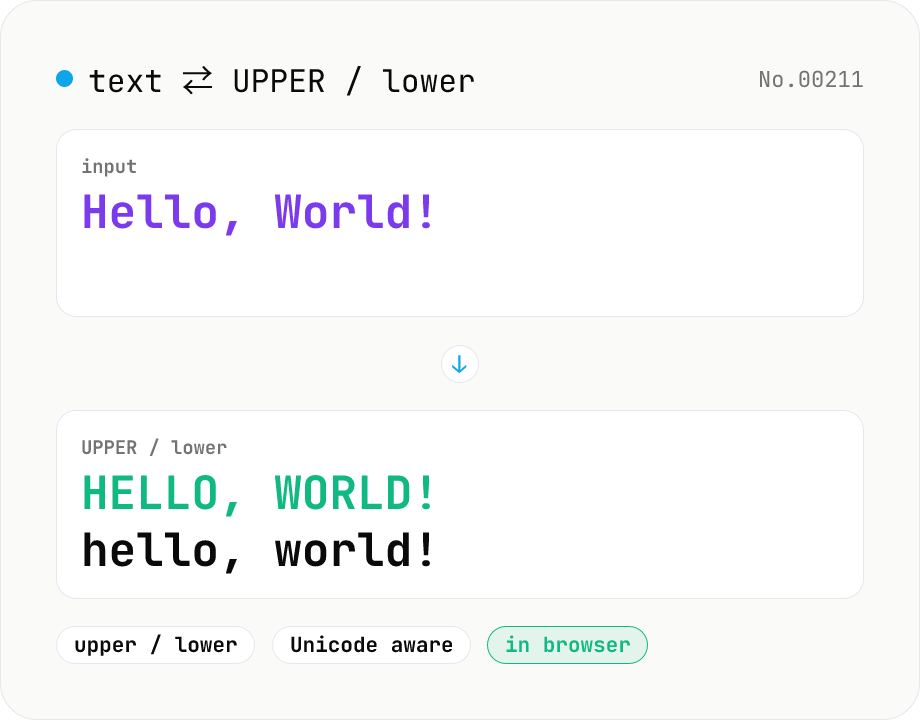
Text case — UPPERCASE / lowercase toggle
Convert text to all UPPERCASE or all lowercase, with a mode toggle. Unicode-aware so non-Latin scripts (Greek, Cyrillic, etc.) are handled correctly. Japanese, symbols, and digits pass through unchanged. Runs entirely in your browser.
How to use
Paste text, choose a mode (UPPERCASE or lowercase), and click Run. Internally we call JavaScript's `String.prototype.toUpperCase()` or `toLowerCase()`, which follow the Unicode case-mapping table. Latin letters (a–z ⇄ A–Z) of course, but also Greek (α ⇄ Α), Cyrillic (а ⇄ А), and other scripts are handled correctly. Japanese, emoji, symbols, and digits have no case and pass through unchanged. The output can be copied or downloaded as .txt.
FAQ
- Is text uploaded?
- No. `toUpperCase()` / `toLowerCase()` is handled by the JS engine — no network calls, and input/output never leave your browser.
- What happens to German ß?
- In UPPERCASE mode, ß (U+00DF) expands to SS per ECMAScript (`'ß'.toUpperCase() === 'SS'`). It's a legitimate case where one character becomes two — output length can exceed input length. The other direction is asymmetric: SS lowercases to ss, never collapsing back to ß.
- Does it handle Turkish dotted/dotless i correctly?
- No. We use locale-independent `toUpperCase()` / `toLowerCase()` rather than the `toLocale...` variants, so i always becomes I and I always becomes i — there is no Turkish-specific i → İ / ı → I / İ → i behavior.
- What happens when I switch modes?
- The mode is evaluated at conversion time, so after toggling the radio you need to click Run again to recompute. The stats row beneath the output also shows the active mode (uppercase / lowercase).
- What happens to Japanese and emoji?
- Characters with no case concept (hiragana, katakana, kanji, emoji, fullwidth symbols, digits, etc.) are preserved unchanged in both modes. Mixed-script text is safe to convert.
Related tools
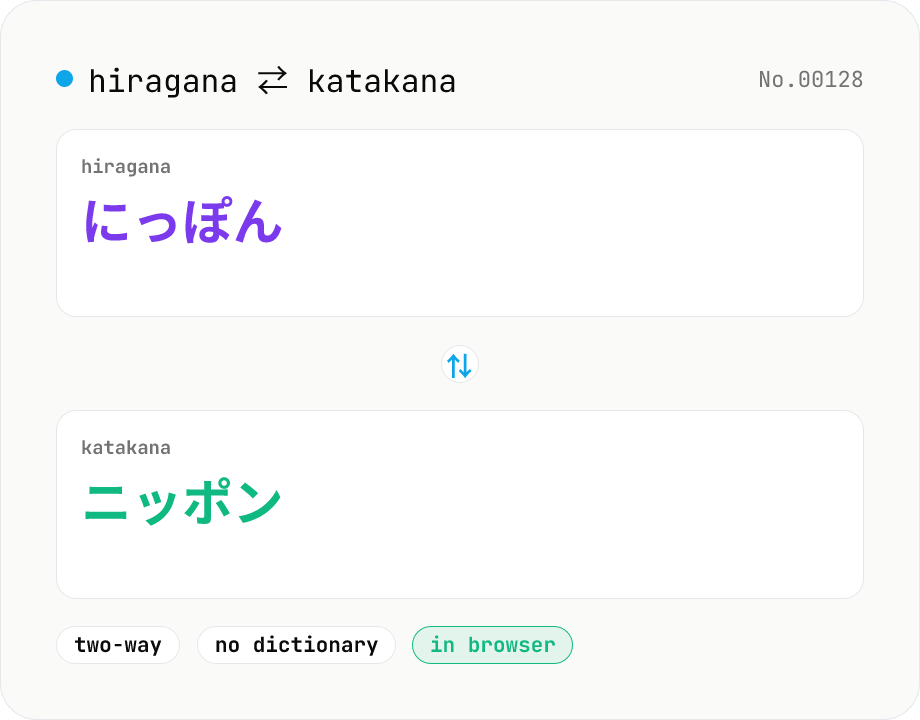
Hiragana ⇄ Katakana converter — bulk character mapping
Convert between hiragana and katakana with a single mode toggle. A purely mechanical per-character mapping — no dictionary download, instant conversion. Long-vowel mark, punctuation, kanji, and alphanumerics are preserved as-is. Runs entirely in your browser.
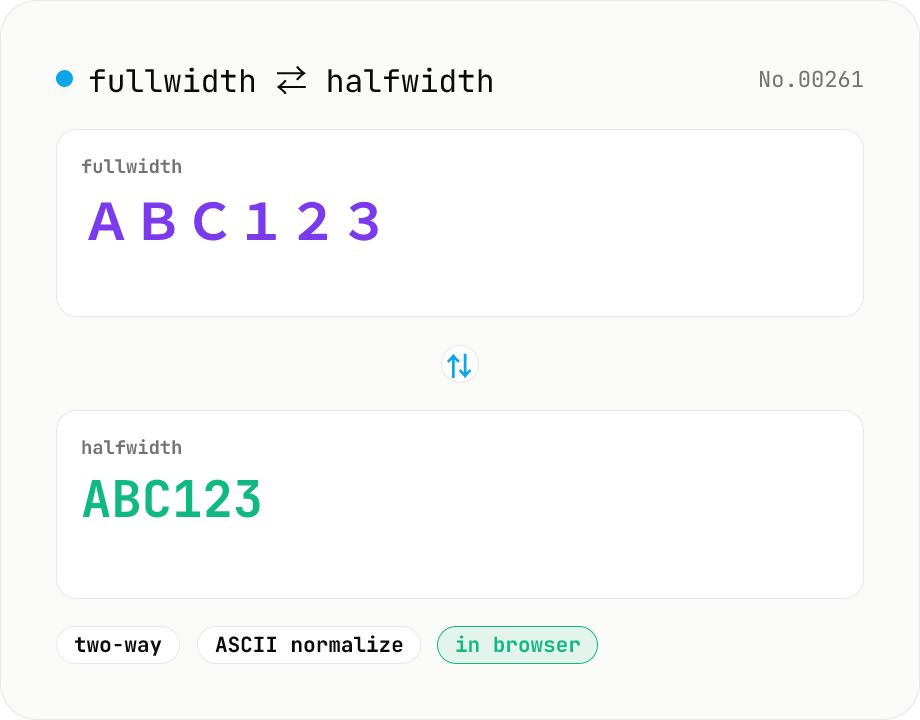
Fullwidth ⇄ Halfwidth converter — alphanumerics, kana, symbols
Convert between fullwidth ASCII (letters, digits, symbols) and halfwidth ASCII with a single mode toggle. Covers U+FF01–U+FF5E ⇄ U+0021–U+007E, plus the ideographic space U+3000 ⇄ ASCII space U+0020. Hiragana, katakana, and kanji are kept untouched. Runs entirely in your browser.

CSV / text encoding converter — Shift_JIS ↔ UTF-8 / BOM / newlines
Re-encode CSV and text files between Shift_JIS (CP932), UTF-8, UTF-16LE and EUC-JP — fix Excel's mojibake on UTF-8, hand UTF-8 text to legacy systems that need Shift_JIS, or add BOM so Excel reads UTF-8 correctly. Add / remove BOM, swap newlines (CRLF / LF / CR), and auto-detect the input encoding. Batch convert and grab the result as a ZIP. Files never leave your device — everything runs in the browser.
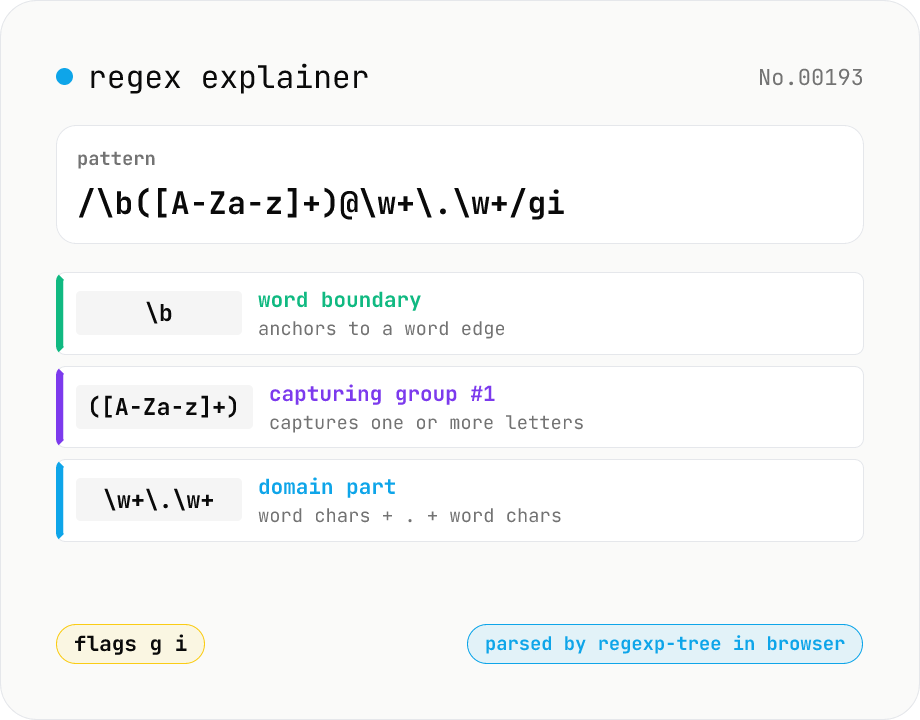
Regex explainer — AST tree with per-token English notes
Break down a JavaScript regular expression into its AST and explain each piece — character classes, quantifiers, groups, lookarounds, flags — in plain English. Comes with sample patterns for email, URL, and date so you can grok common regexes at a glance. Parsed with regexp-tree; syntax errors are shown verbatim. Runs entirely in your browser.