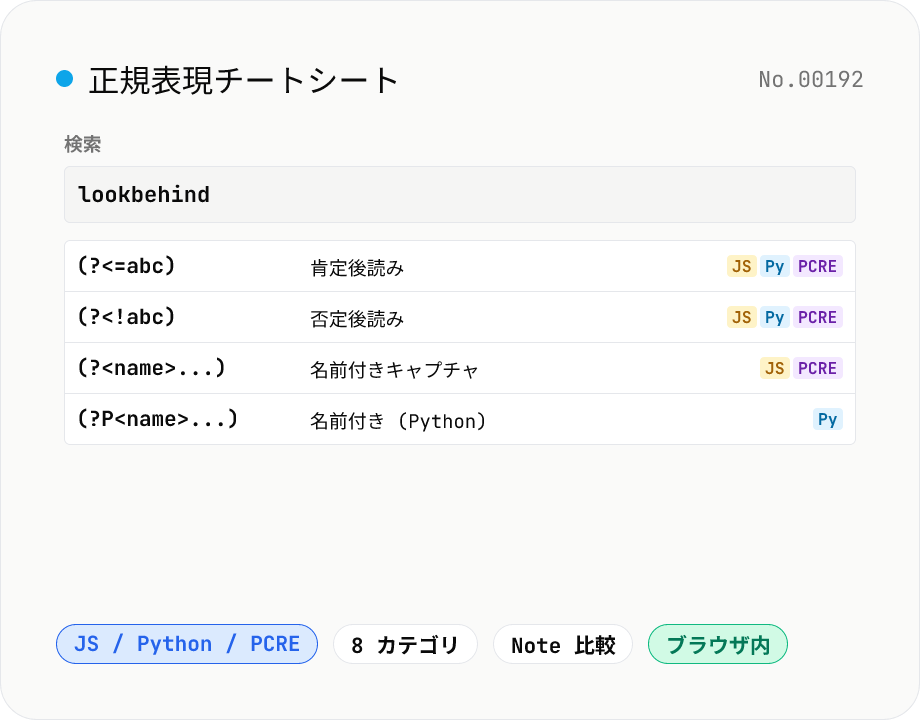
正規表現チートシート — JS / Python / PCRE の構文を検索
正規表現の構文を flavor (JavaScript / Python / PCRE) 別に一覧化したインタラクティブなチートシートです。カテゴリ (アンカー / 文字クラス / 量化子 / グループ / ルックアラウンド / フラグ) で絞り込み、自由テキスト検索、各エントリのコピーに対応。`\d` `(?<=...)` `(?P<name>...)` のように flavor で書き方が違うものを比較しながら確認できます。データはすべて組み込み、ブラウザ内で動作します。
使い方
Flavor (JS / Python / PCRE) を選びます。「すべて」を選ぶと flavor 関係なく全エントリが対象になります。 カテゴリで絞り込みます (アンカー / 文字クラス / 量化子 / グループ / ルックアラウンド / フラグなど)。 検索ボックスで構文・説明・例を自由テキスト検索できます (`\d`、`lookbehind`、`named` など)。 各行の構文をクリック (またはコピーボタン) でクリップボードへコピーできます。 Flavor 間で書き方が違うエントリには Note が付くので比較しながら使えます。
よくある質問
- 対応している flavor は?
- JavaScript (ECMAScript) / Python (re) / PCRE (Perl-compatible) の 3 つです。Go の `regexp` は RE2 ベースで PCRE のサブセットに近く、Rust の `regex` も同じく PCRE 系として参考にできます。
- 実際にパターンをテストしたい場合は?
- 正規表現テスター (regex-test) で動作確認できます。本ツールは構文のリファレンスに特化しており、実行は別ツールに任せます。
- なぜ Python は `(?P<name>...)` で JS は `(?<name>...)`?
- 歴史的な経緯です。Python 2 では `(?P<name>...)` だけがサポートされ、JS / PCRE は `(?<name>...)` を採用しました。Python 3.0 以降も後方互換のため `(?P<name>...)` が標準で、`(?<name>...)` を入れると SyntaxError になります。
- POSIX 文字クラス (`[[:alpha:]]`) はどこで使える?
- PCRE / Tcl / sed (GNU) / awk などの POSIX 系で使えます。JS / Python では非対応で、JS なら `\p{L}` (Unicode プロパティ)、Python なら `regex` モジュールで代替してください。
- データはどこかに送信されますか?
- いいえ。エントリは内蔵データで、検索もブラウザ内で完結します。
類似のツール
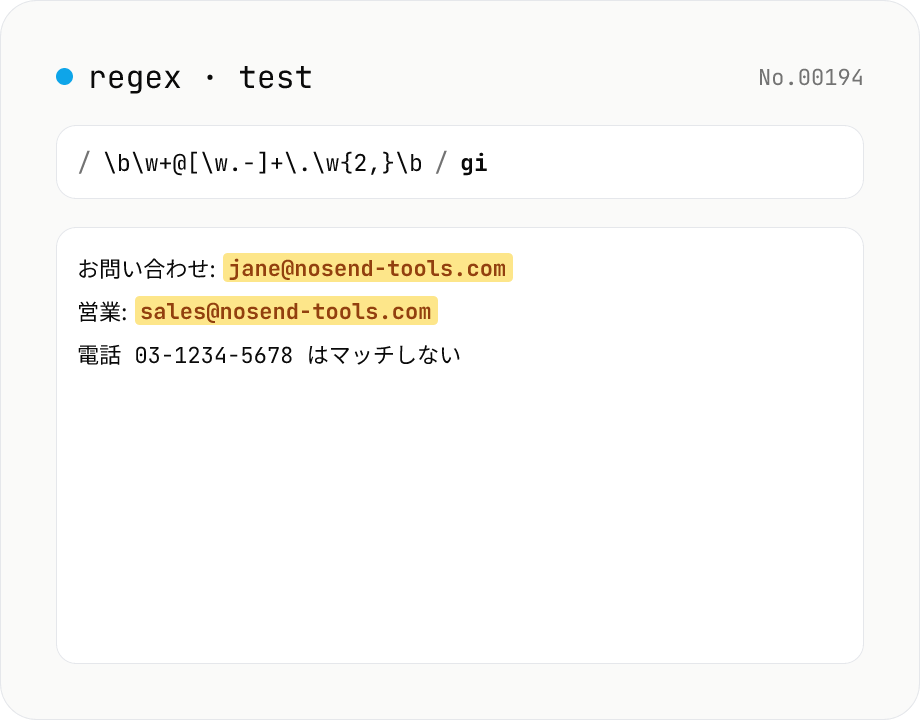
正規表現テスター — マッチ / 置換のリアルタイム確認
パターンとフラグを入力するとテキスト内のマッチ箇所をリアルタイムでハイライト。キャプチャグループ・名前付きグループの内容も一覧表示。$1 などを使った置換プレビューにも対応。すべてブラウザ内で処理。
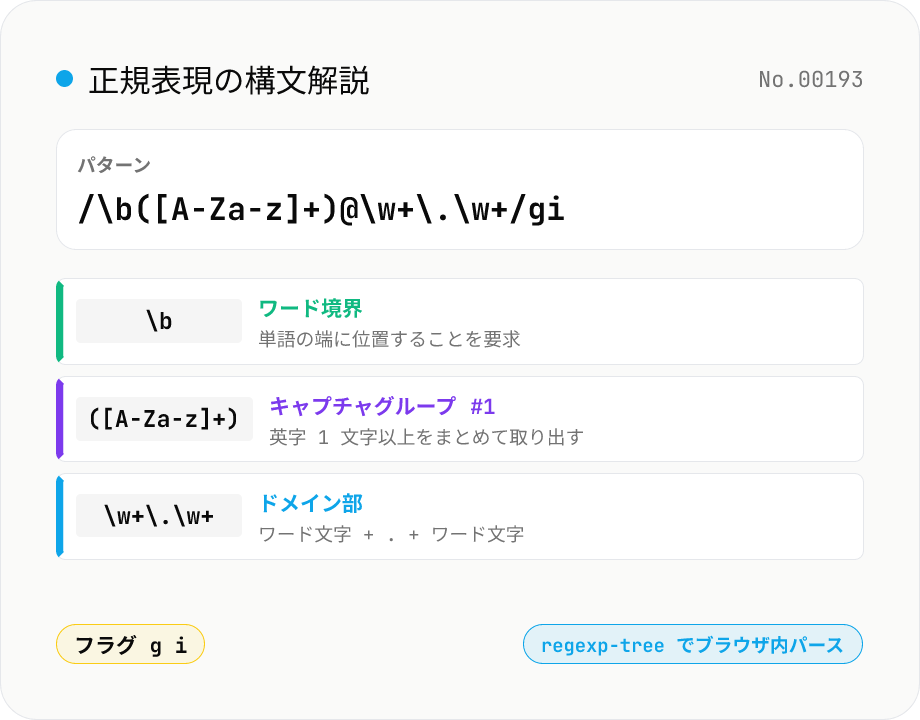
正規表現の構文解説 — 各パーツを日本語でツリー表示
JavaScript の正規表現を AST に分解し、文字クラス・量指定子・キャプチャグループ・先読み/後読み・フラグを日本語で 1 つずつ解説します。サンプル正規表現付きで、メールアドレス / URL / 日付などのよくあるパターンが瞬時に理解できます。regexp-tree でパースし、エラー位置もそのまま表示。入力はブラウザ内でだけ処理。

テキスト一括置換 — 正規表現 + 後方参照 ($1) 対応
テキスト中の文字列を一括置換。プレーン文字列のほか、正規表現 (大文字小文字を無視・複数行 (^$ を行ごと)・dot で改行も) + 後方参照 ($1 $2 / $<name>) に対応。改行は \n で入力可能、置換数も同時表示。すべてブラウザ内で処理。
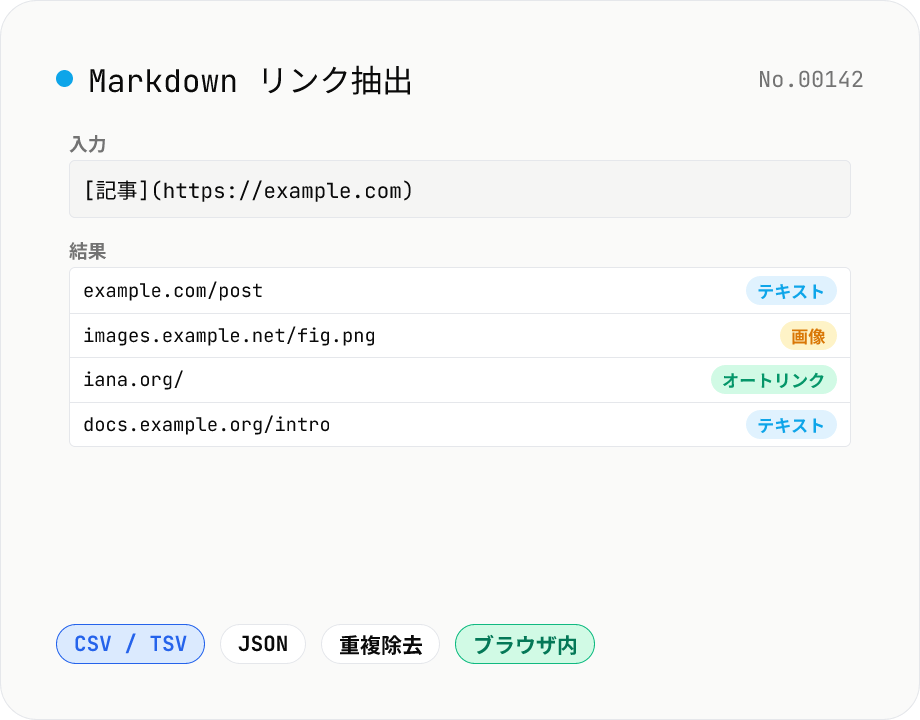
Markdown リンク抽出 — Markdown / HTML / テキストから URL を一括取得
Markdown / HTML / プレーンテキストから URL と Markdown / HTML リンクをまとめて抽出。`[label](url)` / `` / `<a href>` / `<img src>` / 生 URL の 5 種類を自動検出し、種類別 (テキスト / 画像 / オートリンク) に分類して一覧化します。重複除去・種類フィルター・ホスト別グルーピング・CSV / TSV / JSON エクスポートに対応。記事内のリンク監査、転載元の洗い出し、SEO 内部リンクの可視化、SNS 投稿時の参考リンク収集に便利。すべてブラウザ内で処理されます。