを切替可能。コードフェンス内の `#` は自動で無視。結果は Markdown のコピーや .md ダウンロードで他のエディタにそのまま貼れます。すべてブラウザ内処理。
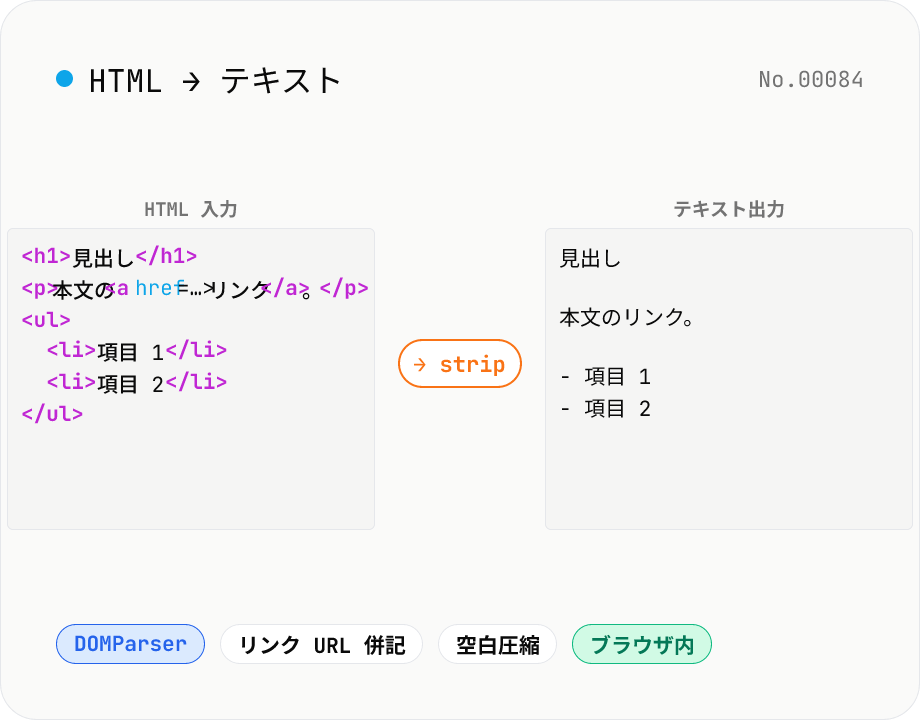
HTML → テキスト変換 — タグを剥がして可視テキストだけ抽出
HTML から script / style / noscript / コメントを除去し、可視テキストだけを取り出します。<p> や <h*>、<li>、<br> などのブロック要素は改行に展開され、リンクは「テキスト + URL 併記」も選択可能。連続空白の圧縮、HTML エンティティのデコード、箇条書きマーカー保持などのオプション。スクレイピング結果から本文だけ取りたい、NLP の前処理、メール本文の plain-text 化、記事のコピペ整形などに。すべてブラウザ内で処理されます。
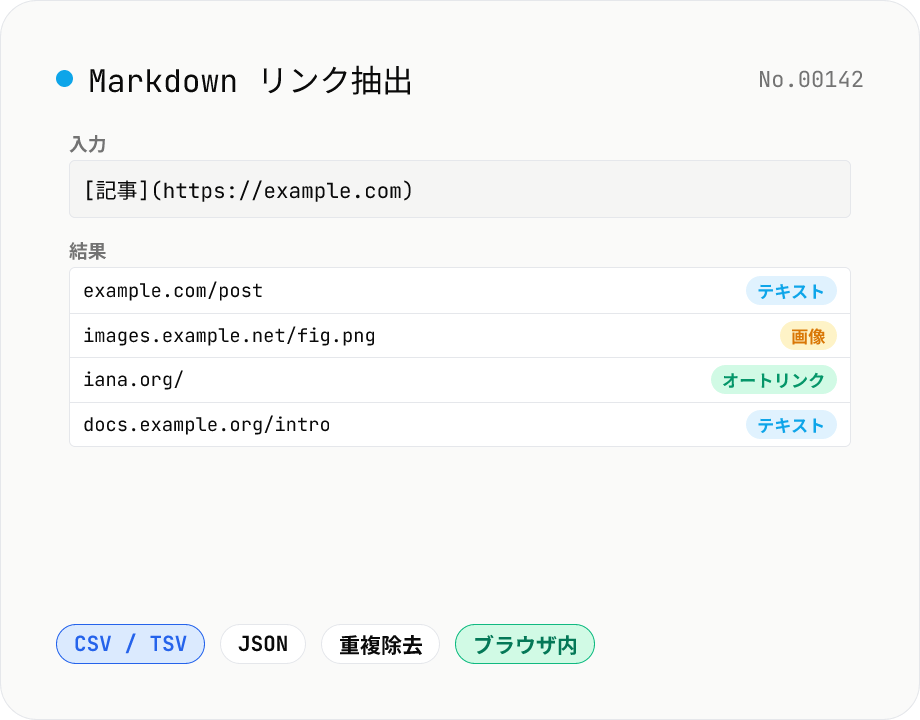
Markdown リンク抽出 — Markdown / HTML / テキストから URL を一括取得
Markdown / HTML / プレーンテキストから URL と Markdown / HTML リンクをまとめて抽出。`[label](url)` / `` / `<a href>` / `<img src>` / 生 URL の 5 種類を自動検出し、種類別 (テキスト / 画像 / オートリンク) に分類して一覧化します。重複除去・種類フィルター・ホスト別グルーピング・CSV / TSV / JSON エクスポートに対応。記事内のリンク監査、転載元の洗い出し、SEO 内部リンクの可視化、SNS 投稿時の参考リンク収集に便利。すべてブラウザ内で処理されます。