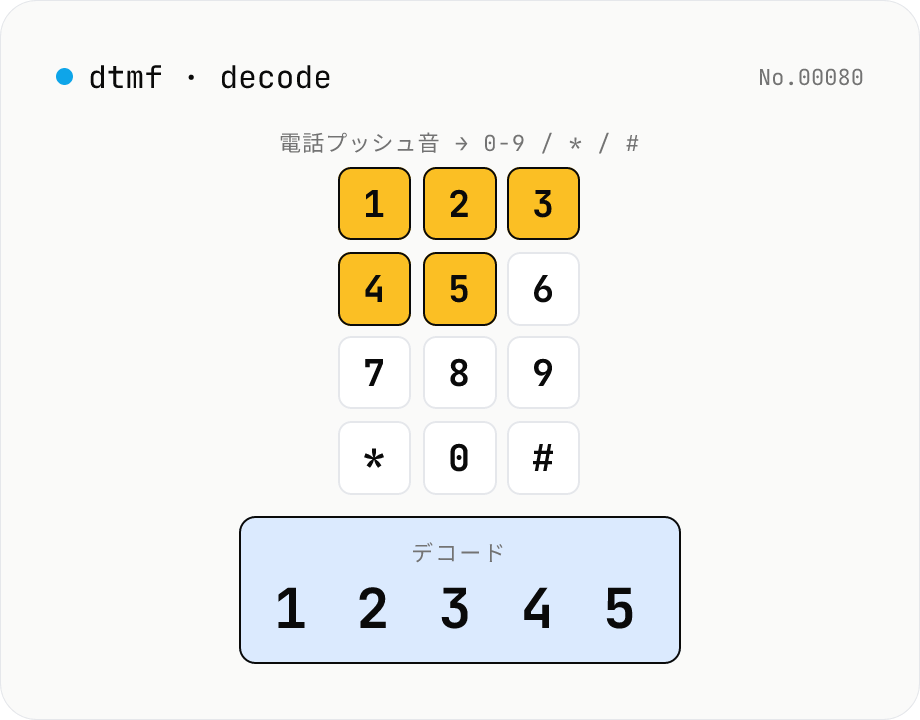
DTMF 音声デコーダ — 電話プッシュ音 WAV/MP3 → 0-9 / * / # / A-D
電話の **プッシュ音 (DTMF: Dual-Tone Multi-Frequency)** を録音した WAV / MP3 / OGG を読ませると、**Goertzel アルゴリズム** で 8 種の標準 DTMF 周波数 (697/770/852/941 Hz × 1209/1336/1477/1633 Hz) を検出し、**キーパッド 0-9 / * / # / A-D** の **16 シンボル** に復号。各トーンの **開始時刻 + 持続時間 + 信頼度** も出力。古い IVR (自動音声応答) の録音解析、レトロ電話システムの研究、CTF、Phreaking の学習用途に。**完全にブラウザ内** で処理 (Web Audio API)、音声ファイルはサーバーに送信されません。
使い方
**WAV / MP3 / OGG / FLAC / WebM** 形式の音声ファイルをドロップすると、(1) **Goertzel フィルタ** で 20ms 窓ごとに 8 種の DTMF 周波数 (697 / 770 / 852 / 941 Hz の low group × 1209 / 1336 / 1477 / 1633 Hz の high group) の magnitude を計算、(2) 各バンドの勝者と次点の比 (twist)、バンド合計エネルギーと総信号エネルギーの比 (energy ratio) で **トーン検出**、(3) low × high の組み合わせを **キーパッド 16 シンボル** (0-9, *, #, A-D) にマッピング、(4) 同じシンボルが続く区間を 1 つにまとめて **開始時刻 + 持続時間 + 信頼度** を出力。**サンプル読み込み** ボタンで `12345` を 100ms トーン + 60ms 無音の DTMF として in-tool 合成して動作確認可能。IVR (自動音声応答) の録音解析、CTF、phreaking 教材で。
詳細解説
DTMF 信号の復号が意味するもの — クレジットカード番号の歴史的文脈
DTMF (Dual-Tone Multi-Frequency) は電話のプッシュボタン音として 1963 年に AT&T が標準化した信号方式で、現在も IVR (自動音声応答) システムで「1 番を押してください」「暗証番号を入力してください」という用途で使われています。重要な文脈として、DTMF はクレジットカード番号や PIN の入力にも使われる歴史を持っています。電話回線録音の中に DTMF 音が含まれている場合、その復号結果は「誰かが電話で入力した数字列」そのものです。
この復号ツールの主な用途は IVR 録音の解析、CTF (Capture the Flag) パズル、アマチュア無線教材などですが、実際の電話録音に対して使う場合は、復号結果の内容に注意が必要です。電話番号や PBX 内線番号、アクセスコードなど、機密に相当する数字列が含まれている可能性があります。
電話録音・IVR 音声をクラウドで処理するリスク
DTMF 復号サービスをオンラインで提供しているケースは少ないですが、汎用的な音声解析サービスが DTMF 検出機能を持つ場合があります。電話録音 (IVR とのやり取りが入った音声) を外部サービスへ送ることは、通話内容そのものが第三者のサーバーへ届くことを意味します。DTMF トーンが含まれる録音では、再生した数字列 (電話番号・入力コード) が解析結果とともに外部に残ります。
通話録音は特に機微性が高い種類のデータです。金融機関やサポートセンターとのやり取りの録音は、個人情報・口座情報・取引内容を含むことがあります。「DTMF を解析したかっただけ」という目的でこうした録音を外部サービスへ送ることは、意図しない情報提供になりかねません。
Goertzel フィルタが AudioContext.decodeAudioData でブラウザ内復号
このツールは音声ファイルを Web Audio API の `AudioContext.decodeAudioData` でローカルにデコードし、20ms 窓ごとに Goertzel アルゴリズムで DTMF の 8 周波数 (低域グループ 697 / 770 / 852 / 941 Hz × 高域グループ 1209 / 1336 / 1477 / 1633 Hz) の magnitude を計算します。FFT と比較して特定の K 周波数のみを効率的に計算できる Goertzel アルゴリズムは、DTMF の固定 8 周波数に最適です (FFT より約 10 倍高速)。Twist 比 (勝者 / 次点 ≥ 4 倍) とエネルギー比 (8 バンド合計 ≥ 信号全体の 10%) の両方を満たしたときのみトーンあり判定します。
すべての処理がブラウザのメモリ内で完結します。DevTools の Network タブを開いてファイルをドロップしても、ページロード後の音声関連リクエストはゼロです。Goertzel の実装と判定ロジックは GitHub で公開されています。
実際の電話録音に対して使う際の注意事項
IVR 録音の解析、CTF 問題の解読、アマチュア無線の学習など、適切な文脈での利用には有用なツールです。実際の電話通話録音に対して使う場合は、復号される数字列の内容に注意してください。電話番号、PIN、アクセスコード、クレジットカード番号の断片など、機密に相当する情報が含まれる可能性があります。復号結果のスクリーンショットの扱いや、結果データの保存については注意が必要です。
このツール自体は復号結果を外部に送信しませんが、復号した数字列を他のツールやサービスに貼り付ける際には、その数字列が何を表しているかを意識してください。DTMF 復号のためにブラウザ内で完結させる意味は、「復号結果も外に出さずに済む」という点にもあります。
よくある質問
- 入力データはサーバーに送信されますか?
- いいえ。すべてブラウザ内で完結します。`AudioContext.decodeAudioData` で音声をローカル解析するだけで、外部 API も使いません。
- DTMF って何ですか?
- **Dual-Tone Multi-Frequency** = 電話のプッシュボタン (タッチトーン) で生成される **2 つの正弦波を重ね合わせた音**。電話機の **行** (697 / 770 / 852 / 941 Hz) と **列** (1209 / 1336 / 1477 / 1633 Hz) から 1 つずつ選んで重ねます。例: ボタン `5` = 770 Hz + 1336 Hz。1963 年に AT&T が標準化、ITU-T Q.23 / Q.24 で国際規格化。今でも IVR (Press 1 for English) や FAX や古い電話システムで現役。
- なぜ Goertzel アルゴリズム?
- **FFT** が任意の N 周波数すべての magnitude を計算するのに対し、**Goertzel** は **特定の K 周波数のみ** を高速に計算できる ($O(NK)$ ですが K=8 で済む)。DTMF は **8 周波数固定** なので Goertzel が理想的。1 フレーム 20 ms (sample rate 44.1 kHz で約 880 サンプル) ごとに 8 回計算 → 結果から勝者を選ぶ。FFT 経由より 10 倍以上高速。
- 16 シンボルのマッピングは?
- 標準キーパッドは: `1 2 3 A` (low 697 Hz)、`4 5 6 B` (770 Hz)、`7 8 9 C` (852 Hz)、`* 0 # D` (941 Hz) — 各列が 1209 / 1336 / 1477 / 1633 Hz。**A B C D** は軍用 / 業務用無線でのみ使われ、家庭用電話機にはありません (普通は 12 ボタン)。本ツールは A-D も含めて検出します (CTF・教育用途で出現)。
- 検出精度のしきい値は?
- **(1) Twist (勝者対 / 次点比)**: 勝者周波数の magnitude が次点より **4 倍以上** ある (`magnitudeMax / magnitudeRunnerUp > 4`)。これにより 1 周波数だけ強くなる単一トーンや音声を排除。**(2) Energy ratio**: 8 バンドの magnitude 合計が総信号エネルギーの **10% 以上**。これにより無音や雑音だけを排除。両方を満たすと「DTMF トーンあり」と判定。confidence は 0-1 で表示。
- MIN_TONE_MS = 40ms の意味は?
- **ITU-T Q.24** で DTMF の最小トーン長は **40 ms** と規定されています。本ツールも 40ms 未満の検出はノイズと判定して破棄。電話交換機が確実に認識するには **65 ms 以上 + 65 ms 無音** が推奨ですが、IVR 機器が独自にもっと短いトーンを送る場合もあるため、本ツールは ITU-T 下限の 40ms を採用。
- 音声形式の対応は?
- **ブラウザの `AudioContext.decodeAudioData` が読める形式すべて** (WAV / MP3 / OGG Vorbis / FLAC / WebM Opus / AAC)。最大 30 MB / ファイル。実用では 10-60 秒の IVR 録音を想定しています。長尺の連続電話通話は streaming decode が必要なので別途リクエストください。
- ノイズの多い実音源は?
- **SNR > 15 dB** (DTMF が背景ノイズより 15 dB 以上大きい) なら大抵検出可能。録音時に AGC (Auto Gain Control) で歪んだ音声、強い音楽の同時再生、Speex / OPUS の低ビットレート圧縮 (8 kbps 以下) などで失敗する可能性。ITU-T が定める「電話品質」(8 kHz サンプリング 64 kbps) なら本ツールで十分認識します。
- morse-decode-audio との違いは?
- **morse-decode-audio**: モールス信号 (`.` `-` の 単一周波数 ON/OFF) を envelope detection で復号。**本ツール (dtmf-decode-audio)**: DTMF (2 周波数同時) を Goertzel で復号。**入力データ型は同じ (音声ファイル)、復号アルゴリズムが違う** ため別ツールとしています。両方とも `audio-tone-detect` の派生として位置付け。
「送らない」を確かめるには
このツールは入力データを外部に送信しません。仕組み・監査手順・運営方針は以下で詳しく説明しています。
類似のツール
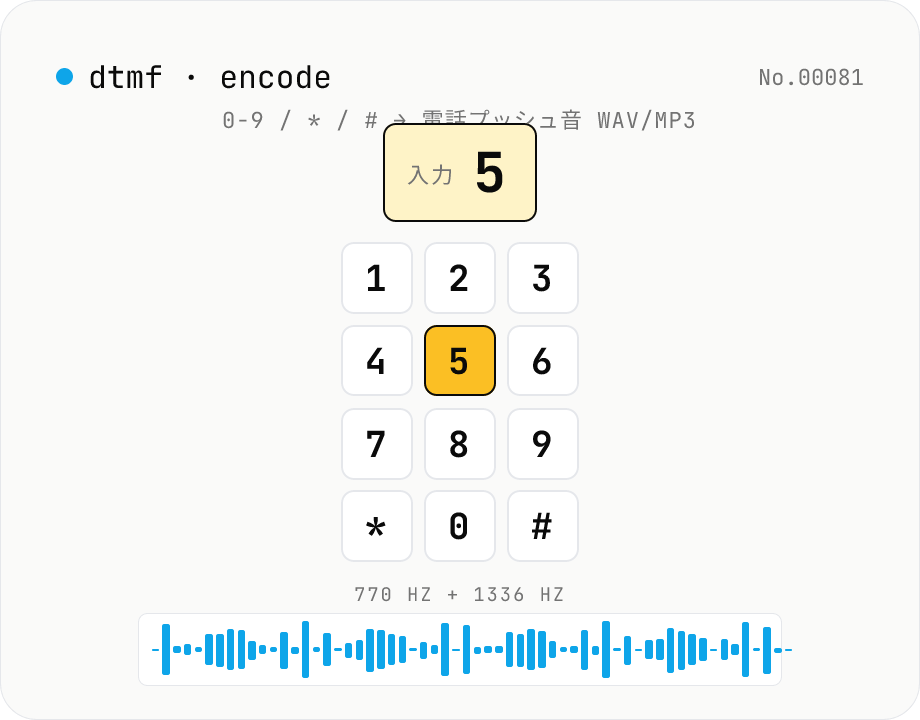
DTMF 音声エンコーダ — 0-9 / * / # / A-D → 電話プッシュ音 WAV/MP3
電話の **プッシュ音 (DTMF: Dual-Tone Multi-Frequency)** を **任意のキー列** から合成して **WAV / MP3** で書き出します。**16 シンボル** (0-9 / * / # / A-D) を **行 (697/770/852/941 Hz) × 列 (1209/1336/1477/1633 Hz)** の **2 周波数加算合成** で生成、**トーン長 / 間隔 / 音量 / サンプルレート (8/22.05/44.1/48 kHz)** を調整可能。**プレビュー再生** で確認してから WAV (16-bit PCM) / MP3 (lamejs) でダウンロード。**dtmf-decode-audio** の対称ペア — IVR 自動応答のテスト音源、CTF の問題作成、レトロ電話システム研究、phreaking 教材の動作確認に。**完全にブラウザ内** で合成し、入力テキストもサーバーに送信されません。
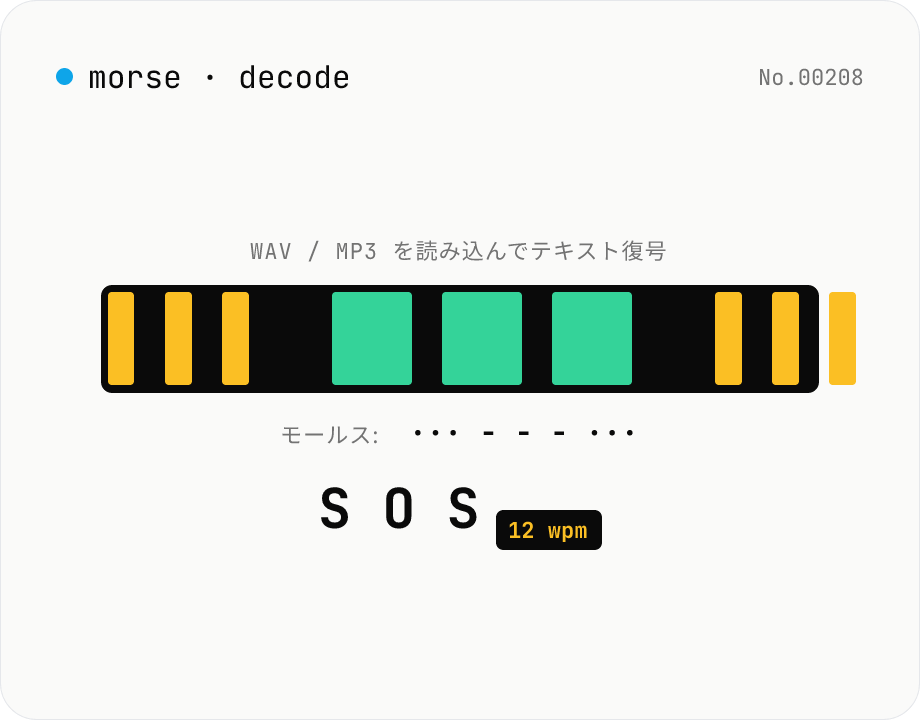
モールス音声デコーダ (WAV/MP3 → ドット・ダッシュ → テキスト)
モールス信号を吹き込んだ **WAV / MP3 / OGG** オーディオファイルをアップロードすると、**音量エンベロープ検出 → 自動しきい値 (Otsu) → on/off セグメント → ドット/ダッシュ判定 → モールス文字列 → テキスト** の流れで自動デコード。**WPM (Words Per Minute) も推定**。CW (Continuous Wave) 練習音源、ハム無線の練習問題、サバイバル/CTF/教育用 SOS 信号の読解で活躍。**完全にブラウザ内** で処理 (Web Audio API)、音声ファイルはサーバーに送信されません。
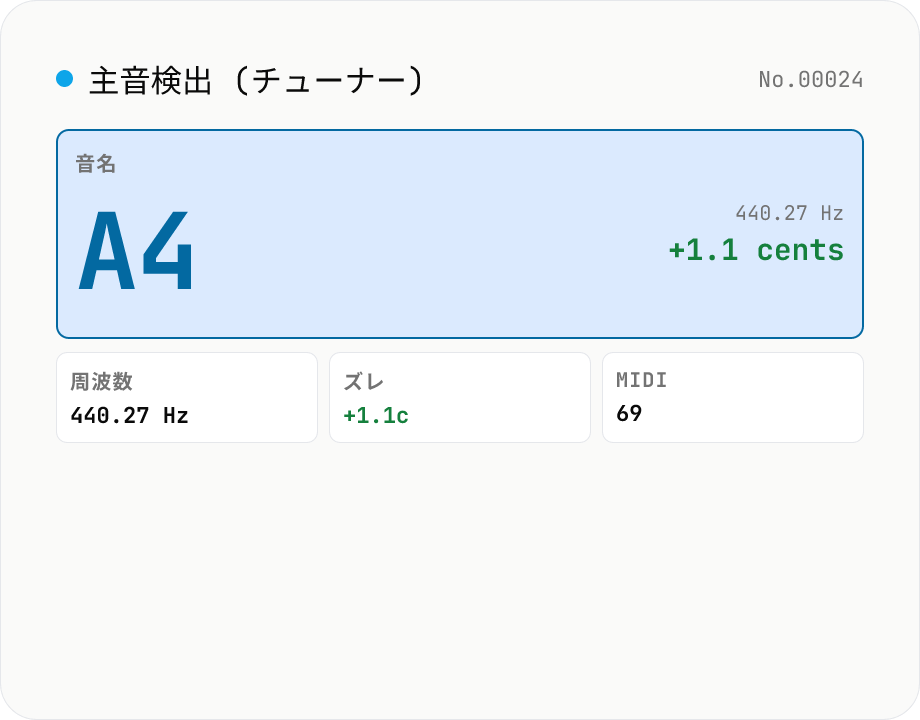
音声 主音検出 (チューナー) — FFT autocorrelation で音名 + cents ズレを表示
音声ファイルをドロップすると、ブラウザ内で **autocorrelation (自己相関) ベースのピッチ検出** を実行し、主音 (fundamental frequency) を **音名 (例: A4 / F#4)** と **cents 単位のズレ** に変換して表示します。**ギター / ベース / ボーカル / 笛 / ホイッスル** の楽器チューナー代わりに、録音した A 音 + 12 セント等を即座に確認できます。さらに **時間軸での主音遷移グラフ** を CSV 出力できるので、ボイスメモのピッチ追従 (intonation 練習) や、シンセサイザーで作った 1 トーンのチューニング微調整に。autocorrelation は短いトーン (50ms+) で高精度、複合音 (和音 / コーラス) は誤検出することがあります。`tone-generate` (任意の周波数のトーンを生成) の対称ツールで、本ツールは **既存音声 → 音名検出** に特化。`audio-spectrum` (周波数分布の可視化) とは異なり、主音 1 つに絞った出力。音声はサーバーに送信されません。
音声スペクトラム解析 — 周波数成分を可視化
音声ファイル (MP3 / WAV / M4A / FLAC / OGG / Opus) をドロップすると、ブラウザ内で FFT 解析を行い周波数スペクトルを可視化します。Mode 切替で、全体の平均スペクトル (周波数 vs 振幅) と、時間軸付きのスペクトログラム (時間 × 周波数 × 振幅) を切り替え可能。FFT サイズ (512 / 1024 / 2048 / 4096) と周波数軸 (Linear / Log) を選べます。マスタリング前のローエンド確認、ノイズ帯域の特定、楽器の倍音構成のチェック、講義音声の S/N 確認などに。Canvas を PNG ダウンロード、平均スペクトルは CSV エクスポート対応。音声はすべてブラウザ内で処理され、サーバーには送信されません。